將SPSS分析技術(shù)應(yīng)用于大數(shù)據(jù)
了解 SPSS? 中處理大數(shù)據(jù)的新功能?,F(xiàn)在可以對(duì) SPSS
分析資產(chǎn)輕松地進(jìn)行修改,以便連接到不同的大數(shù)據(jù)來(lái)源����,它們還可以在不同的部署模式(批處理或?qū)崟r(shí)模式)下運(yùn)行�。SPSS 平臺(tái)的組件現(xiàn)在可與 IBM
Netezza、InfoSphere? BigInsights? 和 InfoSphere Streams
結(jié)合使用����,以支持分析師對(duì)大數(shù)據(jù)使用強(qiáng)大的分析工具。
數(shù)十年來(lái)����,IBM SPSS 為統(tǒng)計(jì)人員和數(shù)據(jù)科學(xué)家提供了強(qiáng)大的工具。多年來(lái)����,SPSS
平臺(tái)已發(fā)生了演變,支持數(shù)據(jù)挖掘流程的所有階段�����,包括模型開發(fā)��、模型部署和模型刷新����。在過(guò)去兩年�����,SPSS 中增加了處理大數(shù)據(jù)的新功能。本文將介紹
SPSS 如何與 IBM 大數(shù)據(jù)產(chǎn)品組合的 3 個(gè)組件相集成:Netezza��、InfoSphere BigInsights 和
InfoSphere Streams�。
SPSS 平臺(tái)概述
與大數(shù)據(jù)集成的 SPSS 軟件組件:
1.SPSS Modeler
2.SPSS Analytic Server
3.SPSS Collaboration and Deployment Services
4.SPSS Analytic Catalyst
SPSS Modeler 是一個(gè)數(shù)據(jù)挖掘工作臺(tái),用于分析數(shù)據(jù)和部署分析資產(chǎn)�。通用術(shù)語(yǔ)分析資產(chǎn)
用于描述解決某個(gè)業(yè)務(wù)問(wèn)題的一個(gè)操作集合。數(shù)據(jù)科學(xué)家在描述使用數(shù)據(jù)挖掘工具開發(fā)的資產(chǎn)時(shí)����,通常會(huì)使用術(shù)語(yǔ)模型 或預(yù)測(cè)模型。除了模型之外����,SPSS
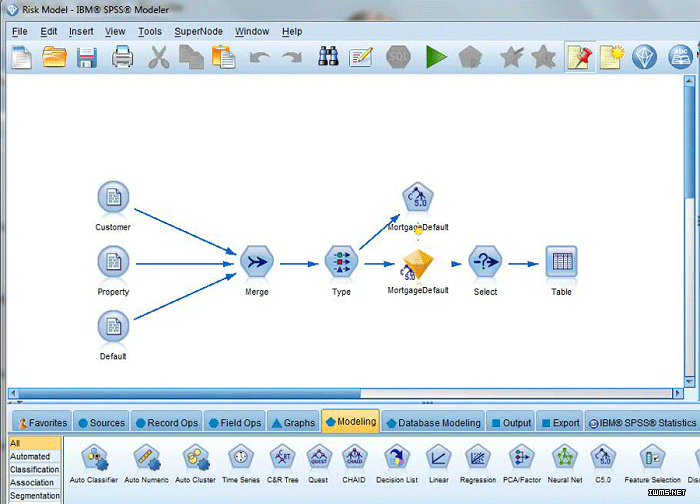
分析資產(chǎn)還可包含數(shù)據(jù)準(zhǔn)備步驟和業(yè)務(wù)規(guī)則。圖 1 顯示了 SPSS Modeler
中開發(fā)的一個(gè)示例分析資產(chǎn)�����。在此示例中�,我們使用一個(gè)決策樹模型來(lái)執(zhí)行貸款違約預(yù)測(cè)。分析資產(chǎn)執(zhí)行以下操作:
1.合并來(lái)自 3 個(gè)歷史數(shù)據(jù)源的數(shù)據(jù)
2.使用一個(gè) Type 節(jié)點(diǎn)識(shí)別用于模型預(yù)測(cè)的目標(biāo)變量 (MortgageDefault)
3.構(gòu)建一個(gè)基于 C5.0 決策樹算法的模型
4.選擇具有積極的貸款違約預(yù)測(cè)的記錄
5.將結(jié)果顯示在一個(gè)表中
圖 1. SPSS Modeler 中開發(fā)的分析資產(chǎn)
該圖顯示了決策樹模型圖
SPSS Modeler
是一個(gè)可視編程環(huán)境����。分析資產(chǎn)可通過(guò)連接畫布上的可視編程節(jié)點(diǎn)來(lái)創(chuàng)建;在運(yùn)行時(shí),節(jié)點(diǎn)按照連接箭頭的方向執(zhí)行���。節(jié)點(diǎn)可按照相關(guān)功能進(jìn)行組織:Sources����、Record
