python對json的相關(guān)操作實例詳解
本文實例分析了python對json的相關(guān)操作��。分享給大家供大家參考����,具體如下:
什么是json:
JSON(JavaScript Object Notation) 是一種輕量級的數(shù)據(jù)交換格式�����。易于人閱讀和編寫��。同時也易于機器解析和生成����。它基于JavaScript Programming Language, Standard ECMA-262 3rd Edition - December 1999的一個子集��。JSON采用完全獨立于語言的文本格式���,但是也使用了類似于C語言家族的習(xí)慣(包括C, C++, C#, Java, JavaScript, Perl, Python等)�。這些特性使JSON成為理想的數(shù)據(jù)交換語言�。
JSON建構(gòu)于兩種結(jié)構(gòu):
“名稱/值”對的集合(A collection of name/value pairs)�����。不同的語言中����,它被理解為對象(object),紀(jì)錄(record),結(jié)構(gòu)(struct)��,字典(dictionary)��,哈希表(hash table)��,有鍵列表(keyed list)��,或者關(guān)聯(lián)數(shù)組 (associative array)�。
值的有序列表(An ordered list of values)。在大部分語言中����,它被理解為數(shù)組(array)。
這些都是常見的數(shù)據(jù)結(jié)構(gòu)���。事實上大部分現(xiàn)代計算機語言都以某種形式支持它們�����。這使得一種數(shù)據(jù)格式在同樣基于這些結(jié)構(gòu)的編程語言之間交換成為可能��。
對簡單數(shù)據(jù)類型的encoding 和 decoding:
使用簡單的json.dumps方法對簡單數(shù)據(jù)類型進(jìn)行編碼����,例如:
import json
obj = [[1,2,3],123,123.123,'abc',{'key1':(1,2,3),'key2':(4,5,6)}]
encodedjson = json.dumps(obj)
print repr(obj)
print encodedjson
輸出:
[[1, 2, 3], 123, 123.123, 'abc', {'key2': (4, 5, 6), 'key1': (1, 2, 3)}]
[[1, 2, 3], 123, 123.123, "abc", {"key2": [4, 5, 6], "key1": [1, 2, 3]}]
通過輸出的結(jié)果可以看出,簡單類型通過encode之后跟其原始的repr()輸出結(jié)果非常相似�,但是有些數(shù)據(jù)類型進(jìn)行了改變,例如上例中的元組則轉(zhuǎn)換為了列表���。在json的編碼過程中�����,會存在從python原始類型向json類型的轉(zhuǎn)化過程�����,具體的轉(zhuǎn)化對照如下:
json.dumps()方法返回了一個str對象encodedjson����,我們接下來在對encodedjson進(jìn)行decode���,得到原始數(shù)據(jù)��,需要使用的json.loads()函數(shù):
decodejson = json.loads(encodedjson)
print type(decodejson)
print decodejson[4]['key1']
print decodejson
輸出:
[1, 2, 3]
[[1, 2, 3], 123, 123.123, u'abc', {u'key2': [4, 5, 6], u'key1': [1, 2, 3]}]
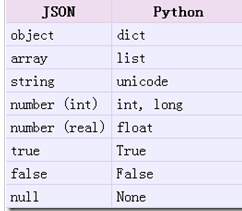
loads方法返回了原始的對象,但是仍然發(fā)生了一些數(shù)據(jù)類型的轉(zhuǎn)化���。比如����,上例中‘a(chǎn)bc'轉(zhuǎn)化為了unicode類型。從json到python的類型轉(zhuǎn)化對照如下:
json.dumps方法提供了很多好用的參數(shù)可供選擇�����,比較常用的有sort_keys(對dict對象進(jìn)行排序�,我們知道默認(rèn)dict是無序存放的),separators���,indent等參數(shù)��。
排序功能使得存儲的數(shù)據(jù)更加有利于觀察����,也使得對json輸出的對象進(jìn)行比較�����,例如:
data1 = {'b':789,'c':456,'a':123}
data2 = {'a':123,'b':789,'c':456}
d1 = json.dumps(data1,sort_keys=True)
d2 = json.dumps(data2)
d3 = json.dumps(data2,sort_keys=True)
print d1
print d2
print d3
print d1==d2
print d1==d3
輸出:
{"a": 123, "b": 789, "c": 456}
{"a": 123, "c": 456, "b": 789}
{"a": 123, "b": 789, "c": 456}
False
True
上例中�,本來data1和data2數(shù)據(jù)應(yīng)該是一樣的,但是由于dict存儲的無序特性��,造成兩者無法比較��。因此兩者可以通過排序后的結(jié)果進(jìn)行存儲就避免了數(shù)據(jù)比較不一致的情況發(fā)生,但是排序后再進(jìn)行存儲��,系統(tǒng)必定要多做一些事情�����,也一定會因此造成一定的性能消耗��,所以適當(dāng)排序是很重要的�����。
indent參數(shù)是縮進(jìn)的意思�����,它可以使得數(shù)據(jù)存儲的格式變得更加優(yōu)雅���。
data1 = {'b':789,'c':456,'a':123}
d1 = json.dumps(data1,sort_keys=True,indent=4)
print d1
輸出:
{
"a": 123,
"b": 789,
"c": 456
}
輸出的數(shù)據(jù)被格式化之后��,變得可讀性更強���,但是卻是通過增加一些冗余的空白格來進(jìn)行填充的。json主要是作為一種數(shù)據(jù)通信的格式存在的����,而網(wǎng)絡(luò)通信是很在乎數(shù)據(jù)的大小的,無用的空格會占據(jù)很多通信帶寬�,所以適當(dāng)時候也要對數(shù)據(jù)進(jìn)行壓縮。separator參數(shù)可以起到這樣的作用�����,該參數(shù)傳遞是一個元組����,包含分割對象的字符串。
print 'DATA:', repr(data)
print 'repr(data) :', len(repr(data))
print 'dumps(data) :', len(json.dumps(data))
print 'dumps(data, indent=2) :', len(json.dumps(data, indent=4))
print 'dumps(data, separators):', len(json.dumps(data, separators=(',',':')))
輸出:
DATA: {'a': 123, 'c': 456, 'b': 789}
repr(data) : 30
dumps(data) : 30
dumps(data, indent=2) : 46
dumps(data, separators): 25
通過移除多余的空白符�,達(dá)到了壓縮數(shù)據(jù)的目的,而且效果還是比較明顯的��。
