樸素貝葉斯分類算法理解及文本分類器實(shí)現(xiàn)
貝葉斯分類是一類分類算法的總稱,這類算法均以貝葉斯定理為基礎(chǔ)�����,故統(tǒng)稱為貝葉斯分類���。本文作為分類算法的第一篇����,將首先介紹分類問(wèn)題����,對(duì)分類問(wèn)題進(jìn)行一個(gè)正式的定義。然后�����,介紹貝葉斯分類算法的基礎(chǔ)——貝葉斯定理�。最后,通過(guò)實(shí)例討論貝葉斯分類中最簡(jiǎn)單的一種:樸素貝葉斯分類�����。
分類問(wèn)題綜述
對(duì)于分類問(wèn)題,其實(shí)誰(shuí)都不會(huì)陌生����,說(shuō)我們每個(gè)人每天都在執(zhí)行分類操作一點(diǎn)都不夸張,只是我們沒(méi)有意識(shí)到罷了�。例如,當(dāng)你看到一個(gè)陌生人�,你的腦子下意識(shí)判斷TA是男是女;你可能經(jīng)常會(huì)走在路上對(duì)身旁的朋友說(shuō)“這個(gè)人一看就很有錢(qián)�����、那邊有個(gè)非主流”之類的話�,其實(shí)這就是一種分類操作。
從數(shù)學(xué)角度來(lái)說(shuō)�,分類問(wèn)題可做如下定義:

其中C叫做類別集合,其中每一個(gè)元素是一個(gè)類別���,而I叫做項(xiàng)集合�����,其中每一個(gè)元素是一個(gè)待分類項(xiàng)�����,f叫做分類器���。分類算法的任務(wù)就是構(gòu)造分類器f。
這里要著重強(qiáng)調(diào)����,分類問(wèn)題往往采用經(jīng)驗(yàn)性方法構(gòu)造映射規(guī)則,即一般情況下的分類問(wèn)題缺少足夠的信息來(lái)構(gòu)造100%正確的映射規(guī)則��,而是通過(guò)對(duì)經(jīng)驗(yàn)數(shù)據(jù)的學(xué)習(xí)從而實(shí)現(xiàn)一定概率意義上正確的分類��,因此所訓(xùn)練出的分類器并不是一定能將每個(gè)待分類項(xiàng)準(zhǔn)確映射到其分類���,分類器的質(zhì)量與分類器構(gòu)造方法�、待分類數(shù)據(jù)的特性以及訓(xùn)練樣本數(shù)量等諸多因素有關(guān)����。
例如,醫(yī)生對(duì)病人進(jìn)行診斷就是一個(gè)典型的分類過(guò)程��,任何一個(gè)醫(yī)生都無(wú)法直接看到病人的病情�����,只能觀察病人表現(xiàn)出的癥狀和各種化驗(yàn)檢測(cè)數(shù)據(jù)來(lái)推斷病情,這時(shí)醫(yī)生就好比一個(gè)分類器�,而這個(gè)醫(yī)生診斷的準(zhǔn)確率,與他當(dāng)初受到的教育方式(構(gòu)造方法)��、病人的癥狀是否突出(待分類數(shù)據(jù)的特性)以及醫(yī)生的經(jīng)驗(yàn)多少(訓(xùn)練樣本數(shù)量)都有密切關(guān)系�。
貝葉斯分類的基礎(chǔ)——貝葉斯定理
每次提到貝葉斯定理,我心中的崇敬之情都油然而生�����,倒不是因?yàn)檫@個(gè)定理多高深����,而是因?yàn)樗貏e有用。這個(gè)定理解決了現(xiàn)實(shí)生活里經(jīng)常遇到的問(wèn)題:已知某條件概率�,如何得到兩個(gè)事件交換后的概率,也就是在已知P(A|B)的情況下如何求得P(B|A)����。這里先解釋什么是條件概率:

樸素貝葉斯分類
樸素貝葉斯分類的原理與流程
樸素貝葉斯分類是一種十分簡(jiǎn)單的分類算法,叫它樸素貝葉斯分類是因?yàn)檫@種方法的思想真的很樸素����,樸素貝葉斯的思想基礎(chǔ)是這樣的:對(duì)于給出的待分類項(xiàng),求解在此項(xiàng)出現(xiàn)的條件下各個(gè)類別出現(xiàn)的概率�,哪個(gè)最大�,就認(rèn)為此待分類項(xiàng)屬于哪個(gè)類別�。通俗來(lái)說(shuō),就好比這么個(gè)道理�����,你在街上看到一個(gè)黑人����,我問(wèn)你你猜這哥們哪里來(lái)的��,你十有八九猜非洲���。為什么呢���?因?yàn)楹谌酥蟹侵奕说谋嚷首罡撸?dāng)然人家也可能是美洲人或亞洲人�����,但在沒(méi)有其它可用信息下����,我們會(huì)選擇條件概率最大的類別���,這就是樸素貝葉斯的思想基礎(chǔ)。