Operations�、Field Operations、Modeling 等��。Modeling 選項(xiàng)卡顯示用于生成模型的算法(參見圖
2)���。SPSS 發(fā)布了 27 個(gè)建模算法和整套的節(jié)點(diǎn)����,對(duì)一個(gè)數(shù)據(jù)集運(yùn)行多種算法并選擇最佳的節(jié)點(diǎn)����。除了所描述的可視節(jié)點(diǎn)之外,如果分析師希望擴(kuò)展
SPSS Modeler 的基本功能���,那么他們可以使用 SQL 函數(shù)�、R 模型和自定義開發(fā)的節(jié)點(diǎn)����。
圖 2. 包含生成模型的算法的 Modeling 選項(xiàng)卡
Modeling 選項(xiàng)卡顯示了每種算法的符號(hào)
分析師使用歷史數(shù)據(jù)來(lái)構(gòu)建模型����。創(chuàng)建模型后����,分析師會(huì)修改分析資產(chǎn)����,以便對(duì)操作數(shù)據(jù)進(jìn)行評(píng)分(參見圖 3)。我們不再需要 Mortgage
Default 數(shù)據(jù)源��,因?yàn)樗瑲v史數(shù)據(jù)����。我們刪除了 Type 和 Decision Tree 算法節(jié)點(diǎn)。C5
決策樹算法節(jié)點(diǎn)用于構(gòu)建模型�。創(chuàng)建的模型用金塊圖標(biāo)表示 (MortgageDefault)。分析師將 Table 節(jié)點(diǎn)替換為一個(gè) Export
節(jié)點(diǎn)��,這會(huì)將數(shù)據(jù)寫入一個(gè)數(shù)據(jù)庫(kù)表中?����,F(xiàn)在可以將這個(gè)分析資產(chǎn)用于對(duì)新貸款申請(qǐng)進(jìn)行批量或?qū)崟r(shí)評(píng)分。
圖 3. 包含 Type��、Decision Tree 并刪除了 Mortgage Default 數(shù)據(jù)源的已修改模型
更新的圖表僅顯示剩下的算法
用于大數(shù)據(jù)的第二個(gè) SPSS 組件是 SPSS Analytic Server��。它管理對(duì) Hadoop 數(shù)據(jù)源的訪問(wèn)��,并設(shè)計(jì)一個(gè)
Modeler 流在 Hadoop 中的運(yùn)行�。Modeler 操作以 MapReduce 作業(yè)的形式在 Hadoop
中運(yùn)行,得到一個(gè)提供了高性能和高可伸縮性的解決方案�����。
用于大數(shù)據(jù)的下一個(gè) SPSS 組件是 SPSS Collaboration and Deployment Services (C&DS)���。C&DS 執(zhí)行兩種主要功能:
用作分析資產(chǎn)的存儲(chǔ)庫(kù)�。在將某項(xiàng)資產(chǎn)存儲(chǔ)在存儲(chǔ)庫(kù)中后�����,就可以使用它來(lái)設(shè)計(jì)批處理作業(yè)����。該存儲(chǔ)庫(kù)還提供了與 InfoSphere Streams 的連接,以便實(shí)時(shí)更新 SPSS 模型��。
提供一個(gè)接口來(lái)計(jì)劃批處理作業(yè),建模使用數(shù)據(jù)庫(kù)和 Hadoop 數(shù)據(jù)源的刷新作業(yè)����。
SPSS Analytic Catalyst 通過(guò)一種易于使用的 Web
接口來(lái)執(zhí)行統(tǒng)計(jì)分析。它是為可能沒有深入理解數(shù)據(jù)挖掘的業(yè)務(wù)用戶設(shè)計(jì)的���。SPSS Analytic Catalyst
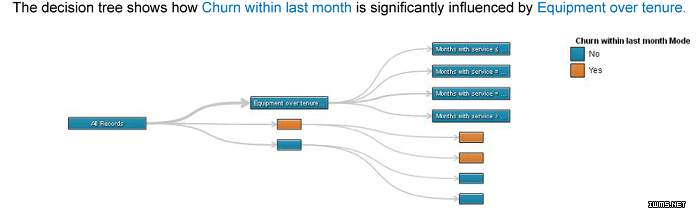
