Python中常用操作字符串的函數(shù)與方法總結(jié)
這篇文章主要介紹了Python中常用操作字符串的函數(shù)與方法總結(jié),包括字符串的格式化輸出與拼接等基礎(chǔ)知識,需要的朋友可以參考下
例如這樣一個字符串 Python���,它就是幾個字符:P,y,t,h,o,n���,排列起來�����。這種排列是非常嚴(yán)格的�����,不僅僅是字符本身��,而且還有順序��,換言之���,如果某個字符換了,就編程一個新字符串了����;如果這些字符順序發(fā)生變化了,也成為了一個新字符串��。
在 Python 中���,把像字符串這樣的對象類型(后面還會冒出來類似的其它有這種特點的對象類型����,比如列表)���,統(tǒng)稱為序列���。顧名思義,序列就是“有序排列”����。
比如水泊梁山的 108 個好漢(里面分明也有女的,難道女漢子是從這里來的嗎��?)��,就是一個“有序排列”的序列��。從老大宋江一直排到第 108 位金毛犬段景住���。在這個序列中�����,每個人有編號��,編號和每個人一一對應(yīng)�。1 號是宋江,2 號是盧俊義����。反過來,通過每個人的姓名��,也能找出他對應(yīng)的編號�����。武松是多少號�?14 號。李逵呢�?22 號。
在 Python 中�,給這些編號取了一個文雅的名字,叫做索引(別的編程語言也這么稱呼���,不是 Python 獨有的��。)�。
索引和切片
前面用梁山好漢的為例說明了索引��。再看 Python 中的例子:
>>> lang = "study Python"
>>> lang[0]
's'
>>> lang[1]
't'
有一個字符串���,通過賦值語句賦給了變量 lang���。如果要得到這個字符串的第一個單詞 s,可以用 lang[0]���。當(dāng)然�����,如果你不愿意通過賦值語句�����,讓變量 lang 來指向那個字符串���,也可以這樣做:
>>> "study Python"[0]
's'
效果是一樣的���。因為 lang 是標(biāo)簽,就指向了 "study Python" 字符串�����。當(dāng)讓 Python 執(zhí)行 lang[0] 的時候�,就是要轉(zhuǎn)到那個字符串對象,如同上面的操作一樣���。只不過��,如果不用 lang 這么一個變量����,后面如果再寫���,就費筆墨了���,要每次都把那個字符串寫全了。為了省事��,還是復(fù)制給一個變量吧。變量就是字符串的代表了�����。
字符串這個序列的排序方法跟梁山好漢有點不同�,第一個不是用數(shù)字1表示,而是用數(shù)字 0 表示����。不僅僅 Python�����,其它很多語言都是從 0 開始排序的����。為什么這樣做呢?這就是規(guī)定��。當(dāng)然�,這個規(guī)定是有一定優(yōu)勢的。此處不展開���,有興趣的網(wǎng)上去 google 一下����,有專門對此進行解釋的文章。
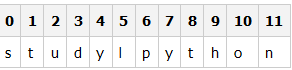
上面的表格中���,將這個字符串從第一個到最后一個進行了排序����,特別注意�����,兩個單詞中間的那個空格�����,也占用了一個位置���。
通過索引能夠找到該索引所對應(yīng)的字符����,那么反過來�����,能不能通過字符,找到其在字符串中的索引值呢���?怎么找����?
