數(shù)據(jù)處理流程和數(shù)據(jù)分析方法
大數(shù)據(jù)分析這件事用一種非技術的角度來看的話�����,就可以分成金字塔�����,自底向上的是三個部分�����,第一個部分是數(shù)據(jù)采集��,第二個部分是數(shù)據(jù)建模�,第三個部分是數(shù)據(jù)分析����,我們來分別看一下��。
【數(shù)據(jù)采集】

首先來說一下數(shù)據(jù)采集�,我在百度干了有七年是數(shù)據(jù)相關的事情。我最大的心得——數(shù)據(jù)這個事情如果想要更好�,最重要的就是數(shù)據(jù)源,數(shù)據(jù)源這個整好了之后�����,后面的事情都很輕松�。
用一個好的查詢引擎、一個慢的查詢引擎無非是時間上可能消耗不大一樣�,但是數(shù)據(jù)源如果是差的話,后面用再復雜的算法可能都解決不了這個問題�,可能都是很難得到正確的結論。
我覺得好的數(shù)據(jù)處理流程有兩個基本的原則���,一個是全�����,一個是細��。
●
全:就是說我們要拿多種數(shù)據(jù)源�,不能說只拿一個客戶端的數(shù)據(jù)源,服務端的數(shù)據(jù)源沒有拿�,數(shù)據(jù)庫的數(shù)據(jù)源沒有拿����,做分析的時候沒有這些數(shù)據(jù)你可能是搞歪了。另外����,大數(shù)據(jù)里面講的是全量,而不是抽樣����。不能說只抽了某些省的數(shù)據(jù),然后就開始說全國是怎么樣��?��?赡苡行┦》浅L厥?����,比如新疆�����、西藏這些地方它客戶端跟內地可能有很大差異的���。
● 細:其實就是強調多維度,在采集數(shù)據(jù)的時候盡量把每一個的維度��、屬性�����、字段都給它采集過來�����。比如:像 where�、who、how
這些東西給它替補下來��,后面分析的時候就跳不出這些能夠所選的這個維度���,而不是說開始的時候也圍著需求��。根據(jù)這個需求確定了產生某些數(shù)據(jù)���,到了后面真正有一個新的需求來的時候�����,又要采集新的數(shù)據(jù)�,這個時候整個迭代周期就會慢很多���,效率就會差很多,盡量從源頭抓的數(shù)據(jù)去做好采集��。
【數(shù)據(jù)建模】
有了數(shù)據(jù)之后����,就要對數(shù)據(jù)進行加工,不能把原始的數(shù)據(jù)直接報告給上面的業(yè)務分析人員���,它可能本身是雜亂的�,沒有經過很好的邏輯的�����。
