Python實(shí)現(xiàn)的隨機(jī)森林算法與簡(jiǎn)單總結(jié)
本文實(shí)例講述了Python實(shí)現(xiàn)的隨機(jī)森林算法�����。分享給大家供大家參考,具體如下:
隨機(jī)森林是數(shù)據(jù)挖掘中非常常用的分類預(yù)測(cè)算法�,以分類或回歸的決策樹為基分類器�。算法的一些基本要點(diǎn):
*對(duì)大小為m的數(shù)據(jù)集進(jìn)行樣本量同樣為m的有放回抽樣�����;
*對(duì)K個(gè)特征進(jìn)行隨機(jī)抽樣��,形成特征的子集��,樣本量的確定方法可以有平方根���、自然對(duì)數(shù)等�����;
*每棵樹完全生成���,不進(jìn)行剪枝�;
*每個(gè)樣本的預(yù)測(cè)結(jié)果由每棵樹的預(yù)測(cè)投票生成(回歸的時(shí)候�,即各棵樹的葉節(jié)點(diǎn)的平均)
出于個(gè)人研究和測(cè)試的目的,基于經(jīng)典的Kaggle 101泰坦尼克號(hào)乘客的數(shù)據(jù)集����,建立模型并進(jìn)行評(píng)估��。
泰坦尼克號(hào)的沉沒(méi)���,是歷史上非常著名的海難。突然感到��,自己面對(duì)的不再是冷冰冰的數(shù)據(jù)���,而是用數(shù)據(jù)挖掘的方法�,去研究具體的歷史問(wèn)題�,也是饒有興趣。言歸正傳����,模型的主要的目標(biāo),是希望根據(jù)每個(gè)乘客的一系列特征���,如性別��、年齡�����、艙位�����、上船地點(diǎn)等�,對(duì)其是否能生還進(jìn)行預(yù)測(cè),是非常典型的二分類預(yù)測(cè)問(wèn)題���。數(shù)據(jù)集的字段名及實(shí)例如下:
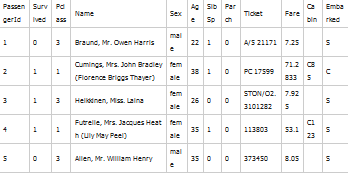
值得說(shuō)明的是���,SibSp是指sister brother spouse,即某個(gè)乘客隨行的兄弟姐妹��、丈夫����、妻子的人數(shù),Parch指parents,children
下面給出整個(gè)數(shù)據(jù)處理及建模過(guò)程���,基于ubuntu+python 3.4( anaconda科學(xué)計(jì)算環(huán)境已經(jīng)集成一系列常用包��,pandas numpy sklearn等��,這里強(qiáng)烈推薦)
懶得切換輸入法��,寫的時(shí)候主要的注釋都是英文,中文的注釋是后來(lái)補(bǔ)充的:-)
# -*- coding: utf-8 -*-
"""
@author: kim
"""
frommodelimport*#載入基分類器的代碼
#
ETL:same procedure to training set and test set
training=pd.read_csv('train.csv',index_col=0)
test=pd.read_csv('test.csv',index_col=0)
SexCode=pd.
DataFrame([1,0],index=['female','male'],columns=['Sexcode']) #將性別轉(zhuǎn)化為01
training=training.join(SexCode,how='left',on=training.Sex)
training=training.drop(['Name','Ticket','Embarked','Cabin','Sex'],axis=1)#刪去幾個(gè)不參與建模的變量��,包括姓名、船票號(hào)����,船艙號(hào)
test=test.join(SexCode,how='left',on=test.Sex)
test=test.drop(['Name','Ticket','Embarked','Cabin','Sex'],axis=1)
#MODEL FITTING
#===============PARAMETER AJUSTMENT============
min_leaf=1
min_dec_gini=0.0001
n_trees=5
n_fea=int(math.sqrt(len(training.columns)-1))
#==============================================
'''''
BEST SCORE:0.83
min_leaf=30
min_dec_gini=0.001
n_trees=20
'''
#ESSEMBLE BY RANDOM FOREST
FOREST={}
tmp=list(training.columns)
tmp.pop(tmp.index('Survived'))
fortinrange(n_trees):
# fea=[]
feasample=feaList.sample(n=n_fea,replace=False)#select feature
fea=feasample.tolist()
fea.append('Survived')
# feaNew=fea.append(target)
subset=training.sample(n=len(training),replace=True)#generate the dataset with replacement
subset=subset[fea]
# print(str(t)+' Classifier built on feature:')
# print(list(fea))
FOREST[t]=tree_grow(subset,'Survived',min_leaf,min_dec_gini)#save the tree
#MODEL PREDICTION
#======================
currentdata=training
output='submission_rf_20151116_30_0.001_20'
#======================
prediction={}
forrincurrentdata.index:#a row
prediction_vote={1:0,0:0}
row=currentdata.get(currentdata.index==r)
forninrange(n_trees):
tree_dict=FOREST[n]#a tree
p=model_prediction(tree_dict,row)
prediction_vote[p]+=1
vote=pd.
