如何實現(xiàn)降維處理(R語言)
現(xiàn)實世界中數據一般都是復雜和高維的��,比如描述一個人���,有姓名�����、年齡����、性別、受教育程度��、收入���、地址��、電話等等幾十種屬性�����,如此多的屬性對于數據分析是一個嚴重的挑戰(zhàn)�,除了極大增加建模的成本和模型的復雜度,往往也會導致過擬合問題�,因此在實際處理過程中,一些降維的方法是必不可少���,其中用的比較多的有主成分分析(PCA)�、奇異值分解(SVD)�、特征選擇(Feature
Select),本文將對PCA和SVD作簡單的介紹���,并力圖通過案例加深對這兩種降維方法的理解�����。
1 主成分分析PCA
1.1 R語言案例
在R語言中PCA對應函數是princomp���,來自stats包����。以美國的各州犯罪數據為對象進行分析����,數據集USArrests在graphics包中。
> library(stats) ##princomp
> head(USArrests)
Murder Assault UrbanPop Rape
Alabama 13.2 236 58 21.2
Alaska 10.0 263 48 44.5
Arizona 8.1 294 80 31.0
> summary(pc.cr <- princomp(USArrests, cor = TRUE))
##每個主成分對方差的貢獻比例��,顯然Comp.1 + Comp2所占比例超過85%��,因此能夠用前兩個主成分來表示整個數據集���,也將數據從4維降到兩維
Importance of components:
Comp.1 Comp.2 Comp.3 Comp.4
Standard deviation 1.5748783 0.9948694 0.5971291 0.41644938
Proportion of Variance 0.6200604 0.2474413 0.0891408 0.04335752
Cumulative Proportion 0.6200604 0.8675017 0.9566425 1.00000000
接下來查看每個特征在主成分中所在的比例
> loadings(pc.cr)
Loadings:
Comp.1 Comp.2 Comp.3 Comp.4
Murder -0.536 0.418 -0.341 0.649
Assault -0.583 0.188 -0.268 -0.743
UrbanPop -0.278 -0.873 -0.378 0.134
Rape -0.543 -0.167 0.818
Comp.1 Comp.2 Comp.3 Comp.4
SS loadings 1.00 1.00 1.00 1.00
Proportion Var 0.25 0.25 0.25 0.25
Cumulative Var 0.25 0.50 0.75 1.00
根據以上數據可很容易轉換為幾個數學等式:
Comp1 = -0.536 * Murder + (-0.583) * Assault + (-0.278)*UrbanPop + (-0.543)* Rape
Comp2 = 0.418 * Murder + 0.188 * Assault + (-0.873)*UrbanPop + (-0.167)* Rape
可以用Comp1、Comp2兩個維度的數據來表示各州��,在二維圖上展現(xiàn)各州個聚類關系�。
> head(pc.cr$scores) ##scores包含有各州在四個主成分的得分
Comp.1 Comp.2 Comp.3 Comp.4
Alabama -0.98556588 1.13339238 -0.44426879 0.156267145
Alaska -1.95013775 1.07321326 2.04000333 -0.438583440
Arizona -1.76316354 -0.74595678 0.05478082 -0.834652924
Arkansas 0.14142029 1.11979678 0.11457369 -0.182810896
California -2.52398013 -1.54293399 0.59855680 -0.341996478
##將前兩個Comp提取出來,轉換為data.frame方便會面繪圖
> stats.arrests <- data.frame(pc.cr$scores[, -c(3:4)])
> head(stats.arrests)
Comp.1 Comp.2
Alabama -0.9855659 1.1333924
Alaska -1.9501378 1.0732133
Arizona -1.7631635 -0.7459568
> library(ggplot2)
##展現(xiàn)各州的分布情況���,觀察哪些州比較異常����,哪些能夠進行聚類
> ggplot(stats.arrests, aes(x = Comp.1, y = Comp.2)) +
+ xlab("First Component") + ylab("Second Component") +
+ geom_text(alpha = 0.75, label = rownames(stats.arrests), size = 4)
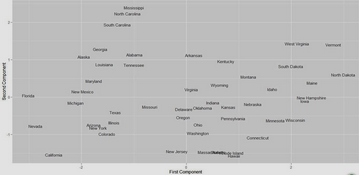
有興趣的同學還可以,分析南北各州在犯罪數據上的迥異�。
1.2 PCA理論基礎
經過上一小節(jié)對PCA的簡單應用,應該可以體會到PCA在降維處理上的魅力�,下面簡單介紹PCA的理論基礎,對于更好的理解和應用PCA會非常有幫助�����。
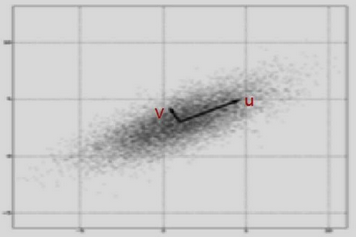
PCA本質就是將數據投影在眾多正交向量上����,根據投影后數據的方差大小,說明向量解釋數據的程度�����,方差越大����,解釋的程度越大。以下圖為例����,數據投影在向量u的方差明顯最大,因此u向量作為第一主成分��,與u向量正交的v向量,作為第二主成分����。
Nd
= dim(data) 代表數據的維數, Sc = num(Comp)代表主成分的個數(Nd = Sc ),在實際情況中�����,往往取前k
<<
Nd個主成分便能解釋數據的方差程度超過90%�,因此能夠在只丟失少量消息的情況,達到大規(guī)模減少數據維度的效果�,無論對于建立模型、提升性能�����、減少成本都有很大的意義�。