這里就牽扯到數(shù)據(jù)建框,首先����,提一個概念就是數(shù)據(jù)模型。許多人可能對數(shù)據(jù)模型這個詞產生一種畏懼感����,覺得模型這個東西是什么高深的東西,很復雜�����,但其實這個事情非常簡單�。
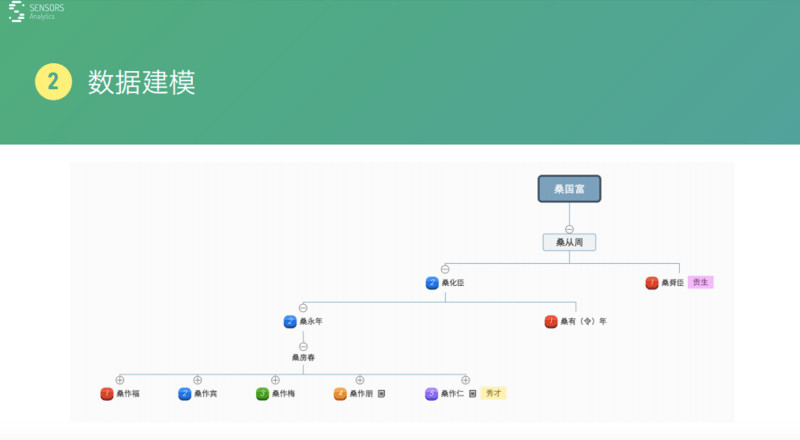
我春節(jié)期間在家干過一件事情,我自己家里面家譜在文革的時候被燒教了��,后來家里的長輩說一定要把家譜這些東西給存檔一下��,因為我會電腦�,就幫著用電腦去理了一下這些家族的數(shù)據(jù)這些關系,整個族譜這個信息���。
我們現(xiàn)實是一個個的人����,家譜里面的人,通過一個樹型的結構��,還有它們之間數(shù)據(jù)關系�,就能把現(xiàn)實實體的東西用幾個簡單圖給表示出來,這里就是一個數(shù)據(jù)模型����。
數(shù)據(jù)模型就是對現(xiàn)實世界的一個抽象化的數(shù)據(jù)的表示。我們這些創(chuàng)業(yè)公司經常是這么一個情況�����,我們現(xiàn)在這種業(yè)務���,一般前端做一個請求,然后對請求經過處理����,再更新到數(shù)據(jù)庫里面去,數(shù)據(jù)庫里面建了一系列的數(shù)據(jù)表���,數(shù)據(jù)表之間都是很多的依賴關系����。

比如,就像我圖片里面展示的這樣����,這些表一個業(yè)務項發(fā)展差不多一年以上它可能就牽扯到幾十張甚至上百張數(shù)據(jù)表,然后把這個表直接提供給業(yè)務分析人員去使用�,理解起來難度是非常大的。
這個數(shù)據(jù)模型是用于滿足你正常的業(yè)務運轉���,為產品正常的運行而建的一個數(shù)據(jù)模型�����。但是�,它并不是一個針對分析人員使用的模型�����。如果���,非要把它用于數(shù)據(jù)分析那就帶來了很多問題��。比如:它理解起來非常麻煩�。
另外�,數(shù)據(jù)分析很依賴表之間的這種格子�,比如:某一天我們?yōu)榱颂嵘阅?�,對某一表進行了拆分�,或者加了字段、刪了某個字短�,這個調整都會影響到你分析的邏輯。

這里�����,最好要針對分析的需求對數(shù)據(jù)重新進行解碼��,它內容可能是一致的����,但是我們的組織方式改變了一下。就拿用戶行為這塊數(shù)據(jù)來說���,就可以對它進行一個抽象,然后重新把它作為一個判斷表����。
