從線性回歸到無(wú)監(jiān)督學(xué)習(xí)��,數(shù)據(jù)科學(xué)家需要掌握的十大統(tǒng)
不管你對(duì)數(shù)據(jù)科學(xué)持什么態(tài)度�����,都不可能忽略分析���、組織和梳理數(shù)據(jù)的重要性。Glassdoor 網(wǎng)站根據(jù)大量雇主和員工的反饋數(shù)據(jù)制作了「美國(guó)最好的
25
個(gè)職位」榜單�����,其中第一名就是數(shù)據(jù)科學(xué)家。盡管排名已經(jīng)頂尖了�����,但數(shù)據(jù)科學(xué)家的工作內(nèi)容一定不會(huì)就此止步�。隨著深度學(xué)習(xí)等技術(shù)越來(lái)越普遍、深度學(xué)習(xí)等熱門(mén)領(lǐng)域越來(lái)越受到研究者和工程師以及雇傭他們的企業(yè)的關(guān)注��,數(shù)據(jù)科學(xué)家繼續(xù)走在創(chuàng)新和技術(shù)進(jìn)步的前沿�����。
盡管具備強(qiáng)大的編程能力非常重要�����,但數(shù)據(jù)科學(xué)不全關(guān)于軟件工程(實(shí)際上����,只要熟悉 Python
就足以滿(mǎn)足編程的需求)。數(shù)據(jù)科學(xué)家需要同時(shí)具備編程���、統(tǒng)計(jì)學(xué)和批判思維能力��。正如 Josh Wills
所說(shuō):「數(shù)據(jù)科學(xué)家比程序員擅長(zhǎng)統(tǒng)計(jì)學(xué)�����,比統(tǒng)計(jì)學(xué)家擅長(zhǎng)編程��。」我自己認(rèn)識(shí)很多軟件工程師希望轉(zhuǎn)型成為數(shù)據(jù)科學(xué)家���,但是他們盲目地使用
TensorFlow 或 Apache Spark
等機(jī)器學(xué)習(xí)框架處理數(shù)據(jù)����,而沒(méi)有全面理解其背后的統(tǒng)計(jì)學(xué)理論知識(shí)�����。因此他們需要系統(tǒng)地研究統(tǒng)計(jì)機(jī)器學(xué)習(xí)�����,該學(xué)科脫胎于統(tǒng)計(jì)學(xué)和泛函分析,并結(jié)合了信息論���、最優(yōu)化理論和線性代數(shù)等多門(mén)學(xué)科���。
為什么學(xué)習(xí)統(tǒng)計(jì)學(xué)習(xí)?理解不同技術(shù)背后的理念非常重要��,它可以幫助你了解如何使用以及什么時(shí)候使用����。同時(shí),準(zhǔn)確評(píng)估一種方法的性能也非常重要�����,因?yàn)樗芨嬖V我們某種方法在特定問(wèn)題上的表現(xiàn)���。此外�����,統(tǒng)計(jì)學(xué)習(xí)也是一個(gè)很有意思的研究領(lǐng)域���,在科學(xué)��、工業(yè)和金融領(lǐng)域都有重要的應(yīng)用�。最后�,統(tǒng)計(jì)學(xué)習(xí)是訓(xùn)練現(xiàn)代數(shù)據(jù)科學(xué)家的基礎(chǔ)組成部分。統(tǒng)計(jì)學(xué)習(xí)方法的經(jīng)典研究主題包括:
線性回歸模型
感知機(jī)
k 近鄰法
樸素貝葉斯法
決策樹(shù)
Logistic 回歸于最大熵模型
支持向量機(jī)
提升方法
EM 算法