樸素貝葉斯分類的正式定義如下:

根據(jù)上述分析�,樸素貝葉斯分類的流程可以由下圖表示(暫時(shí)不考慮驗(yàn)證):
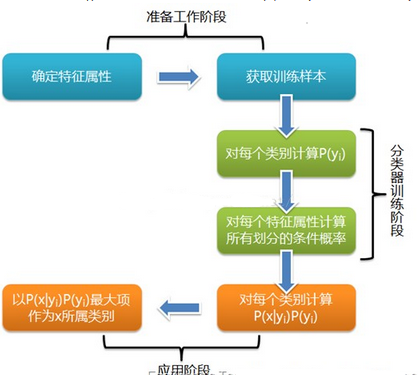
可以看到,整個(gè)樸素貝葉斯分類分為三個(gè)階段:
第一階段——準(zhǔn)備工作階段��,這個(gè)階段的任務(wù)是為樸素貝葉斯分類做必要的準(zhǔn)備�,主要工作是根據(jù)具體情況確定特征屬性,并對(duì)每個(gè)特征屬性進(jìn)行適當(dāng)劃分��,然后由人工對(duì)一部分待分類項(xiàng)進(jìn)行分類��,形成訓(xùn)練樣本集合�。這一階段的輸入是所有待分類數(shù)據(jù),輸出是特征屬性和訓(xùn)練樣本�����。這一階段是整個(gè)樸素貝葉斯分類中唯一需要人工完成的階段�,其質(zhì)量對(duì)整個(gè)過(guò)程將有重要影響,分類器的質(zhì)量很大程度上由特征屬性�、特征屬性劃分及訓(xùn)練樣本質(zhì)量決定。
第二階段——分類器訓(xùn)練階段�,這個(gè)階段的任務(wù)就是生成分類器,主要工作是計(jì)算每個(gè)類別在訓(xùn)練樣本中的出現(xiàn)頻率及每個(gè)特征屬性劃分對(duì)每個(gè)類別的條件概率估計(jì)����,并將結(jié)果記錄�����。其輸入是特征屬性和訓(xùn)練樣本����,輸出是分類器��。這一階段是機(jī)械性階段����,根據(jù)前面討論的公式可以由程序自動(dòng)計(jì)算完成�。
第三階段——應(yīng)用階段。這個(gè)階段的任務(wù)是使用分類器對(duì)待分類項(xiàng)進(jìn)行分類��,其輸入是分類器和待分類項(xiàng)�,輸出是待分類項(xiàng)與類別的映射關(guān)系。這一階段也是機(jī)械性階段����,由程序完成。
1.4.2�����、估計(jì)類別下特征屬性劃分的條件概率及Laplace校準(zhǔn)
這一節(jié)討論P(yáng)(a|y)的估計(jì)。
由上文看出��,計(jì)算各個(gè)劃分的條件概率P(a|y)是樸素貝葉斯分類的關(guān)鍵性步驟�,當(dāng)特征屬性為離散值時(shí),只要很方便的統(tǒng)計(jì)訓(xùn)練樣本中各個(gè)劃分在每個(gè)類別中出現(xiàn)的頻率即可用來(lái)估計(jì)P(a|y)�����,下面重點(diǎn)討論特征屬性是連續(xù)值的情況���。
當(dāng)特征屬性為連續(xù)值時(shí)����,通常假定其值服從高斯分布(也稱正態(tài)分布)�����。即:
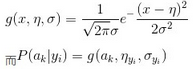
因此只要計(jì)算出訓(xùn)練樣本中各個(gè)類別中此特征項(xiàng)劃分的各均值和標(biāo)準(zhǔn)差�����,代入上述公式即可得到需要的估計(jì)值�。均值與標(biāo)準(zhǔn)差的計(jì)算在此不再贅述�。
另一個(gè)需要討論的問(wèn)題就是當(dāng)P(a|y)=0怎么辦�����,當(dāng)某個(gè)類別下某個(gè)特征項(xiàng)劃分沒(méi)有出現(xiàn)時(shí)�����,就是產(chǎn)生這種現(xiàn)象���,這會(huì)令分類器質(zhì)量大大降低����。為了解決這個(gè)問(wèn)題����,我們引入Laplace校準(zhǔn)����,它的思想非常簡(jiǎn)單,就是對(duì)沒(méi)類別下所有劃分的計(jì)數(shù)加1�����,這樣如果訓(xùn)練樣本集數(shù)量充分大時(shí),并不會(huì)對(duì)結(jié)果產(chǎn)生影響����,并且解決了上述頻率為0的尷尬局面。
樸素貝葉斯分類實(shí)例:檢測(cè)SNS社區(qū)中不真實(shí)賬號(hào)
