數(shù)據(jù)挖掘入門——分詞
隨著社會化數(shù)據(jù)大量產(chǎn)生,硬件速度上升�����、成本降低�,大數(shù)據(jù)技術(shù)的落地實現(xiàn)����,讓冷冰冰的數(shù)據(jù)具有智慧逐漸成為新的熱點��。要從數(shù)據(jù)中發(fā)現(xiàn)有用的信息就要用到數(shù)據(jù)挖掘技術(shù),不過買來的數(shù)據(jù)挖掘書籍一打開全是大量的數(shù)學公式��,而課本知識早已還給老師了���,著實難以下手���、非常頭大!
我們不妨先跳過數(shù)學公式�,看看我們了解數(shù)據(jù)挖掘的目的——發(fā)現(xiàn)數(shù)據(jù)中價值。這個才是關(guān)鍵�����,如何發(fā)現(xiàn)數(shù)據(jù)中的價值�����。那什么是數(shù)據(jù)呢�����?比如大家要上網(wǎng)首先需要輸入網(wǎng)址��,打開網(wǎng)頁后會自動判斷哪些是圖片��、哪些是新聞、哪些是用戶名稱����、游戲圖標等。大腦可以存儲大量的信息�����,包括文字���、聲音、視頻�、圖片等,這些同樣可以轉(zhuǎn)換成數(shù)據(jù)存儲在電腦�。人的大腦可以根據(jù)輸入自動進行判斷,電腦可以通過輸入判斷嗎��?
答案是肯定的��!
不過需要我們編寫程序來判斷每一種信息��,就拿文字識別來說吧���,怎么從一個人在社交網(wǎng)絡(luò)的言論判斷他今天的心情是高興還是憤怒��!比如:“你假如上午沒給我吃冰淇淋�����,我絕對會不happy的����。”
信息發(fā)布時間為下午2點�。對于我們?nèi)祟愐豢催@個句子就知道他是吃過冰淇淋了,心情肯定不會是憤怒�����。那計算機怎么知道呢����?
這就是今天的主題,要讓計算機理解句子的語義�����,必須要有個程序�,上面的句子和發(fā)布時間是輸入,輸出就是
“高興”�。要得到“高興”就要建立
“高興”的規(guī)則�����,可以建一個感情色彩詞庫����,比如高興(識別詞是高興�����、happy)��,憤怒(識別詞是憤怒����、生氣)�。這里的識別詞就是輸入中出現(xiàn)的詞語,比如上面的句子中的“happy”就識別出了“高興”這個感情色彩詞�����。但是光識別出“happy”肯定是不行的�����,前面的“假如……沒……,我……不……”等關(guān)鍵詞都需要識別出來���,才能完整判斷一個句子的意思��。為了達到這個效果����,就必須要用分詞技術(shù)了�����。
分詞
我們先人工對上面的句子來進行一下切詞��,使用斜線分割:“你/假如/上午/沒/給/我/吃/冰淇淋/��,/我/絕對/會/不/happy/的/����。/”。但是程序如何做到自動切分���?這個其實中國的前輩們已經(jīng)做了很多中文分詞的研究����,常見的分詞算法有:
1. 基于詞典的分詞,需要先預設(shè)一個分詞詞典�����,比如上面句子切分出來的“假如��、上午”這些詞先存放在詞典��,然后把句子切分成單字組合成詞語去詞典里查找��,匹配上了就挑選出來一個詞�。沒有匹配上的就切分成單字。
2.