隱馬爾可夫模型
條件隨機(jī)場(chǎng)
之后我將介紹 10 項(xiàng)統(tǒng)計(jì)技術(shù)����,幫助數(shù)據(jù)科學(xué)家更加高效地處理大數(shù)據(jù)集的統(tǒng)計(jì)技術(shù)。在此之前��,我想先厘清統(tǒng)計(jì)學(xué)習(xí)和機(jī)器學(xué)習(xí)的區(qū)別:
機(jī)器學(xué)習(xí)是偏向人工智能的分支�����。
統(tǒng)計(jì)學(xué)習(xí)方法是偏向統(tǒng)計(jì)學(xué)的分支�����。
機(jī)器學(xué)習(xí)更側(cè)重大規(guī)模應(yīng)用和預(yù)測(cè)準(zhǔn)確率���。
統(tǒng)計(jì)學(xué)系側(cè)重模型及其可解釋性,以及精度和不確定性����。
二者之間的區(qū)別越來(lái)越模糊�。
1. 線性回歸
在統(tǒng)計(jì)學(xué)中���,線性回歸通過(guò)擬合因變量和自變量之間的最佳線性關(guān)系來(lái)預(yù)測(cè)目標(biāo)變量����。最佳擬合通過(guò)盡量縮小預(yù)測(cè)的線性表達(dá)式和實(shí)際觀察結(jié)果間的距離總和來(lái)實(shí)現(xiàn)����。沒(méi)有其他位置比該形狀生成的錯(cuò)誤更少,從這個(gè)角度來(lái)看��,該形狀的擬合是「最佳」�。線性回歸的兩個(gè)主要類(lèi)型是簡(jiǎn)單線性回歸和多元線性回歸。
簡(jiǎn)單線性回歸使用一個(gè)自變量通過(guò)擬合最佳線性關(guān)系來(lái)預(yù)測(cè)因變量的變化情況����。多元線性回歸使用多個(gè)自變量通過(guò)擬合最佳線性關(guān)系來(lái)預(yù)測(cè)因變量的變化趨勢(shì)。
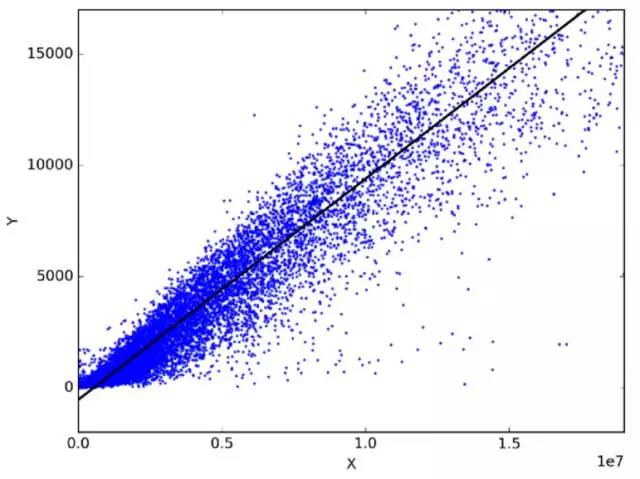
任意選擇兩個(gè)日常使用且相關(guān)的物體�。比如,我有過(guò)去三年月支出���、月收入和每月旅行次數(shù)的數(shù)據(jù)?����,F(xiàn)在我需要回答以下問(wèn)題:
我下一年月支出是多少���?
哪個(gè)因素(月收入或每月旅行次數(shù))在決定月支出方面更重要�?
月收入和每月旅行次數(shù)與月支出之間是什么關(guān)系�����?
2. 分類(lèi)
分類(lèi)是一種數(shù)據(jù)挖掘技術(shù)��,為數(shù)據(jù)分配類(lèi)別以幫助進(jìn)行更準(zhǔn)確的預(yù)測(cè)和分析���。分類(lèi)是一種高效分析大型數(shù)據(jù)集的方法���,兩種主要的分類(lèi)技術(shù)是:logistic 回歸和判別分析(Discriminant Analysis)。
logistic 回歸是適合在因變量為二元類(lèi)別的回歸分析���。和所有回歸分析一樣,logistic 回歸是一種預(yù)測(cè)性分析�����。logistic
回歸用于描述數(shù)據(jù)�,并解釋二元因變量和一或多個(gè)描述事物特征的自變量之間的關(guān)系�。logistic 回歸可以檢測(cè)的問(wèn)題類(lèi)型如下:
體重每超出標(biāo)準(zhǔn)體重一磅或每天每抽一包煙對(duì)得肺癌概率(是或否)的影響����。
卡路里攝入、脂肪攝入和年齡對(duì)心臟病是否有影響(是或否)�?