下面討論一個(gè)使用樸素貝葉斯分類解決實(shí)際問(wèn)題的例子��,為了簡(jiǎn)單起見(jiàn)��,對(duì)例子中的數(shù)據(jù)做了適當(dāng)?shù)暮?jiǎn)化�。
這個(gè)問(wèn)題是這樣的,對(duì)于SNS社區(qū)來(lái)說(shuō)�,不真實(shí)賬號(hào)(使用虛假身份或用戶的小號(hào))是一個(gè)普遍存在的問(wèn)題,作為SNS社區(qū)的運(yùn)營(yíng)商����,希望可以檢測(cè)出這些不真實(shí)賬號(hào),從而在一些運(yùn)營(yíng)分析報(bào)告中避免這些賬號(hào)的干擾�,亦可以加強(qiáng)對(duì)SNS社區(qū)的了解與監(jiān)管。
如果通過(guò)純?nèi)斯z測(cè)����,需要耗費(fèi)大量的人力,效率也十分低下����,如能引入自動(dòng)檢測(cè)機(jī)制��,必將大大提升工作效率�。這個(gè)問(wèn)題說(shuō)白了����,就是要將社區(qū)中所有賬號(hào)在真實(shí)賬號(hào)和不真實(shí)賬號(hào)兩個(gè)類別上進(jìn)行分類,下面我們一步一步實(shí)現(xiàn)這個(gè)過(guò)程����。
首先設(shè)C=0表示真實(shí)賬號(hào),C=1表示不真實(shí)賬號(hào)��。
1、確定特征屬性及劃分
這一步要找出可以幫助我們區(qū)分真實(shí)賬號(hào)與不真實(shí)賬號(hào)的特征屬性���,在實(shí)際應(yīng)用中�,特征屬性的數(shù)量是很多的,劃分也會(huì)比較細(xì)致���,但這里為了簡(jiǎn)單起見(jiàn)��,我們用少量的特征屬性以及較粗的劃分�����,并對(duì)數(shù)據(jù)做了修改����。
我們選擇三個(gè)特征屬性:a1:日志數(shù)量/注冊(cè)天數(shù),a2:好友數(shù)量/注冊(cè)天數(shù)��,a3:是否使用真實(shí)頭像���。在SNS社區(qū)中這三項(xiàng)都是可以直接從數(shù)據(jù)庫(kù)里得到或計(jì)算出來(lái)的�。
下面給出劃分:a1:{a<=0.05, 0.05<a<0.2, a>=0.2}���,a1:{a<=0.1, 0.1<a<0.8, a>=0.8},a3:{a=0(不是),a=1(是)}���。
2���、獲取訓(xùn)練樣本
這里使用運(yùn)維人員曾經(jīng)人工檢測(cè)過(guò)的1萬(wàn)個(gè)賬號(hào)作為訓(xùn)練樣本。
3��、計(jì)算訓(xùn)練樣本中每個(gè)類別的頻率
用訓(xùn)練樣本中真實(shí)賬號(hào)和不真實(shí)賬號(hào)數(shù)量分別除以一萬(wàn)���,得到:
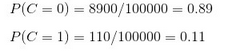
4����、計(jì)算每個(gè)類別條件下各個(gè)特征屬性劃分的頻率
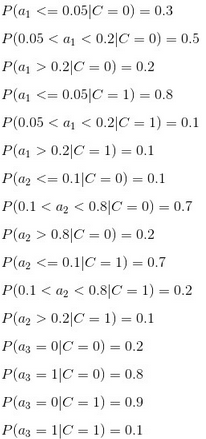
5�����、使用分類器進(jìn)行鑒別
下面我們使用上面訓(xùn)練得到的分類器鑒別一個(gè)賬號(hào)��,這個(gè)賬號(hào)使用非真實(shí)頭像���,日志數(shù)量與注冊(cè)天數(shù)的比率為0.1����,好友數(shù)與注冊(cè)天數(shù)的比率為0.2����。
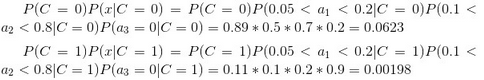
可以看到,雖然這個(gè)用戶沒(méi)有使用真實(shí)頭像����,但是通過(guò)分類器的鑒別,更傾向于將此賬號(hào)歸入真實(shí)賬號(hào)類別�。這個(gè)例子也展示了當(dāng)特征屬性充分多時(shí),樸素貝葉斯分類對(duì)個(gè)別屬性的抗干擾性��。
1.5���、分類器的評(píng)價(jià)
雖然后續(xù)還會(huì)提到其它分類算法�,不過(guò)這里我想先提一下如何評(píng)價(jià)分類器的質(zhì)量��。
首先要定義�,分類器的正確率指分類器正確分類的項(xiàng)目占所有被分類項(xiàng)目的比率。
