Python實(shí)現(xiàn)曲線點(diǎn)抽稀算法的示例
本文介紹了Python實(shí)現(xiàn)曲線點(diǎn)抽稀算法的示例�,分享給大家,具體如下:
目錄
何為抽稀
道格拉斯-普克(Douglas-Peuker)算法
垂距限值法
最后
正文
何為抽稀
在處理矢量化數(shù)據(jù)時(shí)�����,記錄中往往會(huì)有很多重復(fù)數(shù)據(jù)����,對(duì)進(jìn)一步數(shù)據(jù)處理帶來諸多不便���。多余的數(shù)據(jù)一方面浪費(fèi)了較多的存儲(chǔ)空間�,另一方面造成所要表達(dá)的圖形不光滑或不符合標(biāo)準(zhǔn)��。因此要通過某種規(guī)則���,在保證矢量曲線形狀不變的情況下���,
最大限度地減少數(shù)據(jù)點(diǎn)個(gè)數(shù),這個(gè)過程稱為抽稀。
通俗的講就是對(duì)曲線進(jìn)行采樣簡(jiǎn)化����,即在曲線上取有限個(gè)點(diǎn)�����,將其變?yōu)檎劬€����,并且能夠在一定程度保持原有形狀。比較常用的兩種抽稀算法是:道格拉斯-普克(Douglas-Peuker)算法和垂距限值法�。
道格拉斯-普克(Douglas-Peuker)算法
Douglas-Peuker算法(DP算法)過程如下:
1、連接曲線首尾兩點(diǎn)A�、B;
2����、依次計(jì)算曲線上所有點(diǎn)到A�、B兩點(diǎn)所在曲線的距離�����;
3����、計(jì)算最大距離D�,如果D小于閾值threshold,則去掉曲線上出A、B外的所有點(diǎn)�����;如果D大于閾值threshold,則把曲線以最大距離分割成兩段�;
4、對(duì)所有曲線分段重復(fù)1-3步驟��,知道所有D均小于閾值�����。即完成抽稀����。
這種算法的抽稀精度與閾值有很大關(guān)系,閾值越大���,簡(jiǎn)化程度越大�,點(diǎn)減少的越多�����;反之簡(jiǎn)化程度越低�����,點(diǎn)保留的越多��,形狀也越趨于原曲線���。
下面是Python代碼實(shí)現(xiàn):
# -*- coding: utf-8 -*-
"""------------------------------------------------- File Name: DouglasPeuker Description : 道格拉斯-普克抽稀算法 Author : J_hao date: 2017/8/16------------------------------------------------- Change Activity: 2017/8/16: 道格拉斯-普克抽稀算法-------------------------------------------------"""
from __future__ import division
from math import sqrt, pow
__author__ = 'J_hao'
THRESHOLD = 0.0001 # 閾值
def point2LineDistance(point_a, point_b, point_c):
""" 計(jì)算點(diǎn)a到點(diǎn)b c所在直線的距離 :param point_a: :param point_b: :param point_c: :return: """
# 首先計(jì)算b c 所在直線的斜率和截距
if point_b[0] == point_c[0]:
return 9999999
slope = (point_b[1] - point_c[1]) / (point_b[0] - point_c[0])
intercept = point_b[1] - slope * point_b[0]
# 計(jì)算點(diǎn)a到b c所在直線的距離
distance = abs(slope * point_a[0] - point_a[1] + intercept) / sqrt(1 + pow(slope, 2))
return distance
class DouglasPeuker(object):
def__init__(self):
self.threshold = THRESHOLD
self.qualify_list = list()
self.disqualify_list = list()
def diluting(self, point_list):
""" 抽稀 :param point_list:二維點(diǎn)列表 :return: """
if len(point_list) < 3:
self.qualify_list.extend(point_list[::-1])
else:
# 找到與收尾兩點(diǎn)連線距離最大的點(diǎn)
max_distance_index, max_distance = 0, 0
for index, point in enumerate(point_list):
if index in [0, len(point_list) - 1]:
continue
distance = point2LineDistance(point, point_list[0], point_list[-1])
if distance > max_distance:
max_distance_index = index
max_distance = distance
# 若最大距離小于閾值��,則去掉所有中間點(diǎn)���。 反之��,則將曲線按最大距離點(diǎn)分割
if max_distance < self.threshold:
self.qualify_list.append(point_list[-1])
self.qualify_list.append(point_list[0])
else:
# 將曲線按最大距離的點(diǎn)分割成兩段
sequence_a = point_list[:max_distance_index]
sequence_b = point_list[max_distance_index:]
for sequence in [sequence_a, sequence_b]:
if len(sequence) < 3 and sequence == sequence_b:
self.qualify_list.extend(sequence[::-1])
else:
self.disqualify_list.append(sequence)
def main(self, point_list):
self.diluting(point_list)
while len(self.disqualify_list) > 0:
self.diluting(self.disqualify_list.pop())
print self.qualify_list
print len(self.qualify_list)
if __name__ == '__main__':
d = DouglasPeuker()
d.main([[104.066228, 30.644527], [104.066279, 30.643528], [104.066296, 30.642528], [104.066314, 30.641529],
