盤點機器學習中那些神奇的損失函數(shù)
我最近在學習R語言,但是估R語言我應(yīng)該沒能跟sas一樣玩那么好���。今天來更新在機器學習中的一些專業(yè)術(shù)語�����,例如一些損失函數(shù)���,正則化����,核函數(shù)是什么東西����。
損失函數(shù):損失函數(shù)是用來衡量模型的性能的,通過預(yù)測值和真實值之間的一些計算�,得出的一個值,這個值在模型擬合的時候是為了告訴模型是否還有可以繼續(xù)優(yōu)化的空間(模型的目的就是希望損失函數(shù)是擬合過的模型中最小的)���,損失函數(shù)一般有以下幾種,為什么損失函數(shù)還有幾種呢�,因為不同的算法使用的損失函數(shù)有所區(qū)分。
1
0-1損失函數(shù):
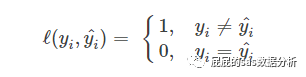
這個損失函數(shù)的含義�,是最簡單的,預(yù)測出來的分類結(jié)果跟真實對比����,一樣的返回1,不一樣返回0,這種方式比較粗暴�,因為有時候是0.999的時候,其實已經(jīng)很接近了��,但是按照這個損失函數(shù)的標準,還是返回0�,所以這個損失函數(shù)很嚴格,嚴格到你覺得特別沒有人性�。
2
感知損失函數(shù)
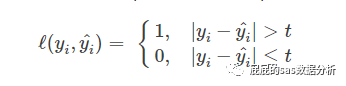
那么這個感知損失函數(shù),其實是跟混淆矩陣那種算法是一樣�����,設(shè)定一個閥值��,假設(shè)真實值與預(yù)測值之間的差距超過這個閥值的話�����,就是1���,小于的話就是0���,這種就多多少少彌補了0-1損失函數(shù)中的嚴格,假設(shè)以0.5為界限�,那么比0.5大的我們定義為壞客戶,小于0.5定義為壞客戶����,假設(shè)用這種方式�����,那么大部分好客戶聚集在0.6���,以及大部分好客戶聚集在0.9這個位置,感知損失函數(shù)�����,判斷的時候可能是差不多的效果���。但是很明顯兩個模型的效果是�����,后者要好。當然你在實際的做模型的時候也不會單靠一個損失函數(shù)衡量模型啦�,只是你在擬合的時候可能使用的損失函數(shù)來擬合出機器覺得是最優(yōu)的。
3
Hinge損失函數(shù)
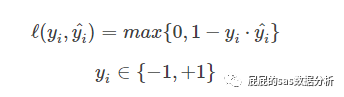
Hinge損失函數(shù)是源自于支持向量機中的��,因為支持向量機中����,最終的支持向量機的分類模型是能最大化分類間隔�,又減少錯誤分類的樣本數(shù)目�����,意味著一個好的支持向量機的模型��,需要滿足以上兩個條件:1�����、最大化分類間隔���,2����、錯誤分類的樣本數(shù)目�����。錯誤分類的樣本數(shù)目���,就回到了損失函數(shù)的范疇�。

我們看上面這張圖:把這四個點,根據(jù)下標分別叫1����、2、3�、4點,可以看到hinge衡量的是該錯誤分類的點到該分類的分類間隔線之間的距離��,像1點����,他雖然沒有被正確分類,但是是在分類間隔中���,所以他到正確被分類的線的距離是小于1的(分類間隔取的距離是1)�,那么像2����,3,4點他們到正確的分類間隔的距離都是超過1���,正確分類的則置為0,那么回到上面的公式����,支持向量機中�,分類使用+1����,-1表示,當樣本被正確分類�,那么就是0,即hinge的值為0��,那么如果在分隔中的時候��,hinge的值為1-真實值與預(yù)測值的積�����。舉個例子���,當真實值yi是1���,被分到正確分類的分類間隔之外,那么yi=1�����,>1,那么這時候即樣本被正確分類hinge值則為0。那么如果是被錯誤分類�����,則hinge值就是大于1了�。這就是hinge損失函數(shù)啦。
4
交叉熵損失函數(shù)
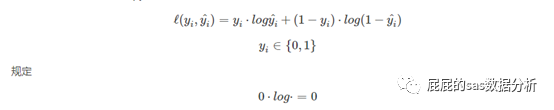
這個函數(shù)是在邏輯回歸中最大化似然函數(shù)推出來���,在公式層面的理解�,可以看到就是計算樣本的預(yù)測概率為目標值的概率的對數(shù)��。這個你不想聽公式推導也看下去啦�,因為這對于優(yōu)化問題的理解可以更深刻。

以上的公式中的h(x)代表的樣本是目標值的概率����,那么模型最極端的預(yù)測是什么,y=1的樣本的h(x)都為1����,y=0的樣本的h(x)都是0,那么你這個模型的正確率就是100%�,但在實際建模中這個可能性是極低的,所以這時候使用最大似然估計將全部的樣本的預(yù)測值連乘��,那么這時候意味著對于y=1的樣本,h(x)的值越大越好���,y=0的時候h(x)的值越小越好即1-h(x)的值越大越好,這時候似然估計這種相乘的方式貌似很難衡量那個模型是最好的���,所以加上log函數(shù)的轉(zhuǎn)化之后再加上一個負號���,全部的項變成相加,這時候我們只要求得-ln(l())最小就可以了����。這就是交叉熵損失函數(shù)。那么這里你可能會問����,為什么用的是log,不是用什么exp�����,冪函數(shù)這些�,因為log是單調(diào)遞增的,在將式子從相乘轉(zhuǎn)成相加的同時�,又保證了數(shù)值越大����,ln(x)的值越大��。
5
平方誤差
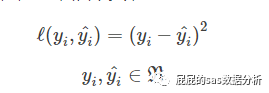
平方差�����,這個大家很熟啦����,線性回歸很愛用這個,這個衡量線性關(guān)系的時候比較好用�,在分類算法中比較少用。
6
絕對誤差
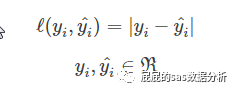
那么這個也是回歸中比較常用的��,也不做多的解釋��。
7
指數(shù)誤差
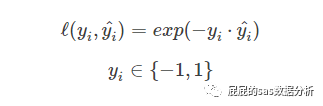
這是adaboosting中的一個損失函數(shù)��,假設(shè)目標變量還是用-1����,1表示,那么就以為在上面的公式中����,當yi=1的時候�����,就希望越大越好,即越小越好�,同樣可推當yi=0的時候。思想跟邏輯回歸類似����,但是因為這里使用-1,1表示目標變量���,所以損失函數(shù)有些區(qū)別���。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認證考試,點擊>>>
“CDA報名”
了解CDA考試詳情��;
? 想學習CDA考試教材����,點擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情;
? 想了解CDA考試含金量����,點擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330