用戶在產品上進行的一系列的操作,比如瀏覽一個商品��,然后誰瀏覽的,什么時間瀏覽的�,他用的什么操作系統(tǒng),用的什么瀏覽器版本��,還有他這個操作看了什么商品�,這個商品的一些屬性是什么,這個東西都給它進行了一個很好的抽象�����。這種抽樣的很大的好處很容易理解��,看過去一眼就知道這表是什么�����,對分析來說也更加方便��。

在數(shù)據(jù)分析方����,特別是針對用戶行為分析方面,目前比較有效的一個模型就是多維數(shù)據(jù)模型���,在線分析處理這個模型�,它里面有這個關鍵的概念,一個是維度�����,一個是指標���。
維度比如城市�,然后北京�、上海這些一個維度,維度西面一些屬性��,然后操作系統(tǒng)�,還有 IOS、安卓這些就是一些維度����,然后維度里面的屬性��。
通過維度交叉�����,就可以看一些指標問題����,比如用戶量���、銷售額,這些就是指標���。比如��,通過這個模型就可以看來自北京����,使用 IOS 的����,他們的整體銷售額是怎么樣的。
這里只是舉了兩個維度�����,可能還有很多個維度�����?���?傊?���,通過維度組合就可以看一些指標的數(shù)�,大家可以回憶一下,大家常用的這些業(yè)務的數(shù)據(jù)分析需求是不是許多都能通過這種簡單的模式給抽樣出來�����。
四����、數(shù)據(jù)分析方法
接下來看一下互聯(lián)網產品采用的數(shù)據(jù)分析方法。

對于互聯(lián)網產品常用的用戶消費分析來說���,有四種:
(1) 第一種是多維事件的分析�����,分析維度之間的組合�����、關系�����。
(2)第二種是漏斗分析��,對于電商���、訂單相關的這種行為的產品來說非常重要,要看不同的渠道轉化這些東西�����。
(3)第三種留存分析�,用戶來了之后我們希望他不斷的來,不斷的進行購買��,這就是留存���。
(4)第四種回訪���,回訪是留存的一種特別的形式,可以看他一段時間內訪問的頻次����,或者訪問的時間段的情況
【方法 1:多維事件分析法】
首先來看多維事件的分析��,這塊常見的運營��、產品改進這種效果分析����。其實��,大部分情況都是能用多維事件分析�����,然后對它進行一個數(shù)據(jù)上的統(tǒng)計�����。
1. 【三個關鍵概念】
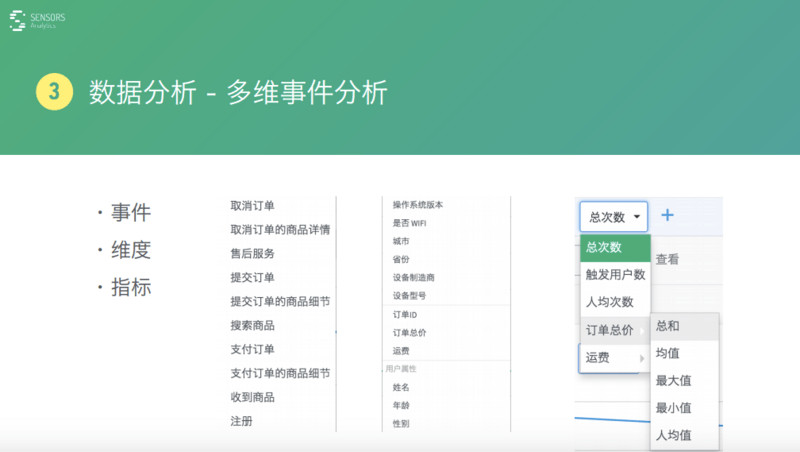
這里面其實就是由三個關鍵的概念��,一個就是事件�,一個是維度,一個是指標組成��。
l 事件就是說任何一個互聯(lián)網產品��,都可以把它抽象成一系列事件,比如針對電商產品來說���,可抽象到提交��、訂單、注冊����、收到商品一系列事件用戶行為。