基于統(tǒng)計的分詞����,需要先獲取大量的文本語料庫(比如新聞、微博等)�,然后統(tǒng)計文本里相鄰的字同時出現(xiàn)的次數(shù)��,次數(shù)越多就越可能構(gòu)成一個詞�����。當達到一定次數(shù)時就構(gòu)成了一個詞�����,即可形成語料概率庫。再對上面句子進行單字切分���,把字與字結(jié)合后在語料概率庫里查找對應(yīng)的概率�����,如果概率大于一定值就挑選出來形成一個詞��。這個是大概描述�����,實際生產(chǎn)環(huán)境中還需要對句子的上下文進行結(jié)合才能更準確的分詞�����。
3. 基于語義的分詞���,簡而言之就是模擬人類對句子的理解來進行分詞。需要先整理出中文語句的句法��、語義信息作為知識庫,然后結(jié)合句子的上下文����,對句子進行單字切分后組合成詞逐個帶入知識庫進行識別,識別出來就挑選出一個詞���。目前還沒有特別成熟的基于語義的分詞系統(tǒng)�。
基于詞典的分詞
為了讓大家快速的了解分詞技術(shù)�,我們采用第一個方式來做測試:基于詞典的分詞,這種方式簡單暴力可以解決百分之七八十的問題���?����;谠~典的分詞大概分為以下幾種方式:
1.
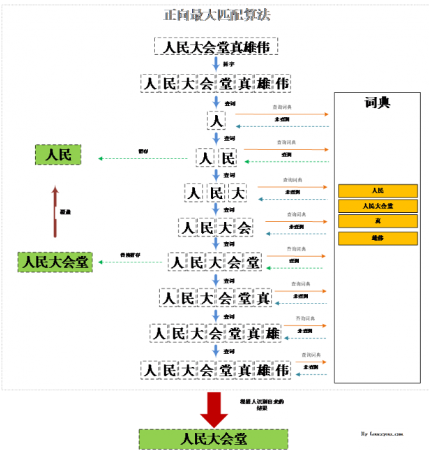
正向最大匹配��,沿著我們看到的句子逐字拆分后組合成詞語到詞典里去匹配���,直到匹配不到詞語為止。舉個實際的例子:“人民大會堂真雄偉”�����,我們先拆分為單字“人”去詞典里去查找���,發(fā)現(xiàn)有“人”這個詞����,繼續(xù)組合句子里的單字組合“人民”去詞典里查找���,發(fā)現(xiàn)有“人民”這個詞����,以此類推發(fā)現(xiàn)到“人民大會堂”��,然后會結(jié)合“人民大會堂真”去詞典里查找沒有找到這個詞�,第一個詞“人民大會堂”查找結(jié)束。最終分詞的結(jié)果為:“人民大會堂/真/雄偉”��。如下圖演示了用正向最大匹配算法識別人民大會堂的過程���,“真”�,“雄偉”的識別類似��。
2. 逆向最大匹配��,這個和上面相反,就是倒著推理���。比如“沿海南方向”��,我們按正向最大匹配來做就會切分成
“沿海/南方/向”���,這樣就明顯不對。采用逆向最大匹配法則來解決這個問題�����,從句子的最后取得“方向”這兩個字查找詞典找到“方向”這個詞�����。再加上“南方向”組成三字組合查找詞典沒有這個詞�����,查找結(jié)束��,找到“方向”這個詞����。以此類推���,最終分出“沿/海南/方向”���。
3.
雙向最大匹配�,顧名思義就是結(jié)合正向最大匹配和逆向最大匹配���,最終取其中合理的結(jié)果���。最早由哈工大王曉龍博士理論化的取最小切分詞數(shù),比如“我在中華人民共和國家的院子里看書”����,正向最大匹配切分出來為“我/在/中華人民共和國/家/的/院子/里/看書”工8個詞語,逆向最大匹配切分出來為“我/在/中華/人民/共/和/國家/的/院子/里/看書”共11個詞語��。取正向最大匹配切出來的結(jié)果就是正確的�。但是如果把上面那個例子“沿海南方向”雙向切分,都是3個詞語����,改如何選擇?看第4個《最佳匹配法則》��。
4.