>>> lang.index("p")
6
就這樣����,是不是已經(jīng)能夠和梁山好漢的例子對上號了?只不過區(qū)別在于第一個的索引值是 0�。
如果某一天,宋大哥站在大石頭上��,向著各位弟兄大喊:“兄弟們��,都排好隊�����?���!钡刃值軅兣藕弥?����,宋江說:“現(xiàn)在給各位沒有老婆的兄弟分配女朋友,我這里已經(jīng)有了名單��,我念叨的兄弟站出來�。不過我是按照序號來念的。第 29 號到第 34 號先出列�,到旁邊房子等候分配女朋友?���!?br />
在前面的例子中 lang[1] 能夠得到原來字符串的第二個字符 t,就相當(dāng)于從原來字符串中把這個“切”出來了��。不過����,我們這么“切”卻不影響原來字符串的完整性,當(dāng)然可以理解為將那個字符 t 賦值一份拿出來了��。
那么宋江大哥沒有一個一個“切”���,而是一下將幾個兄弟叫出來��。在 Python 中也能做類似事情�����。
>>> lang
'study Python' #在前面“切”了若干的字符之后����,再看一下該字符串,還是完整的����。
>>> lang[2:9]
'udy pyt'
通過 lang[2:9]要得到部分(不是一個)字符,從返回的結(jié)果中可以看出���,我們得到的是序號分別對應(yīng)著 2,3,4,5,6,7,8(跟上面的表格對應(yīng)一下)字符(包括那個空格)��。也就是�,這種獲得部分字符的方法中����,能夠得到開始需要的以及最后一個序號之前的所對應(yīng)的字符�。有點拗口,自己對照上面的表格數(shù)一數(shù)就知道了��。簡單說就是包括開頭���,不包括結(jié)尾�。
上述,不管是得到一個還是多個�����,通過索引得到字符的過程�����,稱之為切片�。
切片是一個很有意思的東西?���?梢浴扒小背霾簧倩幽兀?br />
>>> lang
'study Python'
>>> b = lang[1:] # 得到從 1 號到最末尾的字符�,這時最后那個需要不用寫
>>> b
'tudy Python'
>>> c = lang[:] # 得到所有字符
>>> c
'study Python'
>>> d = lang[:10] # 得到從第一個到 10 號之前的字符
>>> d
'study pyth'
在獲取切片的時候,如果分號的前面或者后面的序號不寫�,就表示是到最末(后面的不寫)或第一個(前面的不寫)
lang[:10]的效果和 lang[0:10]是一樣的。
>>> e = lang[0:10]
>>> e
'study pyth'
那么�,lang[1:]和 lang[1:11]效果一樣嗎?請思考后作答��。
>>> lang[1:11]
'tudy pytho'
>>> lang[1:]
'tudy python'
果然不一樣�����,你思考對了嗎?原因就是前述所說的�,如果分號后面有數(shù)字,所得到的切片���,不包含該數(shù)字所對應(yīng)的序號(前包括��,后不包括)�。那么�,是不是可以這樣呢?lang[1:12]����,不包括 12 號(事實沒有 12 號),是不是可以得到 1 到 11 號對應(yīng)的字符呢���?
>>> lang[1:12]
'tudy python'
>>> lang[1:13]
'tudy python'
果然是��。并且不僅僅后面寫 12,寫 13�����,也能得到同樣的結(jié)果。但是�,我這個特別要提醒,這種獲得切片的做法在編程實踐中是不提倡的���。特別是如果后面要用到循環(huán)的時候�,這樣做或許在什么時候遇到麻煩��。
如果在切片的時候����,冒號左右都不寫數(shù)字,就是前面所操作的 c = lang[:]���,其結(jié)果是變量 c 的值與原字符串一樣����,也就是“復(fù)制”了一份����。注意,這里的“復(fù)制”我打上了引號����,意思是如同復(fù)制�����,是不是真的復(fù)制呢�����?可以用下面的方式檢驗一下
>>> id(c)
3071934536L
>>> id(lang)
3071934536L
id()的作用就是查看該對象在內(nèi)存地址(就是在內(nèi)存中的位置編號)����。從上面可以看出��,兩個的內(nèi)存地址一樣�,說明 c 和 lang 兩個變量指向的是同一個對象。用 c=lang[:]的方式�,并沒有生成一個新的字符串,而是將變量 c 這個標(biāo)簽也貼在了原來那個字符串上了����。
>>> lang = "study python"
>>> c = lang
如果這樣操作,變量 c 和 lang 是不是指向同一個對象呢���?或者兩者所指向的對象內(nèi)存地址如何呢��?看官可以自行查看��。
字符串基本操作
字符串是一種序列��,所有序列都有如下基本操作:
len():求序列長度
:連接 2 個序列
: 重復(fù)序列元素
in :判斷元素是否存在于序列中
max() :返回最大值
min() :返回最小值
cmp(str1,str2) :比較 2 個序列值是否相同
通過下面的例子�����,將這幾個基本操作在字符串上的使用演示一下:
“+”連接字符串
>>> str1 + str2
'abcdabcde'
>>> str1 + "-->" + str2
'abcd-->abcde'
這其實就是拼接����,不過在這里�����,看官應(yīng)該有一個更大的觀念�,我們現(xiàn)在只是學(xué)了字符串這一種序列,后面還會遇到列表�����、元組兩種序列��,都能夠如此實現(xiàn)拼接��。