l 每一個事件里面都包括一系列屬性�����。比如���,他用操作系統(tǒng)版本是否連 wifi�;比如���,訂單相關的運費����,訂單總價這些東西����,或者用戶的一些職能屬性����,這些就是一系列維度��。
l 基于這些維度看一些指標的情況�����。比如���,對于提交訂單來說���,可能是他總提交訂單的次數(shù)做成一個指標,提交訂單的人數(shù)是一個指標�����,平均的人均次數(shù)這也是一個指標���;訂單的總和��、總價這些也是一個指標���,運費這也是一個指標�����,統(tǒng)計一個數(shù)后就能把它抽樣成一個指標�。
2. 【多維分析的價值】
來看一個例子�,看看多維分析它的價值。
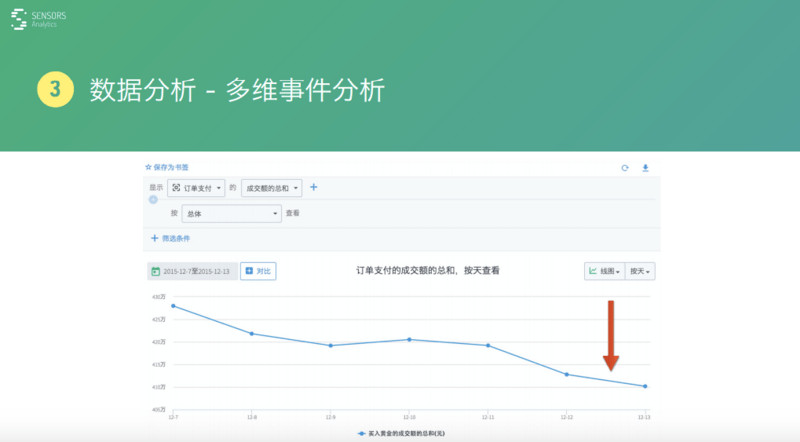
比如����,對于訂單支付這個事件來說��,針對整個總的成交額這條曲線����,按照時間的曲線會發(fā)現(xiàn)它一路在下跌。但下跌的時候��,不能眼睜睜的看著它�,一定要分析原因。
怎么分析這個原因呢���?常用的方式就是對維度進行一個拆解���,可以按照某些維度進行拆分�����,比如我們按照地域��,或者按照渠道�����,或者按照其他一些方式去拆開����,按照年齡段���、按照性別去拆開�,看這些數(shù)據(jù)到底是不是整體在下跌���,還是說某一類數(shù)據(jù)在下跌�����。
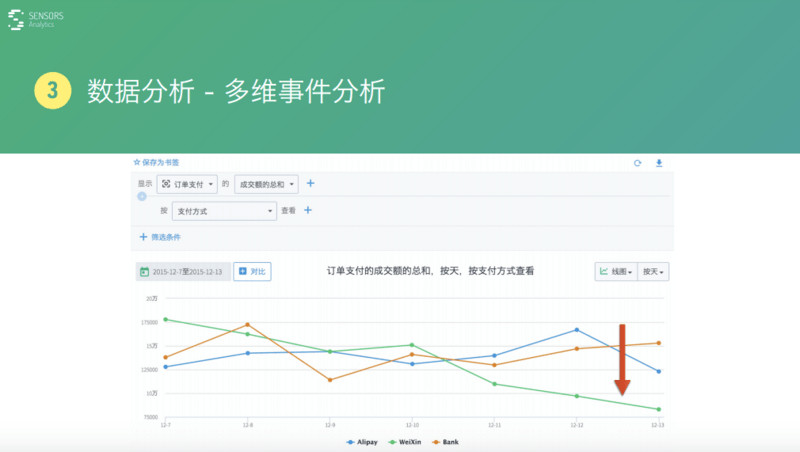
這是一個假想的例子——按照支付方式進行拆開之后�����,支付方式有三種�����,有用支付寶��、阿里 PAY��,或者用微信支付�����,或者用銀行看內的支付這三種方式���。
通過數(shù)據(jù)可以看到支付寶、銀行支付基本上是一個沉穩(wěn)的一個狀態(tài)�����。但是�,如果看微信支付,會發(fā)現(xiàn)從最開始最多�����,一路下跌到非常少,通過這個分析就知道微信這種支付方式�����,肯定存在某些問題�。
比如:是不是升級了這個接口或者微信本身出了什么問題,導致了它量下降下去了����?
【方法 2:漏斗分析】
漏斗分析會看,因為數(shù)據(jù)��,一個用戶從做第一步操作到后面每一步操作����,可能是一個雜的過程。


通過這個漏斗���,就能分析一步步的轉化情況��,然后每一步都有流失�����,可以分析不同的渠道其轉化情況如何����。比如,打廣告的時候發(fā)現(xiàn)來自百度的用戶漏斗轉化效果好���,就可能在廣告投放上就在百度上多投一些�����。
【方法 3:留存分析】

