教你如何用R進行數(shù)據(jù)挖掘
R是一種廣泛用于數(shù)據(jù)分析和統(tǒng)計計算的強大語言����,于上世紀90年代開始發(fā)展起來����。得益于全世界眾多
愛好者的無盡努力��,大家繼而開發(fā)出了一種基于R但優(yōu)于R基本文本編輯器的R
Studio(用戶的界面體驗更好)���。也正是由于全世界越來越多的數(shù)據(jù)科學(xué)社區(qū)和用戶對R包的慷慨貢獻��,讓R語言在全球范圍內(nèi)越來越流行��。其中一些R包��,例如MASS��,SparkR��,
ggplot2��,使數(shù)據(jù)操作,可視化和計算功能越來越強大����。
我們所說的機器學(xué)習(xí)和R有什么關(guān)系呢���?我對R的第一印象是,它只是一個統(tǒng)計計算的一個軟件�。但是后來我發(fā)現(xiàn)R有足夠的能力以一個快速和簡單的方式來實現(xiàn)機器學(xué)習(xí)算法。這是用R來學(xué)習(xí)數(shù)據(jù)科學(xué)和機器學(xué)習(xí)的完整教程���,讀完本文,你將有使用機器學(xué)習(xí)的方法來構(gòu)建預(yù)測模型的基本能力���。
注:這篇文章對于之前沒有很多數(shù)據(jù)科學(xué)知識的同學(xué)們是特別值得一看的,同時掌握一定的代數(shù)和統(tǒng)計知識將會更有益于您的學(xué)習(xí)���。
一�����、初識R語言
1���、為什么學(xué)R ? 事實上,我沒有編程經(jīng)驗�����,也沒有學(xué)過計算機�。但是我知道如果要學(xué)習(xí)數(shù)據(jù)科學(xué),一個人必須學(xué)習(xí)R或Python作為開始學(xué)習(xí)的工具�。我選擇了前者,同時在學(xué)習(xí)過程中我發(fā)現(xiàn)了一些使用R的好處:
? 用R語言編碼非常的簡單��; ? R是一個免費的開源軟件,同時它可以直接在官網(wǎng)上下載�����; ?
R語言中有來自于全世界愛好者貢獻的即時訪問超過7800個用于不同計算的R包��。 ? R語言還有遍布全世界的學(xué)習(xí)社區(qū)及論壇���,你能很輕松的獲取幫助��; ?
我們憑借R包能夠獲得高性能的計算體驗����; ? 它是,數(shù)據(jù)分析公司高度尋求技能之一�����。
2����、如何安裝R / Rstudio?
你可以https://www.r-project.org/官網(wǎng)下載并安裝R,需要注意的是R的更新速度很快��,下載新版本的體驗會更好一些���。 另外,我建議你從RStudio開始����,因為RStudio的界面編程體驗更好一些。你可以通過https://www.rstudio.com/products/rstudio/download/ 在“支持的平臺上安裝”部分中,
根據(jù)您的操作系統(tǒng)選擇您需要的安裝程序��。點擊桌面圖標(biāo)RStudio,就開始你的編程體驗�,如下圖所示:
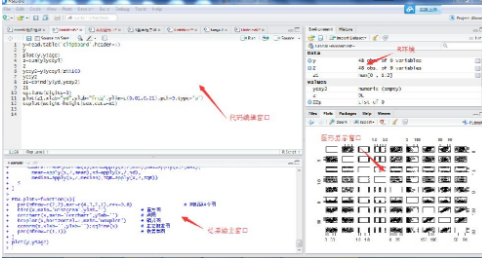
讓我們快速的了解:一下R界面 ? R script::在這個空間里可以寫代碼,要運行這些代碼,只需選擇的代碼行和按下Ctrl +
R即可或者,你可以點擊“運行”按鈕位置在右上角R的腳本���。 ? R
console:這個區(qū)域顯示的輸出代碼運行:���,同時你可以在控制臺直接寫代碼。但是代碼直接進入R控制臺無法追蹤���。 ?
R環(huán)境:這個空間是顯示設(shè)置的外部元素補充道��。這里面包括數(shù)據(jù)集��、變量向量,還可以檢查R數(shù)據(jù)是否被正確加載��。 ?
圖形輸出窗口:這個空間顯示圖表中創(chuàng)建的探索性數(shù)據(jù)分析。不僅僅輸出圖形,您可以選擇包,尋求幫助和嵌入式R的官方文檔����。
3�����、如何安裝包���?
R的計算能力在于它擁有強大的R包。在R中,大多數(shù)數(shù)據(jù)處理任務(wù)可以從兩方面進行�����,使用R包和基本功能�����。在本教程中,我們將介紹最方便的和強大的R包���。特別的�����,一般不太建議直接在R軟件的中直接安裝加載包����,因為這樣可能會影響你的計算速度。我們建議你直接在R的官網(wǎng)上下載好您所需要的R包�,通過本地安裝的形式進行安裝,如下:
在軟件中安裝:install.packages(“package name”) 本地安裝:
install.packages(“E:/r/ggplot2_2.1.0.zip”)
4�、用R進行基本的統(tǒng)計計算 讓我們開始熟悉R的編程環(huán)境及一些基本的計算,在R編程腳本窗口中輸入程序����,如下:
> 2 + 3
> 5
> 6 / 3
> 2
> (3*8)/(2*3)
> 4
> log(12)
> 1.07
> sqrt (121)
> 11
類似地,您也可以自己嘗試各種組合的計算形式并得到結(jié)果。但是,如果你做了太多的計算����,這樣的編程未免過于麻煩,在這種情況下,創(chuàng)建變量是一個有用的方法����。在R中,您可以創(chuàng)建變量的形式來簡化。創(chuàng)建變量時使用<
-或=符號��,例如我想創(chuàng)建一個變量x計算7和8的總和,如下:
> x <- 8 + 7
> x
> 15
特別的��,一旦我們創(chuàng)建一個變量,你不再直接得到的輸出�����,此時我們需要輸入對應(yīng)的變量然后再運行結(jié)果。注意����,變量可以是字母,字母數(shù)字而不是數(shù)字���,數(shù)字是不能創(chuàng)建數(shù)值變量的�����、
二�����、編程基礎(chǔ)慨念及R包
1�����、R中的數(shù)據(jù)類型和對象 ? 數(shù)據(jù)類型 R中數(shù)據(jù)類型包括數(shù)值型�����,字符型����,邏輯型,日期型及缺省值�,這個數(shù)據(jù)類型我們在運用數(shù)據(jù)的過程中,大家很容易可以自行了解����,在此不做詳細解釋。
> a <- c(1.8, 4.5) #數(shù)值型
> b <- c(1 + 2i, 3 - 6i) #混合型
> c <- c("zhangsan",”lisi” ) #字符型
? 數(shù)據(jù)對象 R中的數(shù)據(jù)對象主要包括向量(數(shù)字�、整數(shù)等)、列表�、數(shù)據(jù)框和矩陣。讓具體的進行了解:
○1向量 正如上面提到的,一個向量包含同一個類的對象�。但是,你也可以混合不同的類的對象。當(dāng)對象的不同的類混合在一個列表中���,這種效應(yīng)會導(dǎo)致不同類型的對象轉(zhuǎn)換成一個類�。例如:
> qt <- c("Time", 24, "October", TRUE, 3.33) #字符型
> ab <- c(TRUE, 24) #數(shù)值型
> cd <- c(2.5, "May") #字符型
> qt
[1] "Time" "24" "October" "TRUE" "3.33"
> ab
[1] 1 24
> cd
[1] "2.5" "May
注:1�����、檢查任何對象的類,使用class()函數(shù)的功能��。 2���、轉(zhuǎn)換一個數(shù)據(jù)的類��,使用as.()函數(shù)