向選定的數(shù)據(jù)源應(yīng)用多種算法和統(tǒng)計(jì)分析技術(shù)。結(jié)果可以通過(guò)可視元素和純語(yǔ)言解釋來(lái)呈現(xiàn)�。圖 4 顯示了一個(gè) SPSS Analytic
Catalyst 項(xiàng)目的示例輸出。
圖 4. SPSS Analytic Catalyst 返回對(duì)某個(gè)數(shù)據(jù)源的分析的結(jié)果
決策樹顯示了一個(gè)基于設(shè)備年齡的結(jié)構(gòu)
SPSS Analytic Catalyst 分析在 Hadoop 中運(yùn)行�����。與 Hadoop 中現(xiàn)有數(shù)據(jù)的數(shù)據(jù)源連接由 SPSS
Analytic Server 提供�。SPSS 與 InfoSphere BigInsights 的集成 一節(jié)中描述的所有數(shù)據(jù)源都可以用在
SPSS Analytic Catalyst 中。較小的數(shù)據(jù)集可通過(guò) Web 界面加載到 SPSS Analytic Catalyst 中�。一個(gè)
Hadoop 發(fā)行版是安裝 SPSS Analytic Catalyst 的一個(gè)必要軟件。安裝之后�����,無(wú)需額外的集成即可對(duì)大數(shù)據(jù)執(zhí)行分析�。
接下來(lái),讓我們深入講講 SPSS 與 Netezza�、InfoSphere BigInsights 和 InfoSphere Streams 的集成�。
SPSS 與 Netezza 的集成
Netezza 是一個(gè)高性能數(shù)據(jù)倉(cāng)庫(kù)����。SPSS 和 Netezza 的集成是 SPSS 的一種典型的大數(shù)據(jù)集成場(chǎng)景。存儲(chǔ)在 Netezza 中的數(shù)據(jù)可用于模型構(gòu)建����、評(píng)分和模型刷新。
SPSS Modeler 通過(guò) Netezza 所提供的一個(gè)開放數(shù)據(jù)庫(kù)連接 (ODBC) 驅(qū)動(dòng)程序連接到 Netezza�。Netezza
中存儲(chǔ)的數(shù)據(jù)可用作一個(gè) SPSS Modeler 流的輸入或輸出數(shù)據(jù)源。SPSS Modeler 支持對(duì) Netezza 執(zhí)行 SQL
推回:在運(yùn)行時(shí)���,Modeler 流被轉(zhuǎn)換為 SQL 并在 Netezza 中執(zhí)行����。SQL 推回操作不需要手動(dòng)將 SPSS 代碼導(dǎo)入
Netezza 中��。導(dǎo)入由 SPSS 平臺(tái)自動(dòng)處理�。
除了 SQL 推回操作之外,SPSS 為 Netezza 提供了一個(gè)評(píng)分適配器�����,它允許使用無(wú)法轉(zhuǎn)換為 SQL 的 SPSS 節(jié)點(diǎn)作為 Netezza 中的用戶定義的函數(shù) (UDF)����。
SPSS Modeler 還支持在 Netezza 數(shù)據(jù)庫(kù)中進(jìn)行挖掘����。對(duì)于 SQL 推回操作和評(píng)分適配器�,SPSS Modeler
將會(huì)生成代碼并在 Netezza 中運(yùn)行它。數(shù)據(jù)庫(kù)中挖掘節(jié)點(diǎn)由 Netezza 提供并由 SPSS
調(diào)用�����。所有描述的實(shí)現(xiàn)的最終結(jié)果都是讓性能得到了提升����,因?yàn)閿?shù)據(jù)無(wú)需在 Netezza 和 SPSS 服務(wù)器之間移動(dòng)���。
