機器學習和數(shù)據(jù)挖掘的聯(lián)系與區(qū)別
從數(shù)據(jù)分析的角度來看,數(shù)據(jù)挖掘與機器學習有很多相似之處�,但不同之處也十分明顯,例如����,數(shù)據(jù)挖掘并沒有機器學習探索人的學習機制這一科學發(fā)現(xiàn)任務,數(shù)據(jù)挖掘中的數(shù)據(jù)分析是針對海量數(shù)據(jù)進行的�,等等���。從某種意義上說����,機器學習的科學成分更重一些���,而數(shù)據(jù)挖掘的技術成分更重一些。
本文選自《大數(shù)據(jù)架構詳解:從數(shù)據(jù)獲取到深度學習》

機器學習(Machine Learning���,ML)是一門多領域交叉學科�,涉及概率論�����、統(tǒng)計學、逼近論�����、凸分析���、算法復雜度理論等多門學科。其專門研究計算機是怎樣模擬或實現(xiàn)人類的學習行為�,以獲取新的知識或技能,重新組織已有的知識結構���,使之不斷改善自身的性能�����。
數(shù)據(jù)挖掘是從海量數(shù)據(jù)中獲取有效的�、新穎的�、潛在有用的、最終可理解的模式的非平凡過程����。數(shù)據(jù)挖掘中用到了大量的機器學習界提供的數(shù)據(jù)分析技術和數(shù)據(jù)庫界提供的數(shù)據(jù)管理技術�����。
學習能力是智能行為的一個非常重要的特征,不具有學習能力的系統(tǒng)很難稱之為一個真正的智能系統(tǒng)���,而機器學習則希望(計算機)系統(tǒng)能夠利用經(jīng)驗來改善自身的性能�����,因此該領域一直是人工智能的核心研究領域之一����。在計算機系統(tǒng)中�����,“經(jīng)驗”通常是以數(shù)據(jù)的形式存在的�,因此,機器學習不僅涉及對人的認知學習過程的探索���,還涉及對數(shù)據(jù)的分析處理�����。實際上��,機器學習已經(jīng)成為計算機數(shù)據(jù)分析技術的創(chuàng)新源頭之一��。由于幾乎所有的學科都要面對數(shù)據(jù)分析任務�����,因此機器學習已經(jīng)開始影響到計算機科學的眾多領域�����,甚至影響到計算機科學之外的很多學科���。機器學習是數(shù)據(jù)挖掘中的一種重要工具�����。然而數(shù)據(jù)挖掘不僅僅要研究��、拓展���、應用一些機器學習方法,還要通過許多非機器學習技術解決數(shù)據(jù)倉儲、大規(guī)模數(shù)據(jù)���、數(shù)據(jù)噪聲等實踐問題�����。機器學習的涉及面也很寬,常用在數(shù)據(jù)挖掘上的方法通常只是“從數(shù)據(jù)學習”�����。然而機器學習不僅僅可以用在數(shù)據(jù)挖掘上��,一些機器學習的子領域甚至與數(shù)據(jù)挖掘關系不大�,如增強學習與自動控制等。所以筆者認為�����,數(shù)據(jù)挖掘是從目的而言的����,機器學習是從方法而言的,兩個領域有相當大的交集����,但不能等同���。
典型的數(shù)據(jù)挖掘和機器學習過程
下圖是一個典型的推薦類應用,需要找到“符合條件的”潛在人員�。要從用戶數(shù)據(jù)中得出這張列表,首先需要挖掘出客戶特征���,然后選擇一個合適的模型來進行預測�����,最后從用戶數(shù)據(jù)中得出結果�����。
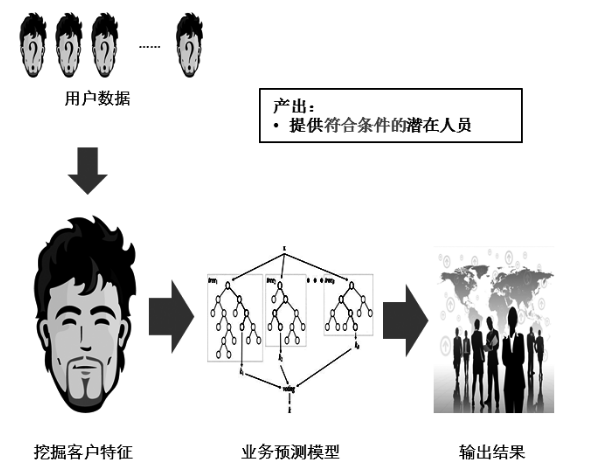
把上述例子中的用戶列表獲取過程進行細分�����,有如下幾個部分�����。
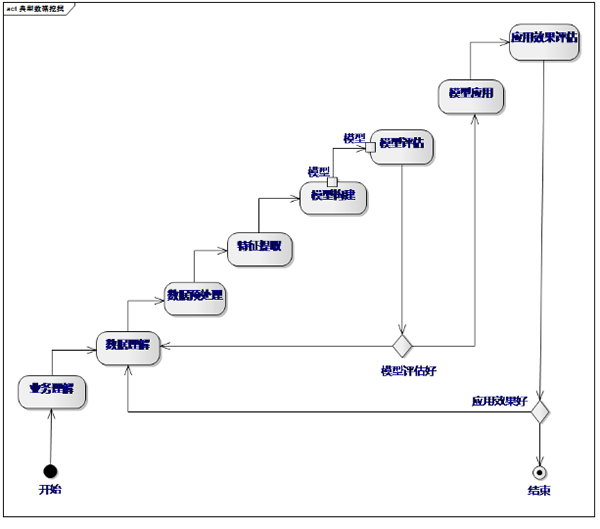
業(yè)務理解:理解業(yè)務本身����,其本質是什么?是分類問題還是回歸問題?數(shù)據(jù)怎么獲取?應用哪些模型才能解決?