> class(qt)
>"character"
> bar <- 0:5
> class(bar)
> "integer"
> as.numeric(bar)
> class(bar)
> "numeric"
> as.character(bar)
> class(bar)
> "character"
類似地,您可以自己嘗試改變其他任何的類向量
○2列表 一個列表是一種包含不同的數(shù)據(jù)類型的元素特殊類型的向量����。例如
> my_list <- list(22, "ab", TRUE, 1 + 2i)
> my_list
[[1]]
[1] 22
[[2]]
[1] "ab"
[[3]]
[1] TRUE
[[4]]
[1] 1+2i
可以看出,,列表的輸出不同于一個向量���。這是因為不同類型的所有對象。第一個雙括號[1]顯示了第一個元素包括的索引內(nèi)容�,依次類推。另外的�����,您自己還可以嘗試:
> my_list[[3]]
> [1] TRUE
> my_list[3]
> [[1]]
[1] TRUE
○3矩陣 當(dāng)一個向量與行和列即維度屬性,它變成了一個矩陣���。一個矩陣是由行和列組成的�,讓我們試著創(chuàng)建一個3行2列的矩陣:
> my_matrix <- matrix(1:6, nrow=3, ncol=2)
> my_matrix
[,1] [,2]
[1,] 1 4
[2,] 2 5
[3,] 3 6
> dim(my_matrix)
[1] 3 2
> attributes(my_matrix)
$dim
[1] 3 2
正如你所看到的,一個矩陣的維度你可以通過dim()或attributes()命令獲得��,從一個矩陣中提取一個特定元素,只需使用上面矩陣的形式���。例如
> my_matrix[,2] #提取出第二列
> my_matrix[,1] #提取出第二列
> my_matrix[2,] #提取出第二行
> my_matrix[1,] #提取出第二行
同樣的�,,您還可以從個一個向量開始創(chuàng)建所需要的矩陣��,我們,需要做的是利用dim()分配好維度。如下所示:
> age <- c(23, 44, 15, 12, 31, 16)
> age
[1] 23 44 15 12 31 16
> dim(age) <- c(2,3)
> age
[,1] [,2] [,3]
[1,] 23 15 31
[2,] 44 12 16
> class(age)
[1] "matrix"
另外��,你也可以加入兩個向量使用cbind()和rbind()函數(shù)����。但是,需要確保兩向量相同數(shù)量的元素。如果沒有的話,它將返回NA值����。
> x <- c(1, 2, 3, 4, 5, 6)
> y <- c(20, 30, 40, 50, 60)
> cbind(x, y)
> cbind(x, y)
x y
[1,] 1 20
[2,] 2 30
[3,] 3 40
[4,] 4 50
[5,] 5 60
[6,] 6 70
> class(cbind(x, y))
[1] “matrix
○4數(shù)據(jù)框 這是最常用的一種數(shù)據(jù)類型,它是用來存儲列表數(shù)據(jù)的��。它不同于矩陣���,在一個矩陣中,每一個元素必須有相同的類�。但是,在一個數(shù)據(jù)框里你可以把向量包含不同類別的列表��。這意味著,每一列的數(shù)據(jù)就像一個列表,每次你在R中讀取數(shù)據(jù)將被存儲在一個數(shù)據(jù)框中����。例如:
> df <- data.frame(name = c("ash","jane","paul","mark"), score = c(67,56,87,91))
> df
name score
1 ash 67
2 jane 56
3 paul 87
4 mark 91
> dim(df)
[1] 4 2
> str(df)
'data.frame': 4 obs. of 2 variables:
$ name : Factor w/ 4 levels "ash","jane","mark",..: 1 2 4 3
$ score: num 67 56 87 91
> nrow(df)
[1] 4
> ncol(df)
[1] 2
讓我們解釋一下上面的代碼。df是數(shù)據(jù)框的名字�。dim()返回數(shù)據(jù)框的規(guī)格是4行2列,str()返回的是一個數(shù)據(jù)框的結(jié)構(gòu)�����,nrow()和ncol()返回是數(shù)據(jù)框的行數(shù)和列數(shù)。特別的����,我們需要理解一下R中缺失值的概念,NA代表缺失值�����,這也是預(yù)測建模的關(guān)鍵部分?,F(xiàn)在,我們示例檢查是否一個數(shù)據(jù)集有缺失值�。
> df[1:2,2] <- NA #令前兩行第二列的數(shù)值為NA
> df
name score
1 ash NA
2 jane NA
3 paul 87
4 mark 91
> is.na(df) #檢查整個數(shù)據(jù)集
缺失值和返回邏輯輸出值
name score
[1,] FALSE TRUE
[2,] FALSE TRUE
[3,] FALSE FALSE
[4,] FALSE FALSE
> table(is.na(df)) #返回邏輯值各類的數(shù)量
FALSE TRUE
6 2
> df[!complete.cases(df),] #返回
缺失值所在的行值
name score
1 ash NA
2 jane NA
缺失值的存在嚴重阻礙了我們正常計算數(shù)據(jù)集。例如,因為有兩個缺失值,它不能直接做均值得分��。例如:
mean(df$score)
[1] NA
> mean(df$score, na.rm = TRUE)
[1] 89
na.rm = TRUE告訴R計算時忽略缺失值����,只是計算選定的列中剩余值的均值(得分)。刪除在數(shù)據(jù)中的行和NA����,您可以使用na.omit
> new_df <- na.omit(df)
> new_df
name score
3 paul 87
4 mark 91
2、R中的控制語句
正如它的名字一樣,這樣的語句在編碼中起控制函數(shù)的作用���,寫一個函數(shù)也是一組多個命令自動重復(fù)編碼的過程��。例如:你有10個數(shù)據(jù)集�����,你想找到存在于每一個數(shù)據(jù)集中的“年齡”列����。這可以通過兩種方法,一種需要我們運行一個特定的程序運行10次����,另外一種就需要通過編寫一個控制語句來完成。我們先了解下R中的控制結(jié)構(gòu)簡單的例子:
? If.else�����,這個結(jié)構(gòu)是用來測試一個條件的����,下面是語法:
if (<condition>){
##do something
} else {
##do something
}
例子:
#initialize a variable
N <- 10
#check if this variable * 5 is > 40
if (N * 5 > 40){
print("This is easy!")