in
>>> "a" in str1
True
>>> "de" in str1
False
>>> "de" in str2
True
in 用來判斷某個字符串是不是在另外一個字符串內(nèi),或者說判斷某個字符串內(nèi)是否包含某個字符串�����,如果包含����,就返回 True,否則返回 False����。
最值
>>> max(str1)
'd'
>>> max(str2)
'e'
>>> min(str1)
'a'
一個字符串中,每個字符在計算機內(nèi)都是有編碼的���,也就是對應(yīng)著一個數(shù)字���,min()和 max()就是根據(jù)這個數(shù)字里獲得最小值和最大值,然后對應(yīng)出相應(yīng)的字符��。關(guān)于這種編號是多少��,看官可以 google 有關(guān)字符編碼�����,或者 ASCII 編碼什么的,很容易查到����。
比較
>>> cmp(str1, str2)
-1
將兩個字符串進行比較,也是首先將字符串中的符號轉(zhuǎn)化為對一個的數(shù)字�����,然后比較。如果返回的數(shù)值小于零�,說明第一個小于第二個���,等于 0,則兩個相等���,大于 0����,第一個大于第二個���。為了能夠明白其所以然,進入下面的分析���。
>>> ord('a')
97
>>> ord('b')
98
>>> ord(' ')
32
ord()是一個內(nèi)建函數(shù)���,能夠返回某個字符(注意���,是一個字符�,不是多個字符組成的串)所對一個的 ASCII 值(是十進制的)����,字符 a 在 ASCII 中的值是 97��,空格在 ASCII 中也有值�����,是 32����。順便說明,反過來�,根據(jù)整數(shù)值得到相應(yīng)字符��,可以使用 chr():
>>> chr(97)
'a'
>>> chr(98)
'b'
于是���,就得到如下比較結(jié)果了:
>>> cmp("a","b") #a-->97, b-->98, 97 小于 98���,所以 a 小于 b
-1
>>> cmp("abc","aaa")
1
>>> cmp("a","a")
0
看看下面的比較��,是怎么進行的呢�����?
>>> cmp("ad","c")
-1
在字符串的比較中,是兩個字符串的第一個字符先比較���,如果相等��,就比較下一個�����,如果不相等,就返回結(jié)果����。直到最后,如果還相等�����,就返回 0��。位數(shù)不夠時,按照沒有處理(注意��,沒有不是 0��,0 在 ASCII 中對應(yīng)的是 NUL),位數(shù)多的那個天然大了。ad 中的 a 先和后面的 c 進行比較�����,顯然 a 小于 c��,于是就返回結(jié)果 -1�。如果進行下面的比較,是最容易讓人迷茫的??垂倌懿荒芨鶕?jù)剛才闡述的比較遠離理解呢?
>>> cmp("123","23")
-1
>>> cmp(123,23) # 也可以比較整數(shù)�����,這時候就是整數(shù)的直接比較了。
1
“*”
字符串中的“乘法”,這個乘法�����,就是重復(fù)那個字符串的含義。在某些時候很好用的�����。比如我要打印一個華麗的分割線:
>>> str1*3
'abcdabcdabcd'
>>> print "-"*20 # 不用輸入很多個`-`
--------------------
len()
要知道一個字符串有多少個字符����,一種方法是從頭開始��,盯著屏幕數(shù)一數(shù)。哦���,這不是計算機在干活�,是鍵客在干活��。
鍵客����,不是劍客���。劍客是以劍為武器的俠客�����;而鍵客是以鍵盤為武器的俠客。當(dāng)然,還有賤客�����,那是賤人的最高境界,賤到大俠的程度�����,比如岳不群之流��。
鍵客這樣來數(shù)字符串長度:
>>> a="hello"
>>> len(a)
5
使用的是一個函數(shù) len(object)����。得到的結(jié)果就是該字符串長度。
>>> m = len(a) # 把結(jié)果返回后賦值給一個變量
>>> m
5
>>> type(m) # 這個返回值(變量)是一個整數(shù)型
<type 'int'>
字符串格式化輸出
什么是格式化�����?在維基百科中有專門的詞條�����,這么說的:
格式化是指對磁盤或磁盤中的分區(qū)(partition)進行初始化的一種操作�,這種操作通常會導(dǎo)致現(xiàn)有的磁盤或分區(qū)中所有的文件被清除。
不知道你是否知道這種“格式化”����。顯然���,此格式化非我們這里所說的,我們說的是字符串的格式化�����,或者說成“格式化字符串”����,都可以�����,表示的意思就是:
格式化字符串�,是 C��、C++ 等程序設(shè)計語言 printf 類函數(shù)中用于指定輸出參數(shù)的格式與相對位置的字符串參數(shù)。其中的轉(zhuǎn)換說明(conversion specification)用于把隨后對應(yīng)的 0 個或多個函數(shù)參數(shù)轉(zhuǎn)換為相應(yīng)的格式輸出;格式化字符串中轉(zhuǎn)換說明以外的其它字符原樣輸出����。
這也是來自維基百科的定義。在這個定義中�,是用 C 語言作為例子�,并且用了其輸出函數(shù)來說明。在 Python 中��,也有同樣的操作和類似的函數(shù) print,此前我們已經(jīng)了解一二了�����。