用于 Netezza 數(shù)據(jù)庫(kù)中挖掘的建模節(jié)點(diǎn)如圖 5 中所示�。一些模型可同時(shí)用于 SPSS 和 Netezza 中����,而其他模型是
Netezza 所獨(dú)有的。Netezza 中的數(shù)據(jù)庫(kù)中挖掘節(jié)點(diǎn)通過(guò)安裝 INZA 包來(lái)啟用����,該包包含在 Netezza 中����。默認(rèn)情況下�����,在
SPSS Modeler 中會(huì)提供 Netezza 數(shù)據(jù)庫(kù)中數(shù)據(jù)挖掘的用戶界面:這些節(jié)點(diǎn)可通過(guò)選擇 Tools > Options
> Helper Applications 顯示在模型面板中���。
圖 5. 用于 Netezza 數(shù)據(jù)庫(kù)中數(shù)據(jù)挖掘的建模節(jié)點(diǎn)
該圖顯示了包含建模節(jié)點(diǎn)的圖標(biāo)的數(shù)據(jù)庫(kù)建模選項(xiàng)卡
SPSS 與 InfoSphere BigInsights 的集成
InfoSphere BigInsights 是一個(gè)企業(yè)級(jí)的 Hadoop 發(fā)行版���。類似于 Netezza,與 InfoSphere
BigInsights 的集成可用在數(shù)據(jù)挖掘流程的所有階段�����。SPSS 與 InfoSphere BigInsights 的集成由 SPSS
Analytic Server 啟用����。SPSS Analytic Server 隱藏了訪問(wèn) Hadoop 數(shù)據(jù)源的復(fù)雜性,支持分析師對(duì)
Hadoop 中存儲(chǔ)的數(shù)據(jù)應(yīng)用了 SPSS Modeler 中提供的所有數(shù)據(jù)挖掘操作�����。在 SPSS Analytic Server
中配置后���,可通過(guò) Modeler 中的一個(gè)來(lái)源節(jié)點(diǎn)對(duì) Hadoop 數(shù)據(jù)源進(jìn)行輕松的訪問(wèn)(參見 圖 6)�。SPSS Analytic
Server 支持 HDFS 和 HCatalog 數(shù)據(jù)源。HCatalog 被用作 NoSQL 數(shù)據(jù)源的一個(gè)網(wǎng)關(guān)��,這些數(shù)據(jù)源包括
Hive����、HBase、Accumulo��、JSON 和 XML��。
InfoSphere BigInsights Quick Start Edition
InfoSphere BigInsights Quick Start Edition 是 IBM 基于 Hadoop 的
InfoSphere BigInsights 產(chǎn)品的一個(gè)可下載的免費(fèi)版本���。使用 Quick Start Edition,您可嘗試 IBM
構(gòu)建的功能來(lái)提高開源 Hadoop 的價(jià)值�����,比如 Big SQL���、文本分析和
BigSheets����。引導(dǎo)式學(xué)習(xí)可讓您的學(xué)習(xí)體驗(yàn)非常順利,包括循序漸進(jìn)�、自訂進(jìn)度的教程和視頻,可幫助您讓 Hadoop
為您工作�。沒有時(shí)間和數(shù)據(jù)限制,您可以在自己的時(shí)間里試驗(yàn)大量數(shù)據(jù)����。觀看視頻,學(xué)習(xí)教程 (PDF) 和 立即下載 BigInsights Quick
Start Edition��。
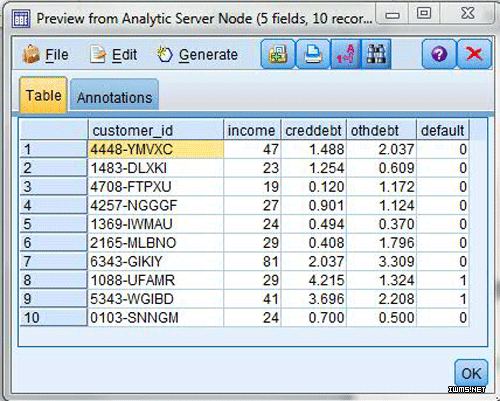
圖 6. 在 SPSS Modeler 來(lái)源節(jié)點(diǎn)中訪問(wèn) Hadoop 數(shù)據(jù)源