Series(prediction_vote)
prediction[r]=list(vote.order(ascending=False).index)[0]#the vote result
result=pd.
Series(prediction,name='Survived_p')
#del prediction_vote
#del prediction
#result.to_csv(output)
t=training.join(result,how='left')
accuracy=round(len(t[t['Survived']==t['Survived_p']])/len(t),5)
print(accuracy)
上述是隨機(jī)森林的代碼,如上所述�����,隨機(jī)森林是一系列決策樹的組合�,決策樹每次分裂,用Gini系數(shù)衡量當(dāng)前節(jié)點(diǎn)的“不純凈度”�����,如果按照某個(gè)特征的某個(gè)分裂點(diǎn)對(duì)數(shù)據(jù)集劃分后��,能夠讓數(shù)據(jù)集的Gini下降最多(顯著地減少了數(shù)據(jù)集輸出變量的不純度)���,則選為當(dāng)前最佳的分割特征及分割點(diǎn)���。代碼如下:
# -*- coding: utf-8 -*-
"""
@author: kim
"""
#import sklearn as sk
importmath
deftree_grow(dataframe,target,min_leaf,min_dec_gini):
tree={}#renew a tree
is_not_leaf=(len(dataframe)>min_leaf)
ifis_not_leaf:
fea,sp,gd=best_split_col(dataframe,target)
ifgd>min_dec_gini:
tree['fea']=fea
tree['val']=sp
# dataframe.drop(fea,axis=1) #1116 modified
l,r=dataSplit(dataframe,fea,sp)
l.drop(fea,axis=1)
r.drop(fea,axis=1)
tree['left']=tree_grow(l,target,min_leaf,min_dec_gini)
tree['right']=tree_grow(r,target,min_leaf,min_dec_gini)
else:#return a leaf
returnleaf(dataframe[target])
else:
returnleaf(dataframe[target])
returntree
defleaf(class_lable):
tmp={}
foriinclass_lable:
ifiintmp:
tmp[i]+=1
else:
tmp[i]=1
s.sort(ascending=False)
returns.index[0]
defgini_cal(class_lable):
p_1=sum(class_lable)/len(class_lable)
p_0=1-p_1
gini=1-(pow(p_0,2)+pow(p_1,2))
returngini
defdataSplit(dataframe,split_fea,split_val):
left_node=dataframe[dataframe[split_fea]<=split_val]
right_node=dataframe[dataframe[split_fea]>split_val]
returnleft_node,right_node
defbest_split_col(dataframe,target_name):
best_fea=''#modified 1116
best_split_point=0
col_list=list(dataframe.columns)
col_list.remove(target_name)
gini_0=gini_cal(dataframe[target_name])
n=len(dataframe)
gini_dec=-99999999
forcolincol_list:
node=dataframe[[col,target_name]]
unique=node.groupby(col).count().index
forsplit_pointinunique:#unique value
left_node,right_node=dataSplit(node,col,split_point)
iflen(left_node)>0andlen(right_node)>0:
gini_col=gini_cal(left_node[target_name])*(len(left_node)/n)+gini_cal(right_node[target_name])*(len(right_node)/n)
if(gini_0-gini_col)>gini_dec:
gini_dec=gini_0-gini_col#decrease of impurity
best_fea=col
best_split_point=split_point
#print(col,split_point,gini_0-gini_col)
returnbest_fea,best_split_point,gini_dec
defmodel_prediction(model,row):#row is a df
fea=model['fea']
val=model['val']
left=model['left']
right=model['right']
ifrow[fea].tolist()[0]<=val:#get the value
branch=left
else:
branch=right
if('dict'instr(type(branch) )):
prediction=model_prediction(branch,row)
else:
prediction=branch
returnprediction
實(shí)際上,上面的代碼還有很大的效率提升的空間�,數(shù)據(jù)集不是很大的情況下,如果選擇一個(gè)較大的輸入?yún)?shù),例如生成100棵樹�,就會(huì)顯著地變慢;同時(shí)���,將預(yù)測(cè)結(jié)果提交至kaggle進(jìn)行評(píng)測(cè)����,發(fā)現(xiàn)在測(cè)試集上的正確率不是很高�����,比使用sklearn里面相應(yīng)的包進(jìn)行預(yù)測(cè)的正確率(0.77512)要稍低一點(diǎn)
:-( 如果要提升準(zhǔn)確率��,兩個(gè)大方向: 構(gòu)造新的特征�;調(diào)整現(xiàn)有模型的參數(shù)。
這里是拋磚引玉�,歡迎大家對(duì)我的建模思路和算法的實(shí)現(xiàn)方法提出修改意見(jiàn)。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試�����,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情����;
? 想學(xué)習(xí)CDA考試教材�,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫(kù),點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情�����;
? 想了解CDA考試含金量���,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330