KNN算法思想與應(yīng)用例子
這篇文章是在學習KNN時寫的筆記�,所參考的書為《機器學習實戰(zhàn)》�,希望深入淺出地解釋K近鄰算法的思想,最后放一個用k近鄰算法識別圖像數(shù)字的例子���。
KNN算法也稱K近鄰����,是一種監(jiān)督學習算法,即它需要訓練集參與模型的構(gòu)建���。它適用于帶標簽集的行列式(可理解為二維數(shù)組)的數(shù)據(jù)集����。
需要準備的數(shù)據(jù)有:訓練數(shù)據(jù)集����,訓練標簽集(每個數(shù)據(jù)與每個標簽都一一對應(yīng))用于參與模型構(gòu)建;
需要測試的數(shù)據(jù)集——通過這個模型得出——標簽集(每個數(shù)據(jù)對應(yīng)的標簽)
舉個例子:我們把人體的指標量化���,比如體重多少��,三圍多少,脂肪比例多少�,然后這個標簽就是性別(男或女)。我們的訓練數(shù)據(jù)集就是500個男性和500個女性的身體指標����,每個數(shù)據(jù)對應(yīng)性別標簽(男或女),這個就是訓練標簽集����。然后我們輸入一個人的指標���,模型給出一個性別的判斷,這個就是輸出的標簽集����,也就是最后的預(yù)測結(jié)果。
算法的流程為:
1���、計算輸入測試數(shù)據(jù)與訓練數(shù)據(jù)集的距離�����,這里用歐式距離來計算�。
2�����、根據(jù)得到的距離大小����,按升序排序
3��、取前K個距離最小的數(shù)據(jù)集對應(yīng)的標簽
4、計算這些標簽的出現(xiàn)頻率
5����、取出現(xiàn)頻率最高的標簽作為輸入的測試數(shù)據(jù)的最后的標簽,即預(yù)測結(jié)果
其中��,歐式距離的計算公式如下: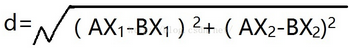
這個公式怎么理解呢����?假設(shè)輸入的被測數(shù)據(jù)為A,它有兩個維度(或者說字段)����,分別是AX-1和AX2。B為訓練數(shù)據(jù)集�����,同理也有兩個維度�,BX-1和BX2和,所以以上的計算公式即不同維度的差的平方的和的開方���。
下面直接貼上代碼�,每一段都附有注釋�,希望童鞋們可以通過理解代碼的執(zhí)行來掌握整個KNN算法的流程�����。
# KNN算法主程序
def knnmain(inX,dataset,labels,k): #輸入量有(被測數(shù)據(jù)����,訓練數(shù)據(jù)集����,訓練標簽集,K值)�����,輸入量皆為數(shù)組形式
datasetsite=dataset.shape[0] #取訓練數(shù)據(jù)集的總數(shù)量n
inXdata=tile(inX,(datasetsite,1)) #將被測數(shù)據(jù)的數(shù)組復制為n行相同數(shù)組組成的二維數(shù)組���,方便下面的歐式距離計算
sqdistance=inXdata-dataset #開始計算歐式距離,這里計算被測數(shù)據(jù)和訓練數(shù)據(jù)集之間相同維度的差
distance=sqdistance**2 #計算差的平方
dist=distance.sum(axis=1) #計算不同維度的差的平方的總和
lastdistance=dist**0.5 #將總和開方
sortnum=lastdistance.argsort() #返回從小到大(增序)的索引值
countdata={} #創(chuàng)建一個空字典用于儲存標簽和對應(yīng)的數(shù)量值
for i in range(k):
vlabels=labels[sortnum[i]] #將前k個距離最近的數(shù)據(jù)的標簽傳給vlabels
countdata[vlabels]=countdata.get(vlabels,0)+1 #vlabels作為字典的鍵,而其出現(xiàn)的次數(shù)作為字典的值
sortnumzi=sorted(countdata.iteritems(),key=operator.itemgetter(1),reverse=True) #將字典按值降序排序,即第一位是出現(xiàn)次數(shù)最多的標簽
return sortnumzi[0][0] #返回出現(xiàn)次數(shù)最多的標簽值
整個KNN算法的核心思想是比較簡潔的����,下面貼一個手寫數(shù)字識別的應(yīng)用�。
一個文本文檔里儲存一個32*32的由1和0組成的圖像���,差不多是下圖所示:

我們大概能識別出第一個圖片里是0�,第二個圖片里是1���,實際上每個文本文檔都有一個文檔名,如第一個圖片的文檔名就是"0_0.txt"�,那么我們就可以從文檔名里取得該圖片的標簽����。我們有一個訓練文件夾�����,里面的文檔文件可以獲取并構(gòu)成訓練數(shù)據(jù)集和訓練標簽集�。
我們也有一個測試文件夾���,同理里面的文檔文件也可以獲取并構(gòu)成測試數(shù)據(jù)集和測試標簽集(拿來與預(yù)測結(jié)果做對比)��。文件夾截圖如下:
下面直接貼上代碼幫助理解
先是一個將32*32的文本文檔轉(zhuǎn)化為1*1024的程序,因為我們寫的KNN算法主程序是以一行為單位的���。
def to_32(filename):