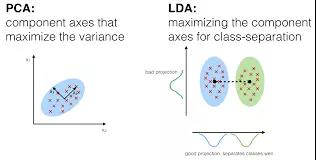
在判別分析中,兩個(gè)或多個(gè)集合和簇等可作為先驗(yàn)類(lèi)別�,然后根據(jù)度量的特征把一個(gè)或多個(gè)新的觀察結(jié)果分類(lèi)成已知的類(lèi)別。判別分析對(duì)每個(gè)對(duì)應(yīng)類(lèi)中的預(yù)測(cè)器分布
X 分別進(jìn)行建模����,然后使用貝葉斯定理將其轉(zhuǎn)換成根據(jù) X 的值評(píng)估對(duì)應(yīng)類(lèi)別的概率。此類(lèi)模型可以是線性判別分析(Linear
Discriminant Analysis)����,也可以是二次判別分析(Quadratic Discriminant Analysis)。
線性判別分析(LDA):為每個(gè)觀察結(jié)果計(jì)算「判別值」來(lái)對(duì)它所處的響應(yīng)變量類(lèi)進(jìn)行分類(lèi)����。這些分值可以通過(guò)找到自變量的線性連接來(lái)獲得。它假設(shè)每個(gè)類(lèi)別的觀察結(jié)果都從多變量高斯分布中獲取�,預(yù)測(cè)器變量的協(xié)方差在響應(yīng)變量 Y 的所有 k 級(jí)別中都很普遍。
二次判別分析(QDA):提供另外一種方法�����。和 LDA 類(lèi)似,QDA 假設(shè) Y 每個(gè)類(lèi)別的觀察結(jié)果都從高斯分布中獲取��。但是���,與 LDA 不同的是�����,QDA 假設(shè)每個(gè)類(lèi)別具備自己的協(xié)方差矩陣��。也就是說(shuō)���,預(yù)測(cè)器變量在 Y 的所有 k 級(jí)別中不是普遍的。
3. 重采樣方法
重采樣方法(Resampling)包括從原始數(shù)據(jù)樣本中提取重復(fù)樣本�����。這是一種統(tǒng)計(jì)推斷的非參數(shù)方法�����。即��,重采樣不使用通用分布來(lái)逼近地計(jì)算概率 p 的值���。
重采樣基于實(shí)際數(shù)據(jù)生成一個(gè)獨(dú)特的采樣分布���。它使用經(jīng)驗(yàn)性方法,而不是分析方法�����,來(lái)生成該采樣分布�����。重采樣基于數(shù)據(jù)所有可能結(jié)果的無(wú)偏樣本獲取無(wú)偏估計(jì)�����。為了理解重采樣的概念�����,你應(yīng)該先了解自助法(Bootstrapping)和交叉驗(yàn)證(Cross-Validation):
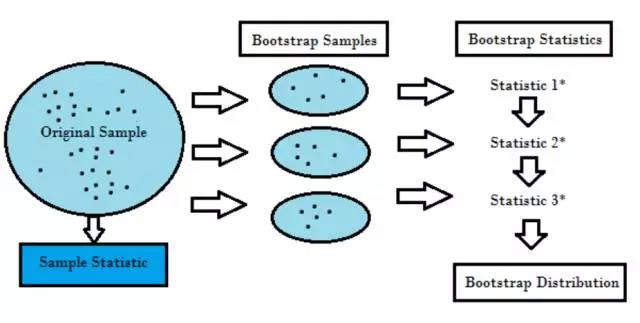
自助法(Bootstrapping)適用于多種情況�,如驗(yàn)證預(yù)測(cè)性模型的性能、集成方法����、偏差估計(jì)和模型方差�����。它通過(guò)在原始數(shù)據(jù)中執(zhí)行有放回取樣而進(jìn)行數(shù)據(jù)采樣�,使用「未被選中」的數(shù)據(jù)點(diǎn)作為測(cè)試樣例���。我們可以多次執(zhí)行該操作�,然后計(jì)算平均值作為模型性能的估計(jì)���。
交叉驗(yàn)證用于驗(yàn)證模型性能�����,通過(guò)將訓(xùn)練數(shù)據(jù)分成 k 部分來(lái)執(zhí)行�。我們將 k-1 部分作為訓(xùn)練集�,「留出」的部分作為測(cè)試集。將該步驟重復(fù) k 次�,最后取 k 次分值的平均值作為性能估計(jì)。