} else {
print ("It's not easy!")
}
[1] "This is easy!"
? For語句,這個結(jié)構(gòu)是當(dāng)一個循環(huán)執(zhí)行固定的次數(shù)時使用�����。下面是語法:
for (<search condition>){
#do something
}
Example
#initialize a vector
y <- c(99,45,34,65,76,23)
#print the first 4 numbers of this vector
for(i in 1:4){
print (y[i])
}
[1] 99
[1] 45
[1] 34
[1] 65
? while,語句 它首先測試條件,并只有在條件是正確的時才執(zhí)行,一旦執(zhí)行循環(huán),條件是再次測試�,直到滿足指定的條件然后輸出。下面是語法
#初始化條件
Age <- 12
#檢驗?zāi)挲g是否小于17
while(Age < 17){
print(Age)
Age <- Age + 1 }
[1] 12
[1] 13
[1] 14
[1] 15
[1] 16
當(dāng)然����,還有其他的控制結(jié)構(gòu),但不太常用的比上面的解釋。例如: Repeat 它執(zhí)行一個無限循環(huán) break——它打破循環(huán)的執(zhí)行
next——它允許跳過一個迭代循環(huán) return——它幫助退出函數(shù)
注意:如果你發(fā)現(xiàn)這部分的控制結(jié)構(gòu)難以理解,不用擔(dān)心�����。R語言中來自于眾多人貢獻的包����,會幫助你很多���。
3����、常用的R包 在R的鏡像(CRAN)中����,有超過7800個包可供大家調(diào)用,其中很多包可以用來預(yù)測建模在本文中��,我們在下面會簡單的介紹其中幾個。之前�,我們已經(jīng)解釋了安裝包的方法,大家可以根據(jù)自己的需要去下載安裝。
?導(dǎo)入數(shù)據(jù) R為數(shù)據(jù)的導(dǎo)入進口提供了廣泛的包�����,并且可以接入任何格式的數(shù)據(jù)����。如txt,,csv,,sql等均可快速導(dǎo)入大文件的數(shù)據(jù),。
?數(shù)據(jù)可視化 R同樣可以用來構(gòu)建繪圖命令并且是創(chuàng)建簡單的圖表非常好用���。但是,當(dāng)創(chuàng)建的圖形變得較為復(fù)雜時���,你應(yīng)該安裝ggplot2。
?數(shù)據(jù)操作 R中有很多關(guān)于數(shù)據(jù)操作集合的包���,他們可以做基本的和先進的快速計算��、例如dplyr�����,plyr �,tidyr,lubricate����,stringr等。
?建模學(xué)習(xí)/機器學(xué)習(xí) 對于模型學(xué)習(xí)���,caret包是強大到足以滿足大多創(chuàng)建機器學(xué)習(xí)模型的必要�����。當(dāng)然,您也可以安裝算法包���,例如對于隨機森林,決策樹等等����。
到這里為止,你會覺得對于R的相關(guān)組件都相對熟悉啦�����,從現(xiàn)在開始我們開始介紹一些關(guān)于模型預(yù)測的知識�����。
三���、用R進行數(shù)據(jù)預(yù)處理
從這一節(jié)開始,我們將深入閱讀預(yù)測建模的不同階段�����。對于數(shù)據(jù)的預(yù)處理是非常重要的����,這一階段學(xué)習(xí)將強化我們的對數(shù)據(jù)操作的應(yīng)用����,讓我們在接下來的R中去學(xué)習(xí)和應(yīng)用一下。在本教程中,我們以這個大市場銷售預(yù)測數(shù)據(jù)集為例���。首先�,我們先理解一下數(shù)據(jù)結(jié)構(gòu)���,如下圖:
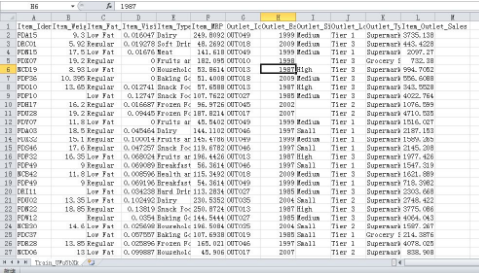
1�����、數(shù)據(jù)集中基礎(chǔ)概念
○1最后一列ItemOutlet_Sales為響應(yīng)變量(因變量y)���,是我們需要做出預(yù)測的���。前面的變量是自變量xi,是用來預(yù)測因變量的��。
○2數(shù)據(jù)集
預(yù)測模型一般是通過訓(xùn)練數(shù)據(jù)集建立����,訓(xùn)練數(shù)據(jù)總是包括反變量;測試數(shù)據(jù):一旦模型構(gòu)建,它在測試數(shù)據(jù)集中的測試是較為準(zhǔn)確的�����,這個數(shù)據(jù)總是比訓(xùn)練數(shù)據(jù)集包含更少數(shù)量的觀察值�,而且是它不包括反應(yīng)變量的。
? 數(shù)據(jù)的導(dǎo)入和基本探索 ○1在使用R語言時一個重要設(shè)置是定義工作目錄�,即設(shè)置當(dāng)前運行路徑(這樣你的全部數(shù)據(jù)和程序都將保存在該目錄下)
#設(shè)定當(dāng)前工作目錄
setwd(“E:/r”)
一旦設(shè)置了目錄,我們可以很容易地導(dǎo)入數(shù)據(jù),使用下面的命令導(dǎo)入csv文件:
#載入數(shù)據(jù)集
train <- read.csv("E:/r/Train_UWu5bXk.csv")
test <- read.csv("E:/r/Test_u94Q5KV.csv")
通過R環(huán)境檢查數(shù)據(jù)是否已成功加載,然后讓我們來探討數(shù)據(jù)
#查看數(shù)據(jù)的維度
> dim(train)
[1] 8523 12
> dim(test)
[1] 5681 11
從結(jié)果我們可以看到訓(xùn)練集有8523行12列數(shù)據(jù)���,測試集有5681行和11列訓(xùn)練數(shù)據(jù),并且這也是正確的�����。測試數(shù)據(jù)應(yīng)該總是少一列的?,F(xiàn)在讓我們深入探索訓(xùn)練數(shù)據(jù)集
#檢查訓(xùn)練集中的變量和類型
> str(train)
'data.frame': 8523 obs. of 12 variables:
$ Item_Identifier : Factor w/ 1559 levels "DRA12","DRA24",..: 157 9 663 1122 1298 759 697 739 441 991 ...