從某種意義上講��,PCA只是將很多相互間存在線性關系的特征�,轉換成新的、相互獨立的特征����,從而減少特征數量�。對此���,它需要借助特征值來找到方差最大的主成分�����,每一個特征值對應一個特征向量����,特征值越大���,特征向量解釋數據矩陣的方差的程度越高���。因此,只需要將特征值從大到小排列����,取出前k個特征向量,便能確定k個最重要的主成分�。
PCA算法通常包括如下5個步驟:
A 平均值歸一化,減去每個特征的平均值���,保證歸一化后的數據平均值為0
B 計算協(xié)方差矩陣��,每兩個特征之間的協(xié)方差
C 計算協(xié)方差矩陣的特征向量和特征值
D 將特征向量根據對應的特征值大小降序排列�����,特征向量按列組成FeatureVector = (eig_1, eig_2, …,eig_n)
E RowFeatureVector = t(FeatureVector) (轉置)����,eig_1變?yōu)榈谝恍校琑owDataAdjusted = t(DataAdjusted), 特征行變?yōu)榱?���,得到最終的數據。
FinalData = RowFeatureVector X RowDataAdjusted
從維度變化的角度出發(fā)
協(xié)方差矩陣:n x n , FeatureVector: n x n����,RowFeatureVector:n x n, n為特征數量
DataAdjusted:m x n, RowDataAdjusted: n x m
取前k個特征向量, RowFeatureVector:k x n
那么FinalData: k x m, 這樣便實現(xiàn)維度的降低���。
2 奇異值分解(SVD)
2.1 案例研究
我們通過一張圖片的處理來展示奇異值分解的魅力所在,對于圖片的處理會用到R語言中raster和jpeg兩個包���。
##載入圖片�,并且顯示出來
> library(raster)
Loading required package: sp
> library(jpeg)
> raster.photo <- raster("Rlogo.jpg")
> photo.flip <- flip(raster.photo, direction = "y")
##將數據轉換為矩陣形式
> photo.raster <- t(as.matrix(photo.flip))
> dim(photo.raster)
[1] 288 196
> image(photo.raster, col = grey(seq(0, 1, length = 256))) ##灰化處理

##奇異值進行分解
> photo.svd <- svd(photo.raster)
> d <- diag(photo.svd$d)
> v <- as.matrix(photo.svd$v)
> u <- photo.svd$u
取第一個奇異值進行估計���,如下左圖
> u1 <- as.matrix(u[, 1])
> d1 <- as.matrix(d[1, 1])
> v <- as.matrix(v[, 1])
> photo1 <- u1 %*% d1 %*% t(v)
> image(photo1, col = grey(seq(0, 1, length = 256)))

取前五十個奇異值進行模擬�����,基本能還原成最初的模樣���,如上右圖
> u2 <- as.matrix(u[, 1:50])
> d2 <- as.matrix(d[1:50, 1:50])
> v2 <- as.matrix(v[, 1:50])
> photo2 <- u2 %*% d2 %*% t(v2)
> image(photo2, col = grey(seq(0, 1, length = 256)))
當我們嘗試用更多的奇異值模擬時���,會發(fā)現(xiàn)效果越來來越好,這就是SVD的魅力����,對于降低數據規(guī)模、提高運算效率��、節(jié)省存儲空間有著非常棒的效果��。原本一張圖片需要288
X 196的存儲空間���,經過SVD處理后����,在保證圖片質量的前提下�,只需288 X 50 + 50 X 50 + 196 X
50的存儲空間僅為原來的一半�。
2.1 SVD理論基礎
SVD算法通過發(fā)現(xiàn)重要維度的特征����,幫助更好的理解數據,從而在數據處理過程中減少不必要的屬性和特征�����,PCA(主成分分析)只是SVD的一個特例��。PCA針對的正方矩陣(協(xié)方差矩陣)�,而SVD可用于任何矩陣的分解。
對于任意m x n矩陣A��,都有這樣一個等式
Am x n = Um x r Sr x r VTn x r
U的列稱為左奇異向量�,V的列稱為右奇異向量,S是一個對角線矩陣����,對角線上的值稱為奇異值,
r = min(n,
m)。U的列對應AAT的特征向量���,V的列則是ATA的特征向量,奇異值是AAT和ATA共有特征值的開方����。由于A可能不是正方矩陣����,因此無法利用得到特征值和特征向量����,因此需要進行變換,即AAT(m
x m)和ATA(n x n)�,這樣就可以計算特征向量和特征值了。
A = USVT AT = VSUT
AAT = USVT VSUT = US2UT
AAT U = U S2
同樣可以推導出: ATA V = V S2
總結下來��,SVD算法主要有六步:
A ���、計算出AAT
B �、計算出AAT的特征向量和特征值
C��、計算出ATA
D ���、計算出ATA的特征向量和特征值
E�����、計算ATA和ATA共有特征值的開方
F��、計算出U��、 S��、 V
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試����,點擊>>>
“CDA報名”
了解CDA考試詳情;
? 想學習CDA考試教材���,點擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫�����,點擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量�,點擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330