通常對(duì)于線性模型而言����,普通最小二乘法是擬合數(shù)據(jù)時(shí)主要的標(biāo)準(zhǔn)����。下面 3 個(gè)方法可以提供更好的預(yù)測(cè)準(zhǔn)確率和模型可解釋性����。
4. 子集選擇
該方法將挑選 p 個(gè)預(yù)測(cè)因子的一個(gè)子集���,并且我們相信該子集和所需要解決的問(wèn)題十分相關(guān)����,然后我們就能使用該子集特征和最小二乘法擬合模型����。
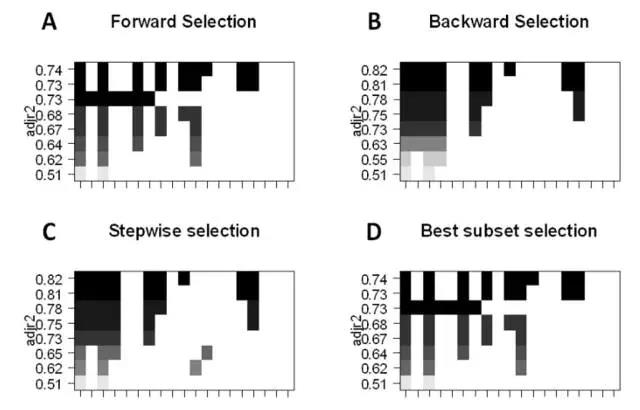
最佳子集的選擇:我們可以為 p 個(gè)預(yù)測(cè)因子的每個(gè)組合擬合單獨(dú)的 OLS 回歸,然后再考察各模型擬合的情況�。該算法分為兩個(gè)階段:(1)擬合包含
k 個(gè)預(yù)測(cè)因子的所有模型,其中 k
為模型的最大長(zhǎng)度�����;(2)使用交叉驗(yàn)證預(yù)測(cè)損失選擇單個(gè)模型���。使用驗(yàn)證或測(cè)試誤差十分重要���,且不能簡(jiǎn)單地使用訓(xùn)練誤差評(píng)估模型的擬合情況��,這因?yàn)?RSS
和 R^2 隨變量的增加而單調(diào)遞增����。最好的方法就是通過(guò)測(cè)試集中最高的 R^2 和最低的 RSS 來(lái)交叉驗(yàn)證地選擇模型��。
前向逐步地選擇會(huì)考慮 p
個(gè)預(yù)測(cè)因子的一個(gè)較小子集��。它從不含預(yù)測(cè)因子的模型開(kāi)始����,逐步地添加預(yù)測(cè)因子到模型中,直到所有預(yù)測(cè)因子都包含在模型���。添加預(yù)測(cè)因子的順序是根據(jù)不同變量對(duì)模型擬合性能提升的程度來(lái)確定的���,我們會(huì)添加變量直到再?zèng)]有預(yù)測(cè)因子能在交叉驗(yàn)證誤差中提升模型。
后向逐步選擇先從模型中所有 p 預(yù)測(cè)器開(kāi)始��,然后迭代地移除用處最小的預(yù)測(cè)器����,每次移除一個(gè)�。
混合法遵循前向逐步方法��,但是在添加每個(gè)新變量之后���,該方法可能還會(huì)移除對(duì)模型擬合無(wú)用的變量���。
5. Shrinkage
這種方法涉及到使用所有 p
個(gè)預(yù)測(cè)因子進(jìn)行建模��,然而����,估計(jì)預(yù)測(cè)因子重要性的系數(shù)將根據(jù)最小二乘誤差向零收縮����。這種收縮也稱(chēng)之為正則化���,它旨在減少方差以防止模型的過(guò)擬合���。由于我們使用不同的收縮方法��,有一些變量的估計(jì)將歸零����。因此這種方法也能執(zhí)行變量的選擇�����,將變量收縮為零最常見(jiàn)的技術(shù)就是
Ridge 回歸和 Lasso 回歸。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試��,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情��;
? 想學(xué)習(xí)CDA考試教材���,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫(kù)�,點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情;
? 想了解CDA考試含金量�,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330