如果將那個定義說的通俗一些���,字符串格式化化���,就是要先制定一個模板,在這個模板中某個或者某幾個地方留出空位來���,然后在那些空位填上字符串���。那么,那些空位���,需要用一個符號來表示�����,這個符號通常被叫做占位符(僅僅是占據(jù)著那個位置,并不是輸出的內(nèi)容)���。
>>> "I like %s"
'I like %s'
在這個字符串中�����,有一個符號:%s,就是一個占位符�,這個占位符可以被其它的字符串代替。比如:
>>> "I like %s" % "python"
'I like python'
>>> "I like %s" % "Pascal"
'I like Pascal'
這是較為常用的一種字符串輸出方式�。
另外����,不同的占位符���,會表示那個位置應(yīng)該被不同類型的對象填充。下面列出許多,供參考�����。不過����,不用記憶���,常用的只有 %s 和 %d,或者再加上 %f��,其它的如果需要了,到這里來查即可���。
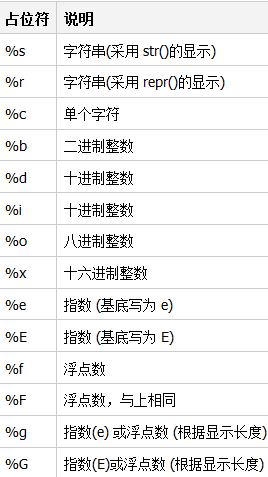
看例子:
>>> a = "%d years" % 15
>>> print a
15 years
當(dāng)然��,還可以在一個字符串中設(shè)置多個占位符,就像下面一樣
>>> print "Suzhou is more than %d years. %s lives in here." % (2500, "qiwsir")
Suzhou is more than 2500 years. qiwsir lives in here.
對于浮點數(shù)字的打印輸出,還可以限定輸出的小數(shù)位數(shù)和其它樣式。
>>> print "Today's temperature is %.2f" % 12.235
Today's temperature is 12.23
>>> print "Today's temperature is %+.2f" % 12.235
Today's temperature is +12.23
注意,上面的例子中,沒有實現(xiàn)四舍五入的操作。只是截取。
常用的字符串方法
字符串的方法很多�����?��?梢酝ㄟ^ dir 來查看:
>>> dir(str)
['__add__', '__class__', '__contains__', '__delattr__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__getnewargs__', '__getslice__', '__gt__', '__hash__', '__init__', '__le__', '__len__', '__lt__', '__mod__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__rmod__', '__rmul__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '_formatter_field_name_split', '_formatter_parser', 'capitalize', 'center', 'count', 'decode', 'encode', 'endswith', 'expandtabs', 'find', 'format', 'index', 'isalnum', 'isalpha', 'isdigit', 'islower', 'isspace', 'istitle', 'isupper', 'join', 'ljust', 'lower', 'lstrip', 'partition', 'replace', 'rfind', 'rindex', 'rjust', 'rpartition', 'rsplit', 'rstrip', 'split', 'splitlines', 'startswith', 'strip', 'swapcase', 'title', 'translate', 'upper', 'zfill']
這么多�,不會一一介紹���,要了解某個具體的含義和使用方法�,最好是使用 help 查看��。舉例:
>>> help(str.isalpha)
Help on method_descriptor:
isalpha(...)
S.isalpha() -> bool
Return True if all characters in S are alphabetic
and there is at least one character in S, False otherwise.
按照這里的說明,就可以在交互模式下進行實驗��。
>>> "python".isalpha() # 字符串全是字母�,應(yīng)該返回 True
True
>>> "2python".isalpha() # 字符串含非字母�,返回 False
False
split
這個函數(shù)的作用是將字符串根據(jù)某個分割符進行分割。
>>> a = "I LOVE PYTHON"
>>> a.split(" ")
['I', 'LOVE', 'PYTHON']
這是用空格作為分割���,得到了一個名字叫做列表(list)的返回值���,關(guān)于列表的內(nèi)容,后續(xù)會介紹�����。還能用別的分隔嗎?
>>> b = "www.itdiffer.com"
>>> b.split(".")