預(yù)覽模式中的 Table 選項(xiàng)卡顯示了客戶 ID
SPSS 為多個(gè) SPSS Modeler 節(jié)點(diǎn)提供了 Hadoop 中 執(zhí)行功能�����,這些是支持以 MapReduce 作業(yè)形式在 Hadoop 內(nèi)執(zhí)行操作的節(jié)點(diǎn)���。以下 SPSS Modeler 節(jié)點(diǎn)支持 Hadoop 內(nèi)的執(zhí)行操作:
1.大多數(shù)數(shù)據(jù)準(zhǔn)備操作
2.模型評(píng)分:
C&RT����、Quest�、CHAID、Linear���、Regression����、Neural
Net、C5.0�、Logistic、Genlin���、GLMM��、Cox��、SVM����、Bayes Net����、TwoStep、KNN�����、Decision
List�、Discriminant、Self Learning��、Anomaly
Detection�����、Apriori���、Carma�、K-Means��、Kohonen 和 Text Mining
3.模型構(gòu)建:Linear����、Neural Net、C&RT���、Chaid 和 Quest
SPSS Analytic Server 支持在 Hadoop 中運(yùn)行 R 模型���。一個(gè)流可同時(shí)包含 SPSS 和 R 模型。
SPSS Analytic Server 還提供了與數(shù)據(jù)庫(kù)數(shù)據(jù)源的連接�。此特性支持您將數(shù)據(jù)庫(kù)和 Hadoop 數(shù)據(jù)合并到單個(gè) SPSS
Modeler 流中。在運(yùn)行時(shí)��,SPSS Analytic Server 與 SPSS Modeler 服務(wù)器聯(lián)合,確定 SPSS
Modeler 流的最佳運(yùn)行環(huán)境(SQL 推回操作或 Hadoop 內(nèi)的執(zhí)行操作)��。
SPSS Analytic Server 支持 InfoSphere BigInsights 2.0 和 2.1����、IBM
PureData? for Hadoop 設(shè)備、InfoSphere BigInsights with Platform
Symphony��,以及其他多個(gè) Hadoop 發(fā)行版��。
SPSS 與 InfoSphere Streams 的集成
InfoSphere Streams 是一個(gè)處理流數(shù)據(jù)的 IBM 平臺(tái)��。在實(shí)時(shí)處理需要高級(jí)分析時(shí)會(huì)使用 SPSS 集成���。實(shí)時(shí)應(yīng)用預(yù)測(cè)分析的用例的示例包括網(wǎng)絡(luò)安全���、銀行和信用卡欺詐檢測(cè)、預(yù)測(cè)性維護(hù)�����,以及實(shí)時(shí)營(yíng)銷產(chǎn)品�。
InfoSphere Streams Quick Start Edition
InfoSphere Streams Quick Start Edition 是 InfoSphere Streams
的一個(gè)免費(fèi)、可下載的非生產(chǎn)版本���,后者是 IBM
的高性能計(jì)算平臺(tái)����,用戶開發(fā)的應(yīng)用程序在接收來(lái)自數(shù)千個(gè)實(shí)時(shí)來(lái)源的信息時(shí)可以快速地執(zhí)行獲取����、分析和關(guān)聯(lián)。沒有數(shù)據(jù)或時(shí)間限制��,InfoSphere
Streams Quick Start Edition