比如����,搞一個地推活動��,然后來了一批注冊用戶�����,接下來看它的關鍵行為上面操作的特征�����,比如當天它有操作����,第二天有多少人會關鍵操作,第 N 天有多少操作���,這就是看它留下來這個情況��。
【方法 4:回訪分析】
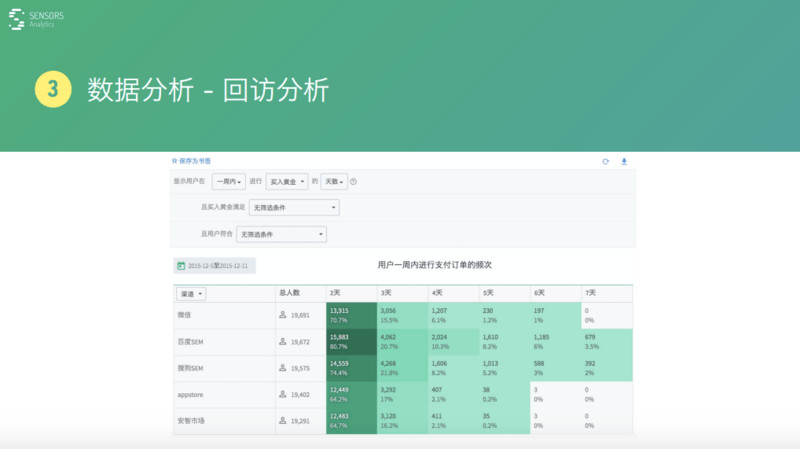
回訪就是看進行某個行為的一些中度特征����,如對于購買黃金這個行為來說�����,在一周之內至少有一天購買黃金的人有多少人���,至少有兩天的有多少人����,至少有 7 天的有多少人���,或者說購買多少次數(shù)這么一個分布���,就是回訪回購這方面的分析���。
上面說的四種分析結合起來去使用,對一個產品的數(shù)據(jù)支撐����、數(shù)據(jù)驅動的這種深度就要比只是看一個宏觀的訪問量或者活躍用戶數(shù)就要深入很多。
五�、運營分析實踐
下面結合個人在運營和分析方面的實踐,給大家分享一下���。
【案例 1:UGC 產品】

首先�����,來看 UGC 產品的數(shù)據(jù)分析的例子����??赡軙治鏊脑L問量是多少,新增用戶數(shù)是多少�,獲得用戶數(shù)多少���,發(fā)帖量���、減少量�。
諸如貼吧�、百度知道,還有知乎都屬于這一類的產品��。對于這樣一個產品�,會有很多數(shù)據(jù)指標,可以從某一個角度去觀察這個產品的情況���。那么��,問題就來了——這么多的指標����,到底要關注什么��?不同的階段應該關注什么指標�?這里,就牽扯到一個本身指標的處理����,還有關鍵指標的問題�。
【案例 2:流失用戶召回】
這種形式可能對其他產品就很有效����,但是對我們這個產品來說,因為我們這是一個相對來說目標比較明確并且比較小眾一點的差別��,所以這個投放的效果可能就沒那么明顯�����。
在今年元旦的時候��,因為之前申請試用我們那個產品已經有很多人�����,但是這里面有一萬人我們給他發(fā)了帳號他也并沒有回來����,我們過年給大家拜拜年,然后去匯報一下進展看能不能把他們撈過來一部分����。
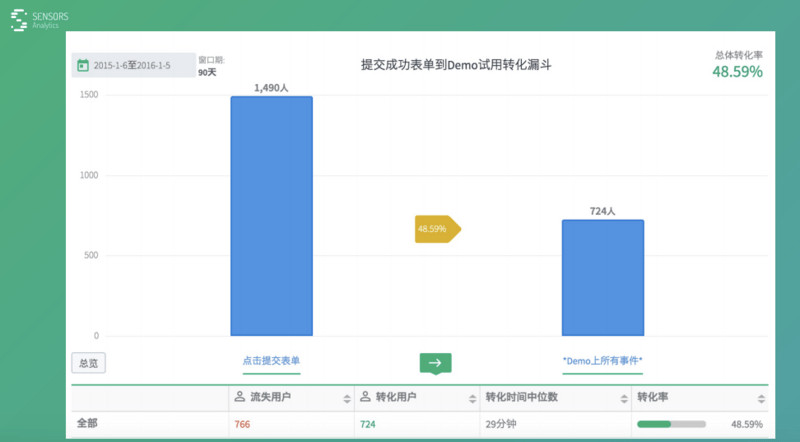
這是元旦的時候我們產品的整體用戶情況,到了元旦為止�,9月25號發(fā)布差不多兩三個月時間����,那個時候差不多有 1490 個人申請試用了我們這個產品����。但是��,真正試用的有 724 個���,差不多有一半��,另外一半就跑了�,就流失了�����。
我們就想把這部分人抽出來給他們進行一個招回活動�����,這里面流失用戶我們就可以把列表導出來�,這是我們自己的產品就有這樣的功能。有人可能疑惑我們怎么拿到用戶的這些信息呢����?