通常使用回歸測(cè)試來(lái)評(píng)估分類器的準(zhǔn)確率����,最簡(jiǎn)單的方法是用構(gòu)造完成的分類器對(duì)訓(xùn)練數(shù)據(jù)進(jìn)行分類,然后根據(jù)結(jié)果給出正確率評(píng)估。但這不是一個(gè)好方法����,因?yàn)槭褂糜?xùn)練數(shù)據(jù)作為檢測(cè)數(shù)據(jù)有可能因?yàn)檫^(guò)分?jǐn)M合而導(dǎo)致結(jié)果過(guò)于樂(lè)觀,所以一種更好的方法是在構(gòu)造初期將訓(xùn)練數(shù)據(jù)一分為二�����,用一部分構(gòu)造分類器����,然后用另一部分檢測(cè)分類器的準(zhǔn)確率�����。
Python代碼實(shí)現(xiàn):
[python] view plain copy
#encoding:utf-8
from numpy import *
#詞表到向量的轉(zhuǎn)換函數(shù)
def loadDataSet():
postingList = [['my','dog','has','flea','problems','help','please'],
['maybe','not','take','him','to','dog','park','stupid'],
['my','dalmation','is','so','cute','I','love','him'],
['stop','posting','stupid','worthless','garbage'],
['mr','licks','ate','my','steak','how','to','stop','him'],
['quit','buying','worthless','dog','food','stupid']]
classVec = [0,1,0,1,0,1] #1,侮辱 0,正常
return postingList,classVec
def createVocabList(dataSet):
vocabSet = set([]) #調(diào)用set方法,創(chuàng)建一個(gè)空集
for document in dataSet:
vocabSet = vocabSet | set(document) #創(chuàng)建兩個(gè)集合的并集
return list(vocabSet)
'''''
def setOfWords2Vec(vocabList,inputSet):
returnVec = [0]*len(vocabList) #創(chuàng)建一個(gè)所含元素都為0的向量
for word in inputSet:
if word in vocabList:
returnVec[vocabList.index(word)] = 1
else:
print "the word:%s is not in my Vocabulary" % word
return returnVec
'''
def bagOfWords2VecMN(vocabList,inputSet):
returnVec = [0]*len(vocabList) #創(chuàng)建一個(gè)所含元素都為0的向量
for word in inputSet:
if word in vocabList:
returnVec[vocabList.index(word)] += 1
return returnVec
#樸素貝葉斯分類器訓(xùn)練集
def trainNB0(trainMatrix,trainCategory): #傳入?yún)?shù)為文檔矩陣��,每篇文檔類別標(biāo)簽所構(gòu)成的向量
numTrainDocs = len(trainMatrix) #文檔矩陣的長(zhǎng)度
numWords = len(trainMatrix[0]) #第一個(gè)文檔的單詞個(gè)數(shù)
pAbusive = sum(trainCategory)/float(numTrainDocs) #任意文檔屬于侮辱性文檔概率