支持您在自己的獨(dú)特環(huán)境中試驗(yàn)流計(jì)算���。構(gòu)建一個(gè)強(qiáng)大的分析平臺(tái)���,它能夠處理難以置信的高數(shù)據(jù)吞吐量,高達(dá)每秒數(shù)百萬(wàn)個(gè)事件或消息��。立即下載
InfoSphere Streams Quick Start Edition���。
InfoSphere Streams 和 SPSS 集成在數(shù)據(jù)挖掘生命周期的部署階段中�。模型使用存儲(chǔ)在數(shù)據(jù)庫(kù)或 Hadoop
中的歷史數(shù)據(jù)來(lái)開發(fā)����,部署在 InfoSphere Streams 中以進(jìn)行實(shí)時(shí)評(píng)分�����。InfoSphere Streams 和 SPSS 的集成由
SPSS Scoring Toolkit 啟用��,安裝在 InfoSphere Streams 中����。Scoring Toolkit 是 SPSS
Collaboration and Deployment Services (C&DS) 的一個(gè)組件����。
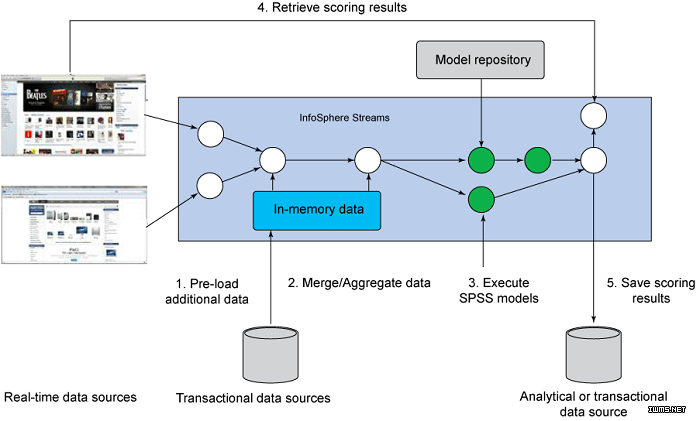
在安裝該工具包后,InfoSphere Streams 開發(fā)人員可使用操作符 將 SPSS 分析資產(chǎn)與 InfoSphere
Streams 應(yīng)用程序相集成�。publish 操作符在應(yīng)用程序開發(fā)階段用來(lái)獲取適合 InfoSphere Streams 部署的 SPSS
模型。scoring 操作符在運(yùn)行時(shí)用于調(diào)用 SPSS 模型���。repository 操作符可用于自動(dòng)從 SPSS
模型存儲(chǔ)庫(kù)拉取模型的最新版本��。圖 7 顯示了 SPSS 與 InfoSphere Streams 運(yùn)行時(shí)的集成的圖表���。
圖 7. SPSS 與 InfoSphere Streams 的運(yùn)行時(shí)集成圖
該圖顯示了數(shù)據(jù)源、存儲(chǔ)庫(kù)����、SPSS 模型的工作流
結(jié)束語(yǔ)
SPSS 平臺(tái)與 Netezza��、InfoSphere BigInsights 和 InfoSphere Streams
的內(nèi)置集成能夠讓分析師使用強(qiáng)大的分析工具處理大數(shù)據(jù)���。SPSS
組件(提供了全面的分析功能)和大數(shù)據(jù)平臺(tái)(支持可伸縮性和性能)的組合���,為大數(shù)據(jù)開發(fā)人員提供了訪問(wèn) SPSS 技術(shù)的能力��??梢暂p松地對(duì) SPSS
分析資產(chǎn)進(jìn)行修改��,以便連接到不同的大數(shù)據(jù)來(lái)源����,這些分析資產(chǎn)可以在不同的部署模式(批處理或?qū)崟r(shí)模式)下運(yùn)行。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試���,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情�����;
? 想學(xué)習(xí)CDA考試教材��,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫(kù)�,點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情���;
? 想了解CDA考試含金量�,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情���;














 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330