基于標記數(shù)據(jù)學習降低誤報率的算法優(yōu)化
無論是基于規(guī)則匹配的策略�,還是基于復雜的安全分析模型���,安全設備產生的告警都存在大量誤報�,這是一個相當普遍的問題。其中一個重要的原因是每個客戶的應用場景和數(shù)據(jù)都多多少少有不同的差異�����,基于固定判斷規(guī)則對有統(tǒng)計漲落的數(shù)據(jù)進行僵化的判斷��,很容易出現(xiàn)誤判����。
在沒有持續(xù)人工干預和手動優(yōu)化的情況下,策略和模型的誤報率不會隨著數(shù)據(jù)的積累而有所改進�����。也就是說安全分析人員通過對告警打標簽的方式�,可以將專業(yè)經驗傳授給智能算法,自動得反饋到策略和模型當中��,使之對安全事件做出更精準的判斷����。本文介紹利用專家經驗持續(xù)優(yōu)化機器學習的方法,對告警數(shù)據(jù)進行二次分析和學習,從而顯著地降低安全威脅告警的誤報率�。
為了降低誤報率,當前大體上有兩種技術途徑:
根據(jù)不同客戶的各種特定情況修正策略和模型��,提高策略或者模型的適應能力;
定期(如每月一次)對告警進入二次人工分析���,根據(jù)分析結果來調整策略和模型的參數(shù)配置�����。
這兩種方法對降低誤報率都有一定的作用�。但是第一種沒有自適應能力���,是否有效果要看實際情況��。第二種效果會好一些���,但是非常耗時耗力,而且由于是人工現(xiàn)場干預和調整策略和模型����,出錯的概率也非常高。
MIT的研究人員[1]
介紹了一種將安全分析人員標記后的告警日志作為訓練數(shù)據(jù)集�,令機器學習算法學習專家經驗�����,使分析算法持續(xù)得到優(yōu)化,實現(xiàn)自動識別誤報告警�,降低誤報率的方法(以下簡稱“標簽傳遞經驗方法”)。這種把安全分析人員的專業(yè)智能轉化成算法分析能力的過程���,會讓分析算法隨著數(shù)據(jù)的積累而更加精確����。繼而逐漸擺脫人工干預����,提高運維效率。如下圖所示:
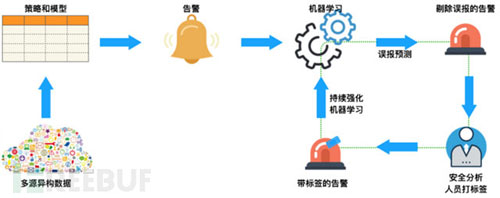
下面我們通過基于“頻繁訪問安全威脅告警”模擬的場景數(shù)據(jù)來介紹一下實現(xiàn)機制���。
什么是頻繁訪問模型?邏輯比較簡單:一段時間內(比如1分鐘)�,一個攻擊者對系統(tǒng)的訪問次數(shù)顯著高于普通訪問者的次數(shù)���。此告警規(guī)則可以用簡單的基于閾值�,或者是利用統(tǒng)計分布的離異概率���?�;诖?�,我們先模擬一些已經被安全分析人員打過標簽的告警數(shù)據(jù)��。根據(jù)實際應用經驗�,我們盡量模擬非常接近實際場景的數(shù)據(jù)。如下圖:
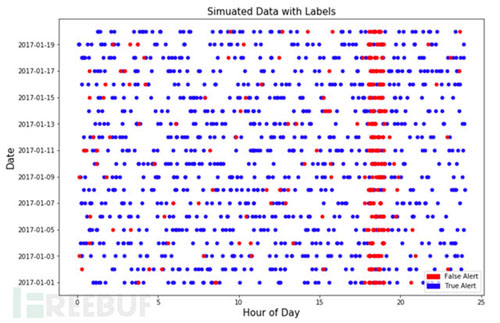
關于模擬數(shù)據(jù)的介紹:
總共模擬了20天的告警數(shù)據(jù)��,從2017-01-01到2017-01-20�。前10天的數(shù)據(jù)用來訓練模型,后10天的數(shù)據(jù)用來衡量模型的表現(xiàn);
每個告警帶有是否誤報的標簽�。紅色代表誤報,藍色代表準確告警�����。
關于模擬數(shù)據(jù)的假設:
誤報聚集在某個時間段�����,模擬數(shù)據(jù)假設的范圍是18:00-19:00��。在安全運維實踐中�,的確存在某個特定的時間段��,由于業(yè)務邏輯或者系統(tǒng)原因導致誤報增多的現(xiàn)象���。所以上述假設是合理的,告警時間可以作為有效的特征值���。但并不是所有的誤報都聚集在這個時間段,同時并不是這個時間段的所有告警都是誤報;
誤報大多來自于一批不同的IP�����。所以訪問來源IP也是有用的特征值;
任何數(shù)據(jù)都不是完美的�,所以在模擬數(shù)據(jù)中加入了~9%的噪音。也就是說再完美的智能模型���,誤報率也不會低于9%���。
這些假設在實際的應用場景中也是相對合理的。如果誤報是完全隨機產生的���,那么再智能的模型也不能夠捕捉到誤報的提出信號����。所以這些合理的假設幫助我們模擬真實的數(shù)據(jù),并且驗證我們的機器學習模型��。
簡要模擬數(shù)據(jù)的代碼實現(xiàn):
下圖顯示利用PCA降維分析的可視化結果���,可以看到明顯的分類情況:
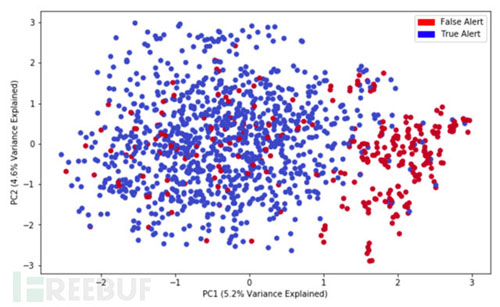
紅色代表誤報���,藍色代表正確告警?;谠O定特征值的降維分析可以得到兩個聚集,即誤報和非誤報有明顯的區(qū)分的�,也就是說誤報的是有一定規(guī)律,不是完全隨機的����,因此是可以被機器學習捕捉到的。
簡要代碼實現(xiàn):