$ Item_Weight : num 9.3 5.92 17.5 19.2 8.93 ...
$ Item_Fat_Content : Factor w/ 5 levels "LF","low fat",..: 3 5 3 5 3 5 5 3 5 5 ...
$ Item_Visibility : num 0.016 0.0193 0.0168 0 0 ...
$ Item_Type : Factor w/ 16 levels "Baking Goods",..: 5 15 11 7 10 1 14 14 6 6 ...
$ Item_MRP : num 249.8 48.3 141.6 182.1 53.9 ...
$ Outlet_Identifier : Factor w/ 10 levels "OUT010","OUT013",..: 10 4 10 1 2 4 2 6 8 3 ...
$ Outlet_Establishment_Year: int 1999 2009 1999 1998 1987 2009 1987 1985 2002 2007 ...
$ Outlet_Size : Factor w/ 4 levels "","High","Medium",..: 3 3 3 1 2 3 2 3 1 1 ...
$ Outlet_Location_Type : Factor w/ 3 levels "Tier 1","Tier 2",..: 1 3 1 3 3 3 3 3 2 2 ...
$ Outlet_Type : Factor w/ 4 levels "Grocery Store",..: 2 3 2 1 2 3 2 4 2 2 ...
$ Item_Outlet_Sales : num 3735 443 2097 732 995 ...
2�����、圖形表示
當(dāng)使用圖表來表示時����,我想大家會更好的了解這些變量。一般來講,我們可以從兩個方面分析數(shù)據(jù):單變量分析和雙變量分析�。對于單變量分析來講較為簡單,在此不做解釋���。我們本文以雙變量分析為例:
(對于可視化,我們將使用ggplot2包���。這些圖可以幫助我們更好理解變量的分布和頻率的數(shù)據(jù)集)
? 首先做出Item_Visibility和Item_Outlet_Sales兩個變量的散點圖
ggplot(train, aes(x= Item_Visibility, y = Item_Outlet_Sales)) +
geom_point(size = 2.5, color="navy") + xlab("Item Visibility") +
ylab("Item Outlet Sales") + ggtitle("Item Visibility vs Item Outlet
Sales")
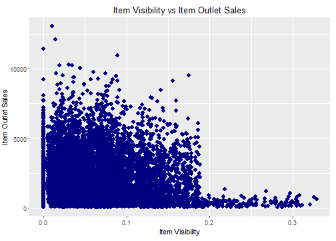
從圖中,我們可以看到大多數(shù)銷售已從產(chǎn)品能見度小于0.2���。這表明item_visibility < 0.2�����,則該變量必須是確定銷售的一個重要因素�����。
? 做出Outlet_Identifier和Item_Outlet_Sales兩個變量的柱狀關(guān)系圖
ggplot(train, aes(Item_Type, Item_Outlet_Sales)) + geom_bar( stat =
"identity") +theme(axis.text.x = element_text(angle = 70, vjust = 0.5,
color = "navy"))ggplot(train, aes(Outlet_Identifier, Item_Outlet_Sales))
+ geom_bar(stat = "identity", color = "purple") +theme(axis.text.x =
element_text(angle = 70, vjust = 0.5, color = "black")) +
ggtitle("Outlets vs Total Sales") + theme_bw()
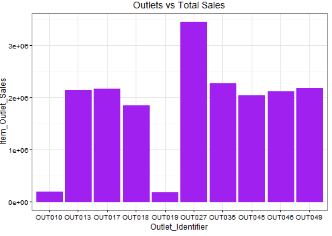
在這里,我們推斷可能是OUT027的銷量影響啦OUT35的銷量緊隨其后�。OUT10和OUT19可能是由于最少的客流量,從而導(dǎo)致最少的出口銷售。
? 做出Outlet_type和Item_Outlet_Sales兩個變量的箱體圖
ggplot(train, aes(Item_Type, Item_Outlet_Sales)) + geom_bar( stat =
"identity") +theme(axis.text.x = element_text(angle = 70, vjust = 0.5,
color = "navy"))

從這個圖表,我們可以推斷出水果和蔬菜最有利于銷售零食數(shù)量的出口��,其次是家用產(chǎn)品�。
? 做出Item_Type和Item_MRP兩個變量的箱線圖 這次我們使用箱線圖來表示,箱線圖的好處在于我們可以看到相應(yīng)變量的異常值和平均偏差水平��。
ggplot(train, aes(Item_Type, Item_MRP)) +geom_boxplot() +ggtitle("Box
Plot") + theme(axis.text.x = element_text(angle = 70, vjust = 0.5, color
= "red")) + xlab("Item Type") + ylab("Item MRP") + ggtitle("Item Type
vs Item MRP")
在圖中�����,,黑色的點就是一個異常值����,盒子里黑色的線是每個項目類型的平均值。
3�����、缺失值處理 缺失值對于自變量和因變量之間的關(guān)系有很大的影響?����,F(xiàn)在,讓我們理解一下缺失值的處理的知識。讓我們來做一些快速的數(shù)據(jù)探索�,首先,我們將檢查數(shù)據(jù)是否有缺失值�����。
> table(is.na(train))
FALSE TRUE
100813 1463
我們可以看出在訓(xùn)練數(shù)據(jù)集中有1463個缺失值���。讓我們檢查這些缺失值的變量在哪里�����,其實很多數(shù)據(jù)科學(xué)家一再建議初學(xué)者在在數(shù)據(jù)探索階段應(yīng)密切關(guān)注缺失值�����。
> colsums(is.na(train))
Item_Identifier Item_Weight
0 1463
Item_Fat_Content Item_Visibility
0 0
Item_Type Item_MRP
0 0