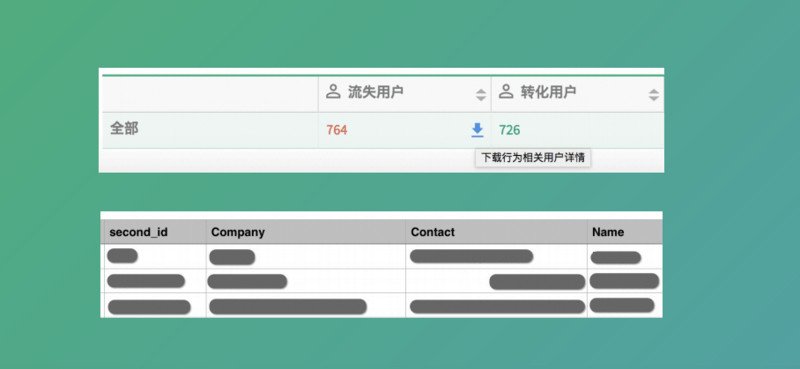
這些不至于添加��,因為我們申請試用的時候就讓他填一下姓名�����、聯(lián)系方式����,還有他的公司這些信息���。對于填郵箱的我們就給發(fā)郵件的�����,對于發(fā)手機號的我們就給他發(fā)短信�,我們分析這兩種渠道帶來的效果�。
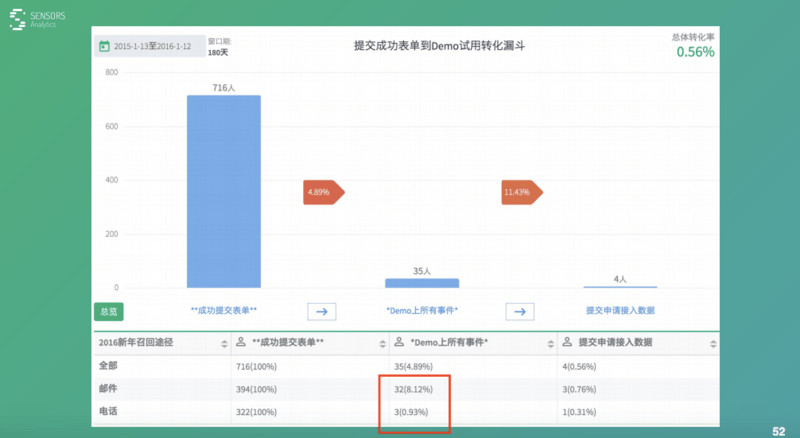
先說總體,總體我們發(fā)了 716 個人�,這里面比前面少了一點,我把一些不靠譜的這些信息人工給它干掉了��。接下來���,看看真正有 35 個人去體驗了這個產品���,然后 35 個人里面有 4 個人申請接入數(shù)據(jù)�����。
因為我們在產品上面做了一個小的改進,在測試環(huán)境上面��,對于那些測試環(huán)境本身是一些數(shù)據(jù)他玩一玩�����,玩了可能感興趣之后就會試一下自己的真實數(shù)據(jù)����。這個時候,我們上來有一個鏈接引導他們去申請接入自己的數(shù)據(jù)�����,走到這一步之后就更可能轉化成我們的正式客戶����。
這兩種方式轉化效果我們其實也很關心���,招回的效果怎么樣,我們看下面用紅框表示出來��,郵件發(fā)了 394 封����。最終有 32 個人真正過來試用了,電話手機號322 封�����,跟郵件差不多��,但只有 3 個過來����,也就是說兩種效果差了 8 倍。
這其實也提醒大家��,短信這種方式可能許多人看短信的比較少�。當然,另一方面跟我們自己產品特征有關系�����,我們這個產品是一個 PC 上用起來更方便的一個產品。許多人可能在手機上看到這個鏈接也不方便點開���,點開之后輸入帳號也麻煩一點�����。所以�,導致這個效果比較差�。
CDA數(shù)據(jù)分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�����,點擊>>>
“CDA報名”
了解CDA考試詳情����;
? 想學習CDA考試教材,點擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫�,點擊>>> “CDA題庫” 了解CDA考試詳情;
? 想了解CDA考試含金量,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330