基于模擬數(shù)據(jù)�,我們想要達到的目的是通過持續(xù)的強化機器學習能夠降低誤報率。所以我們采取的策略是:
訓練一天的數(shù)據(jù)2017-01-01��,測試10天的數(shù)據(jù)2017-01-11到2017-01-20;
訓練兩天的數(shù)據(jù)2017-01-01到2017-01-02�,測試10天的數(shù)據(jù)2017-01-11到2017-01-20;
以此類推,來看通過學習越來越多的數(shù)據(jù)�,在測試數(shù)據(jù)中的誤報率是否能夠得到不斷的改進。
簡要代碼如下:
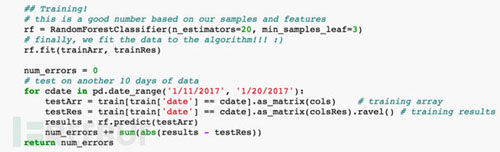
此安全威脅場景相對簡單����,我們不需要太多的特征值和海量的數(shù)據(jù)����,所以機器學習模型選擇了隨機森林(RandomForest)���,我們也嘗試了其他復雜模型����,得出的效果區(qū)別不大����。測試結果如下:
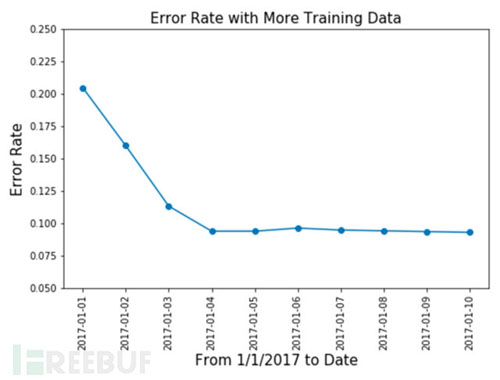
達到我們所預期的效果�����,當訓練數(shù)據(jù)越來越多的時候�,測試數(shù)據(jù)當中的誤報率從20%多降低到了10%。通過對告警數(shù)據(jù)和標簽的不斷自學習��,可以剔除很多告警誤報��。前面提到��,數(shù)據(jù)當中引入了9%的噪音,所以誤報率不會再持續(xù)的降低�����。
在我們的機器學習模型當中�,我們利用了4個主要的特征值:
srcIP,訪問源IP
timeofday�,告警產生的時間
visits,訪問次數(shù)
destIP��,被訪問IP
下圖顯示了特征值在模型中的重要性:

和我們的預期也是一致的�,訪問源IP(srcIP)和告警發(fā)生的時間(timeofday)是區(qū)分出誤報告警效果最好的特征值。
另外����,由于隨機森林模型以及大部分機器學習模型都不支持分類變量(categoricalvariable)的學習,所以我們把srcIP和destIP這兩個特征值做了二值化處理�����。簡要代碼如下:

總結
本文通過一組模擬實驗數(shù)據(jù)和隨機森林算法��,從理論上驗證了“標簽傳遞經驗方法”的有效性���。即通過安全分析專家對告警日志進行有效或誤報的標記�,把專家的知識技能轉化成機器學習模型的分析能力。和其他方法相比�����,此方法在完成自動化學習之后就不再需要人工干預�����,而且會隨著數(shù)據(jù)的積累對誤報的剔除會更加精確�����。
CDA數(shù)據(jù)分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�,點擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學習CDA考試教材�,點擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫�����,點擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量,點擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網(wǎng)安備 11010802034615號
經營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經營許可證編號:京B2-20210330