數(shù)據(jù)分析中非常實用的自編函數(shù)和代碼模塊整理
搞了接近四個周的模型開發(fā)工作�,今天整理代碼文件���,評分卡模型基本告一段落了。那么在模型開發(fā)或者是我們日常的數(shù)據(jù)分析工作中�,根據(jù)我們具體的業(yè)務需求,經常會重復地用到某些模塊的功能�。而這些模塊的功能在R的packages里是沒有的,這個時候����,我們一般是通過自己寫代碼實現(xiàn)功能��。通俗的說���,在數(shù)據(jù)分析工作中,我們經常會通過調用自編函數(shù)來實現(xiàn)某些高級的功能��。
一般在結束某項數(shù)據(jù)分析的工作之后�,對于使用頻率比較高的模塊功能,我會將實現(xiàn)代碼封裝在一個模塊函數(shù)當中���,并命好名����,方便下次調用����。其實你可以把它理解為自己開發(fā)的一個package,通過模塊化的調用��,提高我們在數(shù)據(jù)分析工作中的效率���,而不用每次都用造輪子式的方法來敲代碼��!
我一直認為這是一個很好的習慣���,你的自編函數(shù)或者說是代碼模塊積累得越多����,對于以后的建模工作來說會更加輕車熟路���,這也是每一個數(shù)據(jù)分析師在工作的過程當中積累的寶貴經驗�。
說了這么多����,今天給大家分享幾個我平時用得比較多����,實用性也比較強的自編函數(shù)和代碼模塊,方便大家借鑒參考���。
1����、centralImputation( )
根據(jù)樣本間的相似性填補缺失值方法�����,把實現(xiàn)代碼封裝在如下函數(shù)中,并將該函數(shù)命名為centralImputation
根據(jù)樣本之間的相似性填補缺失值是指用這些缺失值最可能的值來填補它們����,通常使用能代表變量中心趨勢的值進行填補,因為代表變量中心趨勢的值反映了變量分布的最常見值��。代表變量中心趨勢的指標包括平均值�����、中位數(shù)���、眾數(shù)等�����,那么我們采用哪些指標來填補缺失值呢�����?最佳選擇是由變量的分布來確定����,例如,對于接近正態(tài)分布的變量來說��,由于所有觀測值都較好地聚集在平均值周圍�����,因此平均值就就是填補該類變量缺失值的最佳選擇��。然而���,對于偏態(tài)分布或者離群值來說�,平均值就不是最佳選擇�����。因為偏態(tài)分布的大部分值都聚集在變量分布的一側����,平均值不能作為最常見值的代表���。對于偏態(tài)分布或者有離群值的分布而言�����,中位數(shù)是更好地代表數(shù)據(jù)中心趨勢的指標��。對于名義變量(如定性指標)�����,通常采用眾數(shù)填補缺失值��。
我們將上述分析放在一個統(tǒng)一的函數(shù)centralImputation( )中����,對于數(shù)值型變量,我們用中位數(shù)填補�,對于名義變量,我們用眾數(shù)填補�,函數(shù)代碼如下:
centralImputation<-function(data)
{
for(i in seq(ncol(data)))
if(any(idx<-is.na(data[,i])))
{
data[idx,i]<-centralValue(data[,i])
}
data}
centralValue<-function(x,ws=NULL)
{
if(is.numeric(x))
{
if(is.null(ws))
{
median(x,na.rm = T)
}
else if((s<sum(ws))>0)
{
sum(x*(ws/s))
}
else NA
}
else
{
x<-as.factor(x)
if(is.null(ws))
{
levels(x)[which.max(table(x))]
}
else
{
levels(x)[which.max(aggregate(ws,list(x),sum)[,2])]
}
}
}
調用上述函數(shù)對缺失值進行填補,代碼如下:
x<-centralImputation(data)
View(x) #查看填補結果
2�、knnImputation( )
根據(jù)變量間的相關關系填補缺失值(基于knn算法)
上述按照中心趨勢進行缺失值填補的方法,考慮的是數(shù)據(jù)每列的數(shù)值或字符屬性��,在進行缺失值填補時�����,我們也可以考慮每行的屬性���,即根據(jù)變量之間的相關關系填補缺失值���。
當我們采用數(shù)據(jù)集每行的屬性進行缺失值填補時�����,通常有兩種方法�����,第一種方法是計算k個(我用的k=10)最相近樣本的中位數(shù)并用這個中位數(shù)來填補缺失值����。如果缺失值是名義變量�,則使用這k個最近相似數(shù)據(jù)的加權平均值進行填補,權重大小隨著距離待填補缺失值樣本的距離增大而減小����,本文我們采用高斯核函數(shù)從距離獲得權重,即如果相鄰樣本距離待填補缺失值的樣本的距離為d�,則它的值在加權平均中的權重為:
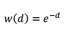