Outlet_Identifier Outlet_Establishment_Year
0 0
Outlet_Size Outlet_Location_Type
0 0
Outlet_Type Item_Outlet_Sales
0 0
因此,我們看到列Item_Weight 有1463個缺失的數(shù)據(jù)��。從這個數(shù)據(jù)我們還可以得到更多的推論:
> summary(train)
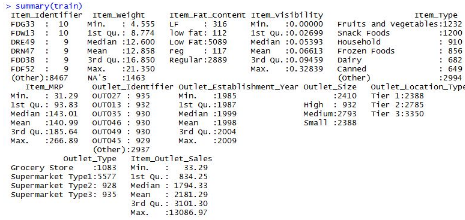
從圖中���,我們可以看到每列的最小值,最大值�����,中位數(shù),平均值���,缺失值的信息等等����。我們看到變量Item_Weight中有缺失值�����,而且Item_Weight是一個連續(xù)變量�����。因此,在這種情況下,我們一般用樣本中變量的均值或中位數(shù)賦值給缺失值�����。計算變量item_weight的均值和中位數(shù)���,這是最常用處理缺失值的的方法���,其他的方法在此不贅述。
我們可以先把兩個數(shù)據(jù)集合并,這樣就不需要編寫?yīng)毩⒕幋a訓(xùn)練和測試數(shù)據(jù)集��,這也會節(jié)省我們的計算時間��。但是合并結(jié)合兩個數(shù)據(jù)框�,我們必須確保他們相同的列,如下:
> dim(train)
[1] 8523 12
> dim(test)
[1] 5681 11
我們知道���,測試數(shù)據(jù)集有個少一列因變量。首先來添加列����,我們可以給這個列賦任何值。一個直觀的方法是我們可以從訓(xùn)練數(shù)據(jù)集中提取銷售的平均值����,并使用$Item_Outlet_Sales作為測試變量的銷售列。不過�,在此,我們讓它簡單化給最后一列賦值為1。
test$Item_Outlet_Sales <- 1
> combi <- rbind(train, test)
接下來我們先來計算中位數(shù)��,選用中位數(shù)是因為它在離散值中很有代表性��。
combi$Item_Weight[is.na(combi$Item_Weight)] <- median(combi$Item_Weight, na.rm = TRUE)
> table(is.na(combi$Item_Weight))
FALSE
14204
4�����、連續(xù)變量和分類變量的處理 在數(shù)據(jù)處理中,對連續(xù)數(shù)據(jù)集和分類變量的非別處理是非常重要的�。在這個數(shù)據(jù)集,我們只有3個連續(xù)變量,其他的是分類變量����。如果你仍然感到困惑,建議你再次使用str()查看數(shù)據(jù)集�。
對于變量Item_Visibility,在上面的圖中可以看到該項中有的能見度為零值,這幾乎是不可行的����。因此,我們考慮將它看成缺失值,用中位數(shù)來處理�。
> combi$Item_Visibility <- ifelse(combi$Item_Visibility == 0,
median(combi$Item_Visibility)
現(xiàn)在讓我們繼續(xù)處理一下分類變量。在初步的數(shù)據(jù)探索中,我們看到有錯誤的水平變量需要糾正���。
levels(combi$Outlet_Size)[1] <- "Other"
> library(plyr)
> combi$Item_Fat_Content <- revalue(Combi$Item_Fat_Content,c("LF" = "Low Fat", "reg" = "Regular")) #將源數(shù)據(jù)中“LF”重命名為“Low Fat”
>combi$Item_Fat_Content <- revalue(Combi$Item_Fat_Content, c("low fat" = "Low Fat")) #將源數(shù)據(jù)中“l(fā)ow fat”重命名為“Low Fat”
> table(combi$Item_Fat_Content) #計算各水平下的頻數(shù)
Low Fat Regular
9185 5019
使用上面的命令,我們指定的名稱“others”為其他未命名的變量�����,簡要劃分了Item_Fat_Content的等級�����。
5����、特征值變量計算
現(xiàn)在我們已經(jīng)進入了大數(shù)據(jù)時代,很多時候需要大量的數(shù)據(jù)算法計算����,但是之前所選出的變量不一定會和模型擬合的效果很好。,所以我們需要提取新的變量���,提供盡可能多的“新”的信息來幫助模型做出更準(zhǔn)確的預(yù)測����。以合并后的數(shù)據(jù)集為例����,你覺得哪些因素)可能會影響Item_Outlet_Sales��?
? 關(guān)于商店種類變量計算 在源數(shù)據(jù)中有10個不同的門店��,門店的數(shù)目越多�����,說明某種商品更容易在這個商店中售出。
> library(dplyr)
> a <- combi%>%
group_by(Outlet_Identifier)%>%
tally() #用管道函數(shù)對門店按編碼分類計數(shù)
> head(a)
Source: local data frame [6 x 2] Outlet_Identifier n
(fctr) (int)
1 OUT010 925
2 OUT013 1553
3 OUT017 1543
4 OUT018 1546
5 OUT019 880
6 OUT027 1559
> names(a)[2] <- "Outlet_Count"
> combi <- full_join(a, combi, by = "Outlet_Identifier")
注:管道函數(shù)的思路�,將左邊的值管道輸出為右邊調(diào)用的函數(shù)的第一個參數(shù)。
? 商品種類計算 同樣的,我們也可以計算商品種類的信息���,這樣我們可以通過結(jié)果看到商品在各家商店出現(xiàn)的頻率���。
> b <- combi%>%。
group_by(Item_Identifier)%>%
tally()
> names(b)[2] <- "Item_Count"
> b
Item_Identifier Item_Count #數(shù)量較多不一一列舉
Source: local data frame [1,559 x 2]
Item_Identifier Item_Count
(fctr) (int)
1 DRA12 9
2 DRA24 10
3 DRA59 10
4 DRB01 8
5 DRB13 9
6 DRB24 8
7 DRB25 10
8 DRB48 9
9 DRC01 9
10 DRC12 8
.. ... ...