#p0Num = zeros(numWords);p1Num = zeros(numWords) #初始化兩個(gè)矩陣,長(zhǎng)度為numWords�����,內(nèi)容值為0
p0Num = ones(numWords);p1Num = ones(numWords) #初始化兩個(gè)矩陣�,長(zhǎng)度為numWords,內(nèi)容值為1
#p0Denom = 0.0;p1Denom = 0.0 #初始化概率
p0Denom = 2.0;p1Denom = 2.0
for i in range(numTrainDocs):
if trainCategory[i]==1:
p1Num +=trainMatrix[i]
p1Denom += sum(trainMatrix[i])
else:
p0Num +=trainMatrix[i]
p0Denom += sum(trainMatrix[i])
#p1Vect = p1Num/p1Denom #對(duì)每個(gè)元素做除法
#p0Vect = p0Num/p0Denom
p1Vect = log(p1Num/p1Denom)
p0Vect = log(p0Num/p0Denom)
return p0Vect,p1Vect,pAbusive
#樸素貝葉斯分類函數(shù)
def classifyNB(vec2Classify,p0Vec,p1Vec,pClass1):
p1 = sum(vec2Classify * p1Vec) + log(pClass1) #元素相乘
p0 = sum(vec2Classify * p0Vec) + log(1.0 - pClass1)
if p1>p0:
return 1
else:
return 0
def testingNB():
listOPosts,listClasses = loadDataSet() #產(chǎn)生文檔矩陣和對(duì)應(yīng)的標(biāo)簽
myVocabList = createVocabList(listOPosts) #創(chuàng)建并集
trainMat = [] #創(chuàng)建一個(gè)空的列表
for postinDoc in listOPosts:
trainMat.append(setOfWords2Vec(myVocabList,postinDoc)) #使用詞向量來(lái)填充trainMat列表
p0V,p1V,pAb = trainNB0(array(trainMat),array(listClasses)) #訓(xùn)練函數(shù)
testEntry = ['love','my','dalmation'] #測(cè)試文檔列表
thisDoc = array(setOfWords2Vec(myVocabList,testEntry)) #聲明矩陣
print testEntry,'classified as:',classifyNB(thisDoc,p0V,p1V,pAb)
testEntry = ['stupid','garbage']
thisDoc = array(setOfWords2Vec(myVocabList,testEntry)) #聲明矩陣
print testEntry,'classified as:',classifyNB(thisDoc,p0V,p1V,pAb)
使用方法:
進(jìn)入該文件所在目錄�,輸入Python,執(zhí)行
>>>import bayes
>>>bayes.testingNB()
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試���,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情���;
? 想學(xué)習(xí)CDA考試教材�,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫(kù)�����,點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情;
? 想了解CDA考試含金量,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330