最佳匹配法則,先準備一堆文本語料庫�、一個詞庫,統(tǒng)計詞庫里的每一個詞在語料庫里出現(xiàn)的次數(shù)記錄下來�����。最后按照詞頻高的優(yōu)先選出���,比如“沿海南方向”��,正向切分為:“沿海/南方/向”����,逆向切分為:“沿/海南/方向”�����。其中“海南”的頻度最高���,優(yōu)先取出來���。剩下“沿”、“方向”也就正常切分了����。是不是這就是基于詞典分詞的最佳方案����?比如數(shù)學之美中提到的:“把手抬起來”
和 “這扇門的把手”�����,可以分為“把”��、“手”����、“把手”���,不管怎么分總有一句話的意思不對���。后續(xù)再介紹如何通過統(tǒng)計的分詞處理這些問題。
說了這么多���,我們來實戰(zhàn)一下如何基于詞典的分詞:
public class TestPositiveMatch {
public static void main(String[] args) {
String str = "我愛這個中華人民共和國大家庭";
List<String> normalDict = new ArrayList<String>();
normalDict.add("");
normalDict.add("愛");
normalDict.add("中華"); //測試詞庫里有中華和中華人民共和國����,按照最大匹配應(yīng)該匹配出中華人民共和國
normalDict.add("中華人民共和國");
int strLen = str.length(); //傳入字符串的長度
int j = 0;
String matchWord = ""; //根據(jù)詞庫里識別出來的詞
int matchPos = 0; //根據(jù)詞庫里識別出來詞后當前句子中的位置
while (j < strLen) { //從0字符匹配到字符串結(jié)束
int matchPosTmp = 0; //截取字符串的位置
int i = 1;
while (matchPosTmp < strLen) { //從當前位置直到整句結(jié)束,匹配最大長度
matchPosTmp = i + j;
String keyTmp = str.substring(j, matchPosTmp);//切出最大字符串
if (normalDict.contains(keyTmp)) { //判斷當前字符串是否在詞典中
matchWord = keyTmp; //如果在詞典中匹配上了就賦值
matchPos = matchPosTmp; //同時保存好匹配位置
}
i++;
}
if (!matchWord.isEmpty()) {
//有匹配結(jié)果就輸出最大長度匹配字符串
j = matchPos;
//保存位置�,下次從當前位置繼續(xù)往后截取
System.out.print(matchWord + " ");
} else {
//從當前詞開始往后都沒有能夠匹配上的詞,則按照單字切分的原則切分
System.out.print(str.substring(j, ++j) + " ");
}
matchWord = "";
}
}
}
輸出結(jié)果為:我愛這個中華人民共和國大家庭
按照這樣我們一個基本的分詞程序開發(fā)完成�����。
對于文章一開始提到的問題還沒解決����,如何讓程序識別文本中的感情色彩。現(xiàn)在我們先要構(gòu)建一個感情色彩詞庫“高興”����,修飾詞庫“沒”、"不”��。再完善一下我們的程序:
public class TestSentimentPositiveMatch {
public static void main(String[] args) {
String str = "你假如上午沒給我吃冰淇淋����,我絕對會不happy的。";
//語義映射
Map<String, String> sentimentMap = new HashMap<String, String>();
sentimentMap.put("happy", "高興");
//情感詞庫
List<String> sentimentDict = new ArrayList<String>();
sentimentDict.add("happy");
//修飾詞
List<String> decorativeDict = new ArrayList<String>();
decorativeDict.add("不");
decorativeDict.add("沒");
//修飾詞衡量分數(shù)
Map<String, Double> decorativeScoreMap = new HashMap<String, Double>();
decorativeScoreMap.put("不", -0.5);
decorativeScoreMap.put("沒", -0.5);
List<String> decorativeWordList = new ArrayList<String>(); //修飾詞
String sentimentResult = ""; //情感結(jié)果
int strLen = str.length(); //傳入字符串的長度
int j = 0;
String matchSentimentWord = ""; //根據(jù)詞庫里識別出來的情感詞
String matchDecorativeWord = ""; //根據(jù)詞庫里識別出來的修飾詞