> combi <- merge(b, combi, by = “Item_Identifier”)
? 商店的成立時間的變量探索 我們假設(shè)商店的成立時間越久���,該商店的客流量和產(chǎn)品銷量越會越多���。
> c <- combi%>%
select(Outlet_Establishment_Year)%>%
mutate(Outlet_Year = 2013 - combi$Outlet_Establishment_Year)
> head(c)
Outlet_Establishment_Year Outlet_Year
1 1999 14
2 2009 4
3 1999 14
4 1998 15
5 1987 26
6 2009 4
> combi <- full_join(c, combi)
以第一個年份為例,這表明機構(gòu)成立于1999年����,已有14年的歷史(以2013年為截止年份)。 注:mutate函數(shù)�����,是對已有列進行數(shù)據(jù)運算并添加為新列����。
? 商品所屬類型的相關(guān)計算
通過對商品所屬類型的計算����,我們可以從其中發(fā)現(xiàn)人們的消費趨勢���。從數(shù)據(jù)中們可以看出仔細看商品標(biāo)注DR的���,大多是可以吃的食物。對于FD���,大多是屬于飲品類的��。同樣的我們注意到到NC類��,可能是生活用品(非消耗品)�����,但是NC類中的所標(biāo)注較為復(fù)雜。于是�����,我們將把這些變量提取出來�,并放到一個新變量中����。在這里我將使用substr()和gsub()函數(shù)來實現(xiàn)提取和重命名變量���。
> q <- substr(combi$Item_Identifier,1,2) #字符中的
特征值識別為FD和DR
> q <- gsub("FD","Food",q) #將數(shù)據(jù)中FD標(biāo)記為Food
> q <- gsub("DR","Drinks",q) #將數(shù)據(jù)中DR標(biāo)記為Drinks
> q <- gsub("NC","Non-Consumable",q) #將數(shù)據(jù)中NC標(biāo)Non-Consumable
> table(q)
Drinks Food Non-Consumable
1317 10201 2686
> combi$Item_Type_New <- q #將處理過的變量類型命名為Item_Type_New
當(dāng)然�,你也可以試著去增加一些新變量幫助構(gòu)建更好的模型�����,但是���,增加新變量時必須使它與其他的變量之間是不相關(guān)的��。如果你不確定與其他變量之間是否存在相關(guān)關(guān)系��,可以通過函數(shù)cor()來進行判斷�。
? 對字符變量進行編碼 ○1標(biāo)簽編碼
這一部分的任務(wù)是將字符型的標(biāo)簽進行編碼�����,例如在在我們的數(shù)據(jù)集中,變量Item_Fat_Content有2個級別低脂肪和常規(guī)�,我們將低脂編碼為0和常規(guī)型的編碼為1
。因為這樣能夠幫助我們進行定量的分析�����。 我們可以通過ifelse語句來實現(xiàn)。
> combi$Item_Fat_Content <- ifelse(combi$Item_Fat_Content == "Regular",1,0) # 將低脂編碼為0和常規(guī)型的編碼為1
○2獨熱編碼 獨熱編碼即 One-Hot
編碼�,又稱一位有效編碼,其方法是使用N位狀態(tài)寄存器來對N個狀態(tài)進行編碼��,每個狀態(tài)都由有獨立的寄存器位�����,并且在任意時候�,其中只有一位有效。例如:變量Outlet_
Location_Type�����。它有三個層次在獨熱編碼中���,,將創(chuàng)建三個不同變量1和0組成�����。1將代表變量存在,,0代表變量不存在�。如下::
sample <- select(combi, Outlet_Location_Type)
> demo_sample <- data.frame(model.matrix(~.-1,sample))
> head(demo_sample)
Outlet_Location_TypeTier.1 Outlet_Location_TypeTier.2 Outlet_Location_TypeTier.3
1 1 0 0
2 0 0 1
3 1 0 0
4 0 0 1
5 0 0 1
6 0 0 1
這是一個獨熱編碼的示范��。希望你現(xiàn)在已經(jīng)理解這個概念?�,F(xiàn)在這們將這種技術(shù)也適用于我們的數(shù)據(jù)集分類變量中(不含ID變量)����。
>library(dummies)
>combi <- dummy.data.frame(combi, names = c('Outlet_Size','Outlet_Location_Type','Outlet_Type', 'Item_Type_New'), sep='_')
以上���,我們介紹了兩種不同方法在R中去做獨熱編碼�,我們可以檢查一下編碼是否已經(jīng)完成
> str (combi)
$ Outlet_Size_Other : int 0 1 1 0 1 0 0 0 0 0 ...
$ Outlet_Size_High : int 0 0 0 1 0 0 0 0 0 0 ...
$ Outlet_Size_Medium : int 1 0 0 0 0 0 1 1 0 1 ...
$ Outlet_Size_Small : int 0 0 0 0 0 1 0 0 1 0 ...
$ Outlet_Location_Type_Tier 1 : int 1 0 0 0 0 0 0 0 1 0 ...
$ Outlet_Location_Type_Tier 2 : int 0 1 0 0 1 1 0 0 0 0 ...
$ Outlet_Location_Type_Tier 3 : int 0 0 1 1 0 0 1 1 0 1 ...
$ Outlet_Type_Grocery Store : int 0 0 1 0 0 0 0 0 0 0 ...
$ Outlet_Type_Supermarket Type1: int 1 1 0 1 1 1 0 0 1 0 ...
$ Outlet_Type_Supermarket Type2: int 0 0 0 0 0 0 0 1 0 0 ...
$ Outlet_Type_Supermarket Type3: int 0 0 0 0 0 0 1 0 0 1 ...
$ Item_Outlet_Sales : num 1 3829 284 2553 2553 ...
$ Year : num 14 11 15 26 6 9 28 4 16 28 ...
$ Item_Type_New_Drinks : int 1 1 1 1 1 1 1 1 1 1 ...
$ Item_Type_New_Food : int 0 0 0 0 0 0 0 0 0 0 ...
$ Item_Type_New_Non-Consumable : int 0 0 0 0 0 0 0 0 0 0 ...
我們可以看出獨熱編碼之后�,之前的變量是已經(jīng)自動被移除了數(shù)據(jù)集。
四�����、用機器學(xué)習(xí)方法進行預(yù)測建模
在進行構(gòu)造數(shù)據(jù)模型前�,我們將刪除之前已經(jīng)被轉(zhuǎn)過的原始變量,可以通過使用dplyr包中的select()實現(xiàn)��,如下:
> combi <- select(combi, -c(Item_Identifier, Item_Fat_Content �����,Outlet_Identifier,, Outlet_Establishment_Year,Item_Type))
> str(combi)
在本節(jié)中,我將介紹回歸���、決策樹和隨機森林等算法���。這些算法的詳細解釋已經(jīng)超出了本文的范圍��,如果你想詳細的了解���,推薦大家看機器學(xué)習(xí)的相關(guān)書籍。現(xiàn)在我們要將兩個數(shù)據(jù)集分開��,以便我們來進行預(yù)測建模����。如下:
> new_train <- combi[1:nrow(train),]
> new_test <- combi[-(1:nrow(train)),]
1、多元線性回歸
使用多元回歸建模時�,一般用于響應(yīng)變量(因變量)是連續(xù)型和可供預(yù)測變量有很多時。如果它因變量被分類,我們一般會使用邏輯回歸�����。在我們做回歸前�,我們先來了解一些回歸的基本假設(shè):
? 在響應(yīng)變量和自變量之間存在某種線性關(guān)系; ? 各個自變量之間是不相關(guān)的���,如果存在相關(guān)關(guān)系�,我們稱這個模型出現(xiàn)了多重共線性��。 ?