另一個比較有用的dumps參數(shù)是skipkeys��,默認(rèn)為False�。 dumps方法存儲dict對象時,key必須是str類型�����,如果出現(xiàn)了其他類型的話��,那么會產(chǎn)生TypeError異常,如果開啟該參數(shù)�,設(shè)為True的話,則會比較優(yōu)雅的過度����。
data = {'b':789,'c':456,(1,2):123}
print json.dumps(data,skipkeys=True)
輸出:
{"c": 456, "b": 789}
處理自己的數(shù)據(jù)類型
json模塊不僅可以處理普通的python內(nèi)置類型,也可以處理我們自定義的數(shù)據(jù)類型�,而往往處理自定義的對象是很常用的。
首先��,我們定義一個類Person�����。
class Person(object):
def __init__(self,name,age):
self.name = name
self.age = age
def __repr__(self):
return 'Person Object name : %s , age : %d' % (self.name,self.age)
if __name__ == '__main__':
p = Person('Peter',22)
print p
如果直接通過json.dumps方法對Person的實例進(jìn)行處理的話���,會報錯�����,因為json無法支持這樣的自動轉(zhuǎn)化���。通過上面所提到的json和python的類型轉(zhuǎn)化對照表,可以發(fā)現(xiàn)�,object類型是和dict相關(guān)聯(lián)的�,所以我們需要把我們自定義的類型轉(zhuǎn)化為dict���,然后再進(jìn)行處理��。這里����,有兩種方法可以使用��。
方法一:自己寫轉(zhuǎn)化函數(shù)
'''
Created on 2011-12-14
@author: Peter
'''
import Person
import json
p = Person.Person('Peter',22)
def object2dict(obj):
#convert object to a dict
d = {}
d['__class__'] = obj.__class__.__name__
d['__module__'] = obj.__module__
d.update(obj.__dict__)
return d
def dict2object(d):
#convert dict to object
if'__class__' in d:
class_name = d.pop('__class__')
module_name = d.pop('__module__')
module = __import__(module_name)
class_ = getattr(module,class_name)
args = dict((key.encode('ascii'), value) for key, value in d.items()) #get args
inst = class_(**args) #create new instance
else:
inst = d
return inst
d = object2dict(p)
print d
#{'age': 22, '__module__': 'Person', '__class__': 'Person', 'name': 'Peter'}
o = dict2object(d)
print type(o),o
# Person Object name : Peter , age : 22
dump = json.dumps(p,default=object2dict)
print dump
#{"age": 22, "__module__": "Person", "__class__": "Person", "name": "Peter"}
load = json.loads(dump,object_hook = dict2object)
print load
#Person Object name : Peter , age : 22
上面代碼已經(jīng)寫的很清楚了�,實質(zhì)就是自定義object類型和dict類型進(jìn)行轉(zhuǎn)化。object2dict函數(shù)將對象模塊名��、類名以及__dict__存儲在dict對象里���,并返回�����。dict2object函數(shù)則是反解出模塊名�����、類名�����、參數(shù)����,創(chuàng)建新的對象并返回。在json.dumps 方法中增加default參數(shù)�����,該參數(shù)表示在轉(zhuǎn)化過程中調(diào)用指定的函數(shù)��,同樣在decode過程中json.loads方法增加object_hook,指定轉(zhuǎn)化函數(shù)�����。
方法二:繼承JSONEncoder和JSONDecoder類�,覆寫相關(guān)方法
JSONEncoder類負(fù)責(zé)編碼,主要是通過其default函數(shù)進(jìn)行轉(zhuǎn)化��,我們可以override該方法���。同理對于JSONDecoder��。
'''
Created on 2011-12-14
@author: Peter
'''
import Person
import json
p = Person.Person('Peter',22)
class MyEncoder(json.JSONEncoder):
def default(self,obj):
#convert object to a dict
d = {}
d['__class__'] = obj.__class__.__name__
d['__module__'] = obj.__module__
d.update(obj.__dict__)
return d
class MyDecoder(json.JSONDecoder):
def __init__(self):
json.JSONDecoder.__init__(self,object_hook=self.dict2object)
def dict2object(self,d):
#convert dict to object
if'__class__' in d:
class_name = d.pop('__class__')
module_name = d.pop('__module__')
module = __import__(module_name)
class_ = getattr(module,class_name)
args = dict((key.encode('ascii'), value) for key, value in d.items()) #get args
inst = class_(**args) #create new instance
else:
inst = d
return inst
d = MyEncoder().encode(p)
o = MyDecoder().decode(d)
print d
print type(o), o
對于JSONDecoder類方法�,稍微有點不同,但是改寫起來也不是很麻煩���?����?创a應(yīng)該就比較清楚了。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認(rèn)證考試���,點擊>>>
“CDA報名”
了解CDA考試詳情��;
? 想學(xué)習(xí)CDA考試教材���,點擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫�,點擊>>> “CDA題庫” 了解CDA考試詳情;
? 想了解CDA考試含金量�,點擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330