['www', 'itdiffer', 'com']
去掉字符串兩頭的空格
這個功能��,在讓用戶輸入一些信息的時候非常有用�����。有的朋友喜歡輸入結(jié)束的時候敲擊空格�����,比如讓他輸入自己的名字�����,輸完了,他來個空格。有的則喜歡先加一個空格�����,總做的輸入的第一個字前面應(yīng)該空兩個格。
這些空格是沒用的。Python 考慮到有不少人可能有這個習(xí)慣���,因此就幫助程序員把這些空格去掉����。
方法是:
S.strip() 去掉字符串的左右空格
S.lstrip() 去掉字符串的左邊空格
S.rstrip() 去掉字符串的右邊空格
例如:
>>> b=" hello " # 兩邊有空格
>>> b.strip()
'hello'
>>> b
' hello '
特別注意,原來的值沒有變化,而是新返回了一個結(jié)果。
>>> b.lstrip() # 去掉左邊的空格
'hello '
>>> b.rstrip() # 去掉右邊的空格
' hello'
字符大小寫的轉(zhuǎn)換
對于英文,有時候要用到大小寫轉(zhuǎn)換���。最有名駝峰命名����,里面就有一些大寫和小寫的參合�����。如果有興趣��,可以來這里看自動將字符串轉(zhuǎn)化為駝峰命名形式的方法��。
在 Python 中有下面一堆內(nèi)建函數(shù),用來實現(xiàn)各種類型的大小寫轉(zhuǎn)化
S.upper() #S 中的字母大寫
S.lower() #S 中的字母小寫
S.capitalize() # 首字母大寫
S.isupper() #S 中的字母是否全是大寫
S.islower() #S 中的字母是否全是小寫
S.istitle()
看例子:
>>> a = "qiwsir,Python"
>>> a.upper() # 將小寫字母完全變成大寫字母
'QIWSIR,PYTHON'
>>> a # 原數(shù)據(jù)對象并沒有改變
'qiwsir,Python'
>>> b = a.upper()
>>> b
'QIWSIR,PYTHON'
>>> c = b.lower() # 將所有的小寫字母變成大寫字母
>>> c
'qiwsir,Python'
>>> a
'qiwsir,Python'
>>> a.capitalize() # 把字符串的第一個字母變成大寫
'Qiwsir,Python'
>>> a # 原數(shù)據(jù)對象沒有改變
'qiwsir,Python'
>>> b = a.capitalize() # 新建立了一個
>>> b
'Qiwsir,Python'
>>> a = "qiwsir,github" # 這里的問題就是網(wǎng)友白羽毛指出的�,非常感謝他。
>>> a.istitle()
False
>>> a = "QIWSIR" # 當(dāng)全是大寫的時候�,返回 False
>>> a.istitle()
False
>>> a = "qIWSIR"
>>> a.istitle()
False
>>> a = "Qiwsir,github" # 如果這樣,也返回 False
>>> a.istitle()
False
>>> a = "Qiwsir" # 這樣是 True
>>> a.istitle()
True
>>> a = 'Qiwsir,Github' # 這樣也是 True
>>> a.istitle()
True
>>> a = "Qiwsir"
>>> a.isupper()
False
>>> a.upper().isupper()
True
>>> a.islower()
False
>>> a.lower().islower()
True
再探究一下��,可以這么做:
>>> a = "This is a Book"
>>> a.istitle()
False
>>> b = a.title() # 這樣就把所有單詞的第一個字母轉(zhuǎn)化為大寫
>>> b
'This Is A Book'
>>> b.istitle() # 判斷每個單詞的第一個字母是否為大寫
True
join 拼接字符串
用“+”能夠拼接字符串�,但不是什么情況下都能夠如愿的。比如�,將列表(關(guān)于列表,后續(xù)詳細說��,它是另外一種類型)中的每個字符(串)元素拼接成一個字符串���,并且用某個符號連接,如果用“+”��,就比較麻煩了(是能夠?qū)崿F(xiàn)的�����,麻煩)����。
用字符串的 join 就比較容易實現(xiàn)����。
>>> b
'www.itdiffer.com'
>>> c = b.split(".")
>>> c
['www', 'itdiffer', 'com']
>>> ".".join(c)
'www.itdiffer.com'
>>> "*".join(c)
'www*itdiffer*com'
這種拼接�,是不是簡單呢?
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認(rèn)證考試�����,點擊>>>
“CDA報名”
了解CDA考試詳情�����;
? 想學(xué)習(xí)CDA考試教材���,點擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫�,點擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量�����,點擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330