[104.066332, 30.640529], [104.066383, 30.639530], [104.066400, 30.638530], [104.066451, 30.637531],
[104.066468, 30.636532], [104.066518, 30.635533], [104.066535, 30.634533], [104.066586, 30.633534],
[104.066636, 30.632536], [104.066686, 30.631537], [104.066735, 30.630538], [104.066785, 30.629539],
[104.066802, 30.628539], [104.066820, 30.627540], [104.066871, 30.626541], [104.066888, 30.625541],
[104.066906, 30.624541], [104.066924, 30.623541], [104.066942, 30.622542], [104.066960, 30.621542],
[104.067011, 30.620543], [104.066122, 30.620086], [104.065124, 30.620021], [104.064124, 30.620022],
[104.063124, 30.619990], [104.062125, 30.619958], [104.061125, 30.619926], [104.060126, 30.619894],
[104.059126, 30.619895], [104.058127, 30.619928], [104.057518, 30.620722], [104.057625, 30.621716],
[104.057735, 30.622710], [104.057878, 30.623700], [104.057984, 30.624694], [104.058094, 30.625688],
[104.058204, 30.626682], [104.058315, 30.627676], [104.058425, 30.628670], [104.058502, 30.629667],
[104.058518, 30.630667], [104.058503, 30.631667], [104.058521, 30.632666], [104.057664, 30.633182],
[104.056664, 30.633174], [104.055664, 30.633166], [104.054672, 30.633289], [104.053758, 30.633694],
[104.052852, 30.634118], [104.052623, 30.635091], [104.053145, 30.635945], [104.053675, 30.636793],
[104.054200, 30.637643], [104.054756, 30.638475], [104.055295, 30.639317], [104.055843, 30.640153],
[104.056387, 30.640993], [104.056933, 30.641830], [104.057478, 30.642669], [104.058023, 30.643507],
[104.058595, 30.644327], [104.059152, 30.645158], [104.059663, 30.646018], [104.060171, 30.646879],
[104.061170, 30.646855], [104.062168, 30.646781], [104.063167, 30.646823], [104.064167, 30.646814],
[104.065163, 30.646725], [104.066157, 30.646618], [104.066231, 30.645620], [104.066247, 30.644621], ])
垂距限值法
垂距限值法其實(shí)和DP算法原理一樣,但是垂距限值不是從整體角度考慮�,而是依次掃描每一個(gè)點(diǎn),檢查是否符合要求���。
算法過程如下:
1、以第二個(gè)點(diǎn)開始���,計(jì)算第二個(gè)點(diǎn)到前一個(gè)點(diǎn)和后一個(gè)點(diǎn)所在直線的距離d�����;
2�、如果d大于閾值����,則保留第二個(gè)點(diǎn),計(jì)算第三個(gè)點(diǎn)到第二個(gè)點(diǎn)和第四個(gè)點(diǎn)所在直線的距離d;若d小于閾值則舍棄第二個(gè)點(diǎn)�����,計(jì)算第三個(gè)點(diǎn)到第一個(gè)點(diǎn)和第四個(gè)點(diǎn)所在直線的距離d;
3�、依次類推��,直線曲線上倒數(shù)第二個(gè)點(diǎn)���。
下面是Python代碼實(shí)現(xiàn):
# -*- coding: utf-8 -*-
"""------------------------------------------------- File Name: LimitVerticalDistance Description : 垂距限值抽稀算法 Author : J_hao date: 2017/8/17------------------------------------------------- Change Activity: 2017/8/17:-------------------------------------------------"""
from __future__ import division
from math import sqrt, pow
__author__ = 'J_hao'
THRESHOLD = 0.0001 # 閾值
def point2LineDistance(point_a, point_b, point_c):
""" 計(jì)算點(diǎn)a到點(diǎn)b c所在直線的距離 :param point_a: :param point_b: :param point_c: :return: """
# 首先計(jì)算b c 所在直線的斜率和截距
if point_b[0] == point_c[0]:
return 9999999
slope = (point_b[1] - point_c[1]) / (point_b[0] - point_c[0])
intercept = point_b[1] - slope * point_b[0]
# 計(jì)算點(diǎn)a到b c所在直線的距離
distance = abs(slope * point_a[0] - point_a[1] + intercept) / sqrt(1 + pow(slope, 2))
return distance
class LimitVerticalDistance(object):
def__init__(self):
self.threshold = THRESHOLD
self.qualify_list = list()