數(shù)據(jù)理解:獲取數(shù)據(jù)之后,分析數(shù)據(jù)里面有什么內容�、數(shù)據(jù)是否準確,為下一步的預處理做準備���。
數(shù)據(jù)預處理:原始數(shù)據(jù)會有噪聲���,格式化也不好�����,所以為了保證預測的準確性���,需要進行數(shù)據(jù)的預處理�。
特征提?�。?a href='/map/tezheng/' style='color:#000;font-size:inherit;'>特征提取是機器學習最重要��、最耗時的一個階段�。
模型構建:使用適當?shù)乃惴ǎ@取預期準確的值���。
模型評估:根據(jù)測試集來評估模型的準確度��。
模型應用:將模型部署���、應用到實際生產環(huán)境中����。
應用效果評估:根據(jù)最終的業(yè)務��,評估最終的應用效果�����。
整個過程會不斷反復�����,模型也會不斷調整�����,直至達到理想效果��。
機器學習&數(shù)據(jù)挖掘應用案例
1 尿布和啤酒的故事
先來看一則有關數(shù)據(jù)挖掘的故事——“尿布與啤酒”��。
總部位于美國阿肯色州的世界著名商業(yè)零售連鎖企業(yè)沃爾瑪擁有世界上最大的數(shù)據(jù)倉庫系統(tǒng)。為了能夠準確了解顧客在其門店的購買習慣�����,沃爾瑪對其顧客的購物行為進行購物籃分析�����,想知道顧客經(jīng)常一起購買的商品有哪些�。沃爾瑪數(shù)據(jù)倉庫里集中了其各門店的詳細原始交易數(shù)據(jù),在這些原始交易數(shù)據(jù)的基礎上���,沃爾瑪利用NCR數(shù)據(jù)挖掘工具對這些數(shù)據(jù)進行分析和挖掘���。一個意外的發(fā)現(xiàn)是:跟尿布一起購買最多的商品竟然是啤酒!這是數(shù)據(jù)挖掘技術對歷史數(shù)據(jù)進行分析的結果�,反映了數(shù)據(jù)的內在規(guī)律。那么�����,這個結果符合現(xiàn)實情況嗎?是否有利用價值?
于是�,沃爾瑪派出市場調查人員和分析師對這一數(shù)據(jù)挖掘結果進行調查分析,從而揭示出隱藏在“尿布與啤酒”背后的美國人的一種行為模式:在美國����,一些年輕的父親下班后經(jīng)常要到超市去買嬰兒尿布�,而他們中有30%~40%的人同時也為自己買一些啤酒����。產生這一現(xiàn)象的原因是:美國的太太們常叮囑她們的丈夫下班后為小孩買尿布,而丈夫們在買完尿布后又隨手帶回了他們喜歡的啤酒����。
既然尿布與啤酒一起被購買的機會很多,于是沃爾瑪就在其各家門店將尿布與啤酒擺放在一起�,結果是尿布與啤酒的銷售量雙雙增長。
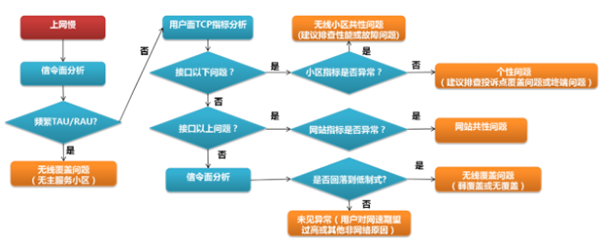
2 決策樹用于電信領域故障快速定位
電信領域比較常見的應用場景是決策樹���,利用決策樹來進行故障定位����。比如�����,用戶投訴上網(wǎng)慢�����,其中就有很多種原因,有可能是網(wǎng)絡的問題��,也有可能是用戶手機的問題�����,還有可能是用戶自身感受的問題���。怎樣快速分析和定位出問題��,給用戶
一個滿意的答復?這就需要用到決策樹����。
下圖就是一個典型的用戶投訴上網(wǎng)慢的決策樹的樣例�����。