returnoss=zeros((1,1024))
ma=open(filename)
i=int(0)
for line in ma.readlines():
for j in range(32):
returnoss[0,i*32+j]=line[j]
i += 1
return returnoss
下面是手寫數(shù)字識別程序:
def distinguish():
filestrain=listdir('trainingDigits') #打開訓練集文件夾
filestest=listdir('testDigits') #打開測試集文件夾
mtrain=len(filestrain) #訓練集文件數(shù)量
mtest=len(filestest) #測試集文件數(shù)量
allfilestrain=zeros((mtrain,1024)) #m行1024列的矩陣
allfilestest=zeros((mtest,1024))
labelstrain=[] #創(chuàng)造一個空列表用于儲存試驗向量的標簽
labelstest=[]
for i in range(mtrain):
nametrain=filestrain[i] #選取文件名
inX=open('trainingDigits/%s' % nametrain)
allfilestrain[i,:]=to_32(inX) ##把每個文件中的32*32矩陣轉(zhuǎn)換成1*1024的矩陣
label1=nametrain.split('.')[0]
label1=int(label1.split('_')[0]) #獲取每個數(shù)據(jù)的標簽
labelstrain.append(label1) #將所有標簽合成一個列表
for j in range(mtest):
nametest=filestest[j]
inY=open('trainingDigits/%s' % nametest)
allfilestest[j,:]=to_32(inY)
label2=nametest.split('.')[0]
label2=int(label2.split('_')[0])
labelstest.append(label2)
labelstrain=np.array(labelstrain)
labelstest=np.array(labelstest)
grouptrain=allfilestrain
grouptest=allfilestest
error=0.0 #初始化判斷錯誤率
results=[]
for line in grouptest:
result=knnmain(line,grouptrain,labelstrain,3)
results.append(result)
errornum=0 ##初始化判斷錯誤數(shù)量
print 'the wrong prodiction as:'
for i in range(mtest):
if results[i] != labelstest[i]:
print 'result=',results[i],'labelstest=',labelstest[i] #輸出所有判斷錯誤的例子
errornum +=1
print 'the errornum is:',errornum #輸出判斷錯誤量
print 'the allnum is:',mtest #輸出總測試量
error=float(errornum/float(mtest))
print 'the error persent is:',error #輸出總測試錯誤率
該程序運行截圖如下:
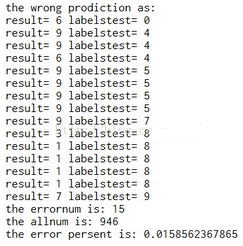
我們看到錯誤率是比較低����,說明該算法的精度是很高的���。
結(jié)語:從上面例子的應(yīng)用來看�����,KNN算法的精度是很高����,但是對噪聲有些敏感����,我們觀察上面的運行結(jié)果��,凡是判斷失誤的一般是兩個數(shù)字長得比較像�����,比如9和5�����,下面的勾很像��,9和7,也是比較像的����,也就是說���,假如測試的數(shù)據(jù)有些偏于常態(tài)�����,可能一個7長得比較歪,那就判斷為9了,這些都是噪聲���,它對這些噪聲的數(shù)據(jù)是無法精準識別的,因為k值較小����,下面會說到k值得取值問題。另有,它的計算相對復雜�����,若對象數(shù)據(jù)集巨大�,則計算量也很大。當然����,最重要的一點���,對k值的把握很重要,這一般是根據(jù)具體情況來判斷�����,較大的k值能減少噪聲干擾��,但會使分類界限模糊��,較小的k值又容易被噪聲影響��。一般取一個較小的k值��,再通過交叉驗證來選取最優(yōu)k值�。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認證考試�����,點擊>>>
“CDA報名”
了解CDA考試詳情����;
? 想學習CDA考試教材����,點擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫���,點擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量��,點擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330