在尋找跟包含缺失值的樣本最近的k個鄰居樣本時��,最常用的經典算法是knn(k-nearest-neighbor) 算法�����,它通過計算樣本間的歐氏距離,來尋找距離包含缺失值樣本最近的k個鄰居��,樣本x和y之間歐式距離的計算公式如下:
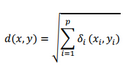
式中:δi()是變量i的兩個值之間的距離�����,即
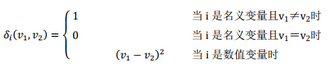
在計算歐式距離時�,為了消除變量間不同尺度的影響,通常要先對數(shù)值變量進行標準化���,即:
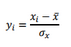
我們將上述根據(jù)數(shù)據(jù)集每行的屬性進行缺失值填補的方法����,封裝到knnImputation( )函數(shù)中�����,代碼如下:
knnImputation<-function(data,k=10,scale=T,meth="weighAvg",distData=NULL)
{
n<-nrow(data)
if(!is.null(distData))
{
distInit<-n+1
data<-rbind(data,distData)
}
else
{
disInit<-1
}
N<-nrow(data)
ncol<-ncol(data)
nomAttrs<-rep(F,ncol)
for(i in seq(ncol))
{
nomAttrs[i]<-is.factor(data[,1])
}
nomAttrs<-which(nomAttrs)
hasNom<-length(nomAttrs)
contAttrs<-setdiff(seq(ncol),nomAttrs)
dm<-data
if(scale)
{
dm[,contAttrs]<-scale(dm[,contAttrs])
}
if(hasNom)
{
for(i in nomAttrs)
dm[,i]<-as.integer(dm[,i])
}
dm<as.matrix(dm)
nas<-which(!complete.cases(dm))
if(!is.null(distData))
{
tgt.nas<-nas[nas<=n]
}
else
{
tgt.nas<-nas
}
if(length(tgt.nas)==0)
{
warning("No case has missing values. Stopping as there is nothing to do.")
}
xcomplete<-dm[setdiff(disInit:N,nas),]
if(nrow(xcomplete)<k)
{
stop("Not sufficient complete cases for computing neighbors.")
}
for(i in tgt.nas)
{
tgtAs<-which(is.na(dm[i,]))
dist<-scale(xcomplete,dm[i,],FALSE)
xnom<-setdiff(nomAttrs,tgtAs)
if(length(xnom))
{
dist[,xnom]<-ifelse(dist[,xnom]>0,1,dist[,xnom])
}
dist<-dist[,-tgtAs]
dist<-sqrt(drop(dist^2%*%rep(1,ncol(dist))))
ks<-order(dist)[seq(k)]
for(j in tgtAs) if(meth=="median")
{
data[i,j]<-centralValue(data[setdiff(distInit:N,nas),j][ks])
}
else
{
data[i,j]<-centralValue(data[setdiff(distInit:N,nas),j]
[ks],exp(-dist[ks]))
}
}
data[1:n,]
}
調用knnImputation( )函數(shù)��,用knn方法填補缺失值�,代碼如下:
d<-knnImputation(data)
View(d) #查看填補結果
以上兩個模塊化函數(shù)的分析和代碼實現(xiàn),大家get到了嗎�����。在數(shù)據(jù)分析最頭痛,最花時間的數(shù)據(jù)清洗和數(shù)據(jù)預處理環(huán)節(jié)�����,通過直接調用模塊化函數(shù)����,大大的節(jié)省了我們耗費的時間,提高數(shù)據(jù)分析工作的效率�����。
CDA數(shù)據(jù)分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試����,點擊>>>
“CDA報名”
了解CDA考試詳情;
? 想學習CDA考試教材�����,點擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量����,點擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330