int matchPos = 0; //根據(jù)詞庫里識別出來詞后當前句子中的位置
while (j < strLen) { //從0字符匹配到字符串結(jié)束
int matchPosTmp = 0; //截取字符串的位置
int i = 1;
while (matchPosTmp < strLen) { //從當前位置直到整句結(jié)束���,匹配最大長度
matchPosTmp = i + j;
String keyTmp = str.substring(j, matchPosTmp);//切出最大字符串
if (sentimentDict.contains(keyTmp)) { //判斷當前字符串是否在詞典中
matchSentimentWord = keyTmp; //如果在詞典中匹配上了就賦值
matchPos = matchPosTmp; //同時保存好匹配位置
}
if (decorativeDict.contains(keyTmp)) { //判斷當前字符串是否在詞典中
matchDecorativeWord = keyTmp; //如果在詞典中匹配上了就賦值
matchPos = matchPosTmp; //同時保存好匹配位置
}
i++;
}
if (!matchSentimentWord.isEmpty()) {
//有匹配結(jié)果就輸出最大長度匹配字符串
j = matchPos;
//保存位置����,下次從當前位置繼續(xù)往后截取
System.out.print(matchSentimentWord + " ");
sentimentResult = sentimentMap.get(matchSentimentWord);
}
if (!matchDecorativeWord.isEmpty()) {
//有匹配結(jié)果就輸出最大長度匹配字符串
j = matchPos;
//保存位置,下次從當前位置繼續(xù)往后截取
System.out.print(matchDecorativeWord + " ");
decorativeWordList.add(matchDecorativeWord);
} else {
//從當前詞開始往后都沒有能夠匹配上的詞�����,則按照單字切分的原則切分
System.out.print(str.substring(j, ++j) + " ");
}
matchSentimentWord = "";
matchDecorativeWord = "";
}
double totalScore = 1;
for (String decorativeWord : decorativeWordList) {
Double scoreTmp = decorativeScoreMap.get(decorativeWord);
totalScore *= scoreTmp;
}
System.out.print("\r\n");
if (totalScore > 0) {
System.out.println("當前心情是:" + sentimentResult);
} else {
System.out.println("當前心情是:不" + sentimentResult);
}
}
}
通過傳入“你假如上午沒給我吃冰淇淋����,我絕對會不happy的?�!?,結(jié)果輸出為:“當前心情是:高興”���。當然你也可以改變其中的修飾詞���,比如改為:“你假如上午沒給我吃冰淇淋,我絕對會happy的����。”���,結(jié)果輸出為:“當前心情是:不高興”����。
機器再也不是冷冰冰的,看起來他能讀懂你的意思了���。不過這只是一個開始����,拋出幾個問題:
-
如何讓程序識別句子中的時間��?比如“上午”���、“下午2點”���。
-
如何處理“把手抬起來” 和 “這扇門的把手”中的“把”與“手”的問題?
-
如何構(gòu)建海量的知識庫�����,讓程序從“嬰兒”變成“成年人”���?
-
如何使用有限的存儲空間存儲海量的知識庫����?
-
如何提高程序在海量知識庫中查找定位信息的效率?
-
如何識別新詞�����、人名�����、新鮮事物等未知領(lǐng)域�����?
宇宙蕓蕓眾生都是相通的��,大腦也許就是一個小宇宙��,在這個小宇宙又有很多星球���、住著很多生物。而電腦也是宇宙中地球上的一個產(chǎn)物���,只要存儲計算速度發(fā)展到足夠強大一定可以構(gòu)建成一個強大的大腦�。
你看這個單詞 "testaword" 認識嗎?可能不認識�,因為我們五官先獲取到的信息,然后根據(jù)大腦以往學習的經(jīng)驗做出判斷����。但是你看這個短語 " test a word" 認識嗎?再看看開始那個單詞“testaword”是不是就親切多了�����?
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認證考試����,點擊>>>
“CDA報名”
了解CDA考試詳情;
? 想學習CDA考試教材�����,點擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫���,點擊>>> “CDA題庫” 了解CDA考試詳情;
? 想了解CDA考試含金量����,點擊>>> “CDA含金量” 了解CDA考試詳情�����;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330