def diluting(self, point_list):
""" 抽稀 :param point_list:二維點(diǎn)列表 :return: """
self.qualify_list.append(point_list[0])
check_index = 1
while check_index < len(point_list) - 1:
distance = point2LineDistance(point_list[check_index],
self.qualify_list[-1],
point_list[check_index + 1])
if distance < self.threshold:
check_index += 1
else:
self.qualify_list.append(point_list[check_index])
check_index += 1
return self.qualify_list
if __name__ == '__main__':
l = LimitVerticalDistance()
diluting = l.diluting([[104.066228, 30.644527], [104.066279, 30.643528], [104.066296, 30.642528], [104.066314, 30.641529],
[104.066332, 30.640529], [104.066383, 30.639530], [104.066400, 30.638530], [104.066451, 30.637531],
[104.066468, 30.636532], [104.066518, 30.635533], [104.066535, 30.634533], [104.066586, 30.633534],
[104.066636, 30.632536], [104.066686, 30.631537], [104.066735, 30.630538], [104.066785, 30.629539],
[104.066802, 30.628539], [104.066820, 30.627540], [104.066871, 30.626541], [104.066888, 30.625541],
[104.066906, 30.624541], [104.066924, 30.623541], [104.066942, 30.622542], [104.066960, 30.621542],
[104.067011, 30.620543], [104.066122, 30.620086], [104.065124, 30.620021], [104.064124, 30.620022],
[104.063124, 30.619990], [104.062125, 30.619958], [104.061125, 30.619926], [104.060126, 30.619894],
[104.059126, 30.619895], [104.058127, 30.619928], [104.057518, 30.620722], [104.057625, 30.621716],
[104.057735, 30.622710], [104.057878, 30.623700], [104.057984, 30.624694], [104.058094, 30.625688],
[104.058204, 30.626682], [104.058315, 30.627676], [104.058425, 30.628670], [104.058502, 30.629667],
[104.058518, 30.630667], [104.058503, 30.631667], [104.058521, 30.632666], [104.057664, 30.633182],
[104.056664, 30.633174], [104.055664, 30.633166], [104.054672, 30.633289], [104.053758, 30.633694],
[104.052852, 30.634118], [104.052623, 30.635091], [104.053145, 30.635945], [104.053675, 30.636793],
[104.054200, 30.637643], [104.054756, 30.638475], [104.055295, 30.639317], [104.055843, 30.640153],
[104.056387, 30.640993], [104.056933, 30.641830], [104.057478, 30.642669], [104.058023, 30.643507],
[104.058595, 30.644327], [104.059152, 30.645158], [104.059663, 30.646018], [104.060171, 30.646879],
[104.061170, 30.646855], [104.062168, 30.646781], [104.063167, 30.646823], [104.064167, 30.646814],
[104.065163, 30.646725], [104.066157, 30.646618], [104.066231, 30.645620], [104.066247, 30.644621], ])
print len(diluting)
print(diluting)
最后
其實(shí)DP算法和垂距限值法原理一樣,DP算法是從整體上考慮一條完整的曲線����,實(shí)現(xiàn)時(shí)較垂距限值法復(fù)雜,但垂距限值法可能會(huì)在某些情況下導(dǎo)致局部最優(yōu)���。另外在實(shí)際使用中發(fā)現(xiàn)采用點(diǎn)到另外兩點(diǎn)所在直線距離的方法來判斷偏離�,在曲線弧度比較大的情況下比較準(zhǔn)確��。如果在曲線弧度比較小���,彎??程度不明顯時(shí)�����,這種方法抽稀效果不是很理想�����,建議使用三點(diǎn)所圍成的三角形面積作為判斷標(biāo)準(zhǔn)�。下面是抽稀效果:
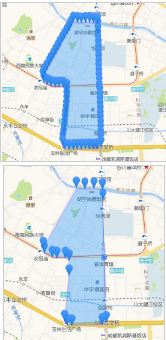
以上就是本文的全部?jī)?nèi)容,希望對(duì)大家的學(xué)習(xí)有所幫助
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試���,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情�;
? 想學(xué)習(xí)CDA考試教材���,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情����;
? 想了解CDA考試含金量,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情�����;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營許可證編號(hào):京B2-20210330