誤差項也是要求不相關(guān)的�����。否則,它將導(dǎo)致模型出現(xiàn)自相關(guān)��。 ? 誤差項必須有恒定方差����。否則,它將導(dǎo)致模型出現(xiàn)異方差性。
在R中我們使用lm()函數(shù)來做回歸��,如下:
linear_model <- lm(Item_Outlet_Sales ~ ., data = new_train) #構(gòu)建模型
> summary(linear_model)
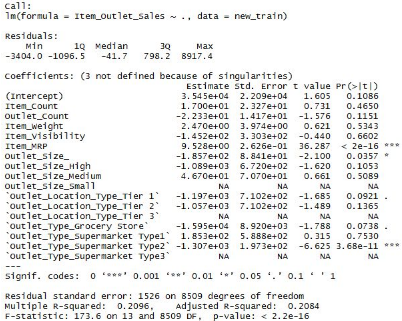
調(diào)整后的R2可以很好的衡量一個回歸模型的擬合優(yōu)度����。R2越高說明模型擬合的越好從上圖可以看出adjusted R2=
0.2084。這意味著我們擬合的這個模型很不理想�����。而且可以p值看出這些新變量例如Item count, Outlet Count 和
Item_Type_New.對于我們的模型構(gòu)造而言并沒有什么幫助�,因為它們的sign.遠小于0.05的顯著性水平。對模型重要的變量是p值小于0.05的變量,也就是上圖中后面帶有*的變量���。
另外�,我們知道變量之間存在相關(guān)性����,會影響模型的準(zhǔn)確性,我們可以利用cor()函數(shù)來看一下各變量之間的相關(guān)關(guān)系�。如下: cor(new_train)
另外,您還可以使用corrplot包來做相關(guān)系數(shù),如下的程序就幫助我們找到一個共線性很強的兩個變量
cor(new_train$Outlet_Count, new_train$`Outlet_Type_Grocery Store`)
[1] -0.9991203
可以看出變量Outlet_Count與變量Outlet_Type_Grocery
Store成高度負相關(guān)關(guān)系���。另外�,我們通過剛才的分析發(fā)現(xiàn)了模型中的一些問題: ? 模型中有相關(guān)關(guān)系的變量存在��; ?
我們做了獨熱編碼編碼和標(biāo)簽編碼�����,但從結(jié)果來看����,通過創(chuàng)建虛擬變量對于這個線性回歸模型的創(chuàng)建意義不大。 ?
創(chuàng)建的新變量對于回歸模型的擬合也沒有很大影響�����。
接下來,我們嘗試創(chuàng)建不含編碼和新變量的較大的回歸模型��。如下:
#載入數(shù)據(jù)
train <- read.csv("E:/r/Train_UWu5bXk.csv")
test <- read.csv("E:/r/Test_u94Q5KV.csv")
> test$Item_Outlet_Sales <- 1 #給測試樣本中的響應(yīng)變量賦值
#合并訓(xùn)練集和測試集
> combi <- rbind(train, test)
#impute missing value in Item_Weight
> combi$Item_Weight[is.na(combi$Item_Weight)] <- median(combi$Item_Weight, na.rm = TRUE)
#用中位數(shù)處理
缺失值
> combi$Item_Visibility <- ifelse(combi$Item_Visibility == 0, median(combi$Item_Visibility), combi$Item_Visibility)
#給變量 Outlet_Size整理等級水平
> levels(combi$Outlet_Size)[1] <- "Other"
#給變量Item_Fat_Content重命名
> library(plyr)
> combi$Item_Fat_Content <- revalue(combi$Item_Fat_Content,c("LF" = "Low Fat", "reg" ="Regular"))
> combi$Item_Fat_Content <- revalue(combi$Item_Fat_Content, c("low fat" = "Low Fat"))
#創(chuàng)建一個新列
> combi$Year <- 2013 - combi$Outlet_Establishment_Year
#刪除模型中不需要的變量
> library(dplyr)
> combi <- select(combi, -c(Item_Identifier, Outlet_Identifier, Outlet_Establishment_Year))
#拆分數(shù)據(jù)集
> new_train <- combi[1:nrow(train),]
> new_test <- combi[-(1:nrow(train)),]
#
線性回歸
> linear_model <- lm(Item_Outlet_Sales ~ ., data = new_train)
> summary(linear_model)
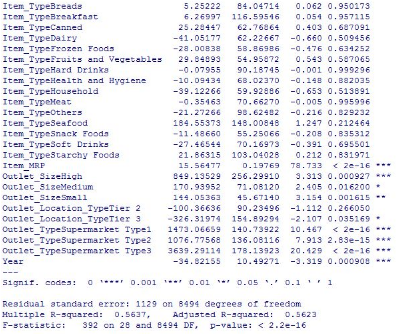
上圖中可以看到��,調(diào)整后的R2= 0.5623�。這告訴我們,有時只需你的計算過程簡單一些可能會得到更精確的結(jié)果���。讓我們從一些回歸圖中去發(fā)現(xiàn)一些能夠提高模型精度的辦法���。
> par(mfrow=c(2,2))
> plot(linear_model)
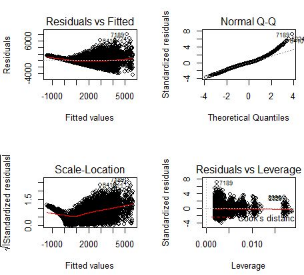
從左上的第一個殘差擬合圖中我們可以看出實際值與預(yù)測值之間殘差不是恒定的,這說明該模型中存在著異方差�����。解決異方差性的一個常見的做法就是對響應(yīng)變量取對數(shù)(減少誤差)�。
>linear_model <- lm(log(Item_Outlet_Sales) ~ ., data = new_train)
> summary(linear_model)
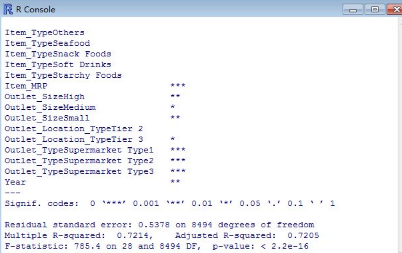
可以看出調(diào)整后的R2= 0.72,說明模型的構(gòu)建有了顯著的改善��,我們可以再做一次擬合回歸圖
> par(mfrow=c(2,2))
> plot(linear_model)
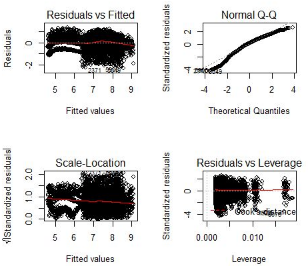
上圖中���,殘差值與擬合值之間已經(jīng)沒有了長期趨勢����,說明該模型的擬合效果理想。我們也經(jīng)常用RMSE來衡量模型的好壞�����,并且我們可以通過這個值與其他算法相比較���。如下所示
install.packages("E:/r/ Metrics_0.1.1.zip ")
> library(Metrics)
> rmse(new_train$Item_Outlet_Sales, exp(linear_model$fitted.values))
[1] 1140.004
接下來讓我們進行決策樹算法來改善我們的RMSE得分
2����、決策樹
決策樹算法一般優(yōu)于線性回歸模型�����,我們簡單介紹一下
����,在機器學(xué)習(xí)中決策樹是一個預(yù)測模型。他代表的是對象屬性與對象值之間的一種映射關(guān)系����。樹中每個節(jié)點表示某個對象,而每個分叉路徑則代表的某個可能的屬性值����,而每個葉結(jié)點則對應(yīng)從根節(jié)點到該葉節(jié)點所經(jīng)歷的路徑所表示的對象的值���。