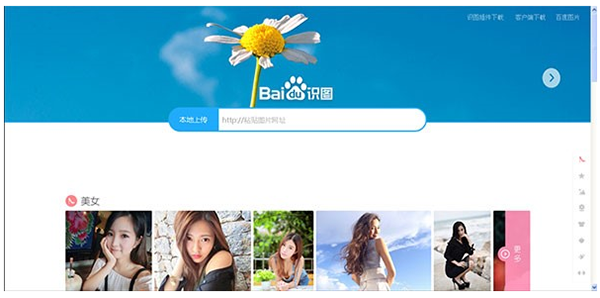
3 圖像識別領域
百度的百度識圖能夠有效地處理特定物體的檢測識別(如人臉���、文字或商品)、通用圖像的分類標注�。
來自Google研究院的科學家發(fā)表了一篇博文,展示了Google在圖形識別領域的最新研究進展���?���;蛟S未來Google的圖形識別引擎不僅能夠識別出圖片中的對象,還能夠對整個場景進行簡短而準確的描述��。這種突破性的概念來自機器語言翻譯方面的研究成果:通過一種遞歸神經(jīng)網(wǎng)絡(RNN)將一種語言的語句轉換成向量表達�,并采用第二種RNN將向量表達轉換成目標語言的語句。

而Google將以上過程中的第一種RNN用深度卷積神經(jīng)網(wǎng)絡CNN替代���,這種網(wǎng)絡可以用來識別圖像中的物體��。通過這種方法可以實現(xiàn)將圖像中的對象轉換成語句���,對圖像場景進行描述。概念雖然簡單����,但實現(xiàn)起來十分復雜,科學家表示目前實驗產生的語句合理性不錯���,但距離完美仍有差距���,這項研究目前僅處于早期階段�。下圖展示了通過此方法識別圖像對象并產生描述的過程����。
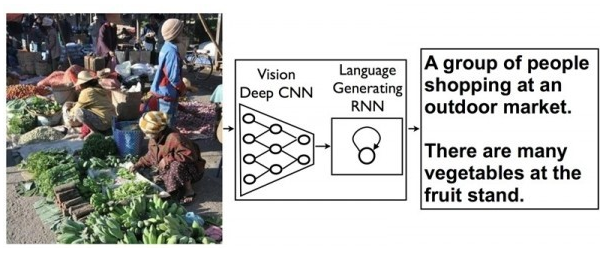
4 自然語言識別
自然語言識別一直是一個非常熱門的領域,最有名的是蘋果的Siri���,支持資源輸入����,調用手機自帶的天氣預報�����、日常安排���、搜索資料等應用����,還能夠不斷學習新的聲音和語調�����,提供對話式的應答����。
微軟的Skype Translator可以實現(xiàn)中英文之間的實時語音翻譯功能,將使得英文和中文普通話之間的實時語音對話成為現(xiàn)實��。
Skype Translator的運作機制如圖��。
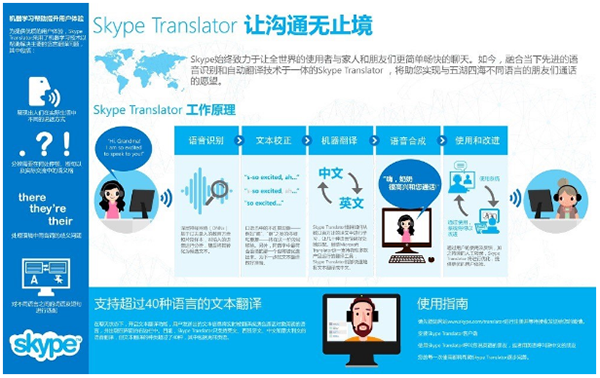
在準備好的數(shù)據(jù)被錄入機器學習系統(tǒng)后����,機器學習軟件會在這些對話和環(huán)境涉及的單詞中搭建一個統(tǒng)計模型。當用戶說話時�����,軟件會在該統(tǒng)計模型中尋找相似的內容����,然后應用到預先“學到”的轉換程序中,將音頻轉換為文本���,再將文本轉換成另一種語言�。
雖然語音識別一直是近幾十年來的重要研究課題����,但是該技術的發(fā)展普遍受到錯誤率高����、麥克風敏感度差異��、噪聲環(huán)境等因素的阻礙��。將深層神經(jīng)網(wǎng)絡(DNNs)技術引入語音識別����,極大地降低了錯誤率、提高了可靠性�,最終使這項語音翻譯技術得以廣泛應用。
CDA數(shù)據(jù)分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試��,點擊>>>
“CDA報名”
了解CDA考試詳情��;
? 想學習CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫���,點擊>>> “CDA題庫” 了解CDA考試詳情���;
? 想了解CDA考試含金量����,點擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330