在R中,決策樹算法的實現(xiàn)可以使用rpart包。此外,我們將使用caret包做交叉驗證��。通過交叉驗證技術(shù)來構(gòu)建較復(fù)雜的模型時可以使模型不容易出現(xiàn)過度擬合的情況���。(關(guān)于交叉驗證讀者可自行查閱)另外,,決策樹使用參數(shù)CP來衡量訓(xùn)練集的復(fù)雜性和準(zhǔn)確性��。參數(shù)較小的CP值可能將導(dǎo)致更大的決策樹,這也可能會出現(xiàn)過度擬合的模型���。相反,參數(shù)大的CP值也導(dǎo)致擬合不充分的模型�����,也就是我們不能準(zhǔn)確的把握所需變量的信息���。以下我們選用五折交叉驗證法來找出具有最優(yōu)CP的模型。
# 加載所需的包
> library(rpart)
> library(e1071)
> library(rpart.plot)
> library(caret)
#設(shè)置
決策樹的控制參數(shù)
> fitControl <- trainControl(method = "cv", number = 5) #選用五折交叉驗證的方法
> cartGrid <- expand.grid(.cp=(1:50)*0.01)
#decision tree
> tree_model <- train(Item_Outlet_Sales ~ ., data = new_train,
method = "rpart", trControl = fitControl, tuneGrid = cartGrid)
> print(tree_model)
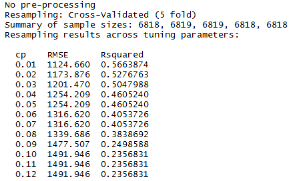
從上圖可以看出�����,參數(shù)cp = 0.01所對應(yīng)的RMSE最小,在此我們只提供了部分的數(shù)據(jù)�,你可以在R consle中查詢到更多信息。
main_tree <- rpart(Item_Outlet_Sales ~ ., data = new_train, control = rpart.control(cp=0.01)) #在cp=0.01下構(gòu)造
決策樹
prp(main_tree) #輸出決策樹
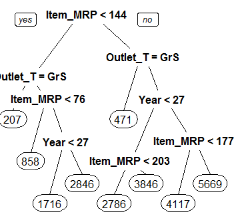
以上就是我們決策樹模型的結(jié)構(gòu),而且我們可以明顯看出變量Item_MRP是最重要的根節(jié)點,作為最重要的變量也就是根節(jié)點����,來劃分預(yù)測未來的銷售量。此外讓我們檢查一下這個模型的RMSE是否有所改善��。
> pre_score <- predict(main_tree, type = "vector")
> rmse(new_train$Item_Outlet_Sales, pre_score) #計算
均方根誤差
[1] 1102.774
可以看出���,通過決策樹做出的誤差為1102.774,比線性回歸得出的誤差小���。說明這種方法更優(yōu)一些��。當(dāng)然你也可以通過調(diào)參數(shù)來進一步優(yōu)化降低這個誤差(如使用十折交叉驗證的方法)
3�����、隨機森林
隨機森林顧名思義����,是用隨機的方式建立一個森林���,森林里面有很多的決策樹組成�,隨機森林的每一棵決策樹之間是沒有關(guān)聯(lián)的。在得到森林之后��,當(dāng)有一個新的輸入樣本進入的時候���,就讓森林中的每一棵決策樹分別進行一下判斷��,看看這個樣本應(yīng)該屬于哪一類(對于分類算法)�,然后看看哪一類被選擇最多���,就預(yù)測這個樣本為那一類。隨機森林算法可以很好的處理缺失值,異常值和其他非線性的數(shù)據(jù)�����,其他相關(guān)知識讀者可以自行查閱����。
#加載
隨機森林算法的包
> library(randomForest)
#設(shè)置參數(shù)
> control <- trainControl(method = "cv", number = 5)
#模型構(gòu)建
> rf_model <- train(Item_Outlet_Sales ~ ., data = new_train,
method = "parRF", trControl = control, prox = TRUE, allowParallel =
TRUE)
#通過結(jié)果選擇參數(shù)
> print(rf_model)
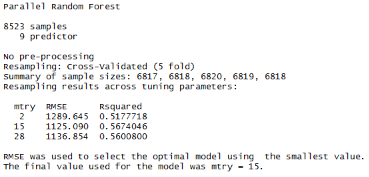
在以上的語句中,可以看到=“parRF”�,這是隨機森林的并行實現(xiàn)。這個包讓你在計算隨機森林時花費較短的時間��。或者,你也可以嘗試使用rf方法作為標(biāo)準(zhǔn)隨機森林的功能�。從以上結(jié)果中我們選擇RMSE最小的即選擇mtry
= 15,我們嘗試用1000棵樹做計算����,如下:
> forest_model <- randomForest(Item_Outlet_Sales ~ ., data = new_train, mtry = 15, ntree = 1000) #
隨機森林模型
> print(forest_model)
> varImpPlot(forest_model)
這個模型中可得出RMSE = 1132.04,并沒有改進決策樹模型���。另外���,隨機森林的一個功能是可以展示重要變量。我們通過下圖可以看到最重要的變量是Item_MRP(通過決策樹算法也已經(jīng)表示出來)���。
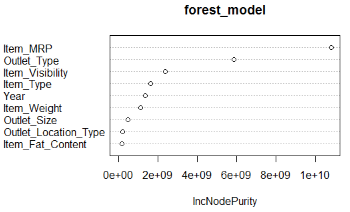
顯然���,這個模型可以進一步進行嘗試調(diào)優(yōu)參數(shù)的。同時,讓我們用RMSE最好的決策樹來對測試集做擬合���。如下所示:
>main_predict <- predict(main_tree, newdata = new_test, type = "vector")
> sub_file <- data.frame(Item_Identifier = test$Item_Identifier,
Outlet_Identifier = test$Outlet_Identifier, Item_Outlet_Sales =
main_predict)
> write.csv(sub_file, 'Decision_tree_sales.csv')
當(dāng)預(yù)測其他樣本外數(shù)據(jù),我們可以得出RMSE是1174.33����,這個模型是也可以通過調(diào)參數(shù)達到更優(yōu)的��,以下列出幾種方法:
? 本例我們沒有使用標(biāo)簽編碼和獨熱編碼,希望你可以嘗試以下編碼來做隨機森林模型����。 ? 調(diào)整相關(guān)的參數(shù)。 ? 使用Gradient
Boosting來做模型���。 ? 建立一個新的整體模型���。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認證考試,點擊>>>
“CDA報名”
了解CDA考試詳情����;
? 想學(xué)習(xí)CDA考試教材,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫,點擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量���,點擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330