學(xué)會(huì)數(shù)據(jù)分析背后的挖掘思維�����,分析就完成了一半
在數(shù)據(jù)分析中,模型是非常有用和有效的工具和數(shù)據(jù)分析應(yīng)用的場(chǎng)景,在建立模型的過程中,數(shù)據(jù)挖掘很多時(shí)候能夠起到非常顯著的作用���。伴隨著計(jì)算機(jī)科學(xué)的發(fā)展,模型也越來越向智能化和自動(dòng)化發(fā)展。對(duì)數(shù)據(jù)分析而言,了解數(shù)據(jù)挖掘背后的思想,可以有助于建立更具穩(wěn)定性的模型和更高效的模型�����。
數(shù)據(jù)挖掘前世今生
數(shù)據(jù)模型很多時(shí)候就是一個(gè)類似Y=f(X)的函數(shù),這個(gè)函數(shù)貫穿了模型從構(gòu)思到建立,從調(diào)試再到最后落地應(yīng)用的全部過程。

Y=f(X)建立之路
對(duì)模型而言,其中的規(guī)則和參數(shù),最初是通過經(jīng)驗(yàn)判斷人為給出的�����。伴隨著統(tǒng)計(jì)方法和技術(shù)的發(fā)展,在模型的建立過程中,也引入了統(tǒng)計(jì)分析的過程��。更進(jìn)一步地,隨著計(jì)算機(jī)科學(xué)的發(fā)展,建模的過程,也被交給了機(jī)器來完成,因此數(shù)據(jù)挖掘也被用到了模型的建立中��。
數(shù)據(jù)挖掘,是從大量數(shù)據(jù)中,挖掘出有價(jià)值信息的過程���。在有的地方,數(shù)據(jù)挖掘也被成為是數(shù)據(jù)探礦,正如數(shù)據(jù)挖掘的英文data
mining一樣,從數(shù)據(jù)中挖掘有價(jià)值的知識(shí),正如在礦山中采集鉆石一般,不斷去蕪存精,不斷發(fā)掘數(shù)據(jù)新的價(jià)值���。數(shù)據(jù)挖掘是通過對(duì)數(shù)據(jù)不斷的學(xué)習(xí),從中發(fā)掘規(guī)律和信息的過程,因此也被稱為統(tǒng)計(jì)學(xué)習(xí)或者是機(jī)器學(xué)習(xí)。對(duì)數(shù)據(jù)挖掘而言,其應(yīng)用范圍廣泛,除了建模,在人工智能領(lǐng)域也有使用��。
回到模型中,從經(jīng)驗(yàn)判斷到數(shù)據(jù)挖掘,建立模型的計(jì)算特征發(fā)生了極大的改變����。
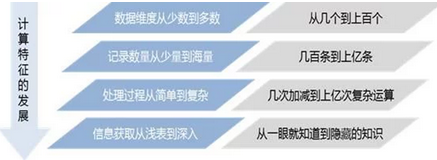
計(jì)算特征的發(fā)展
首先數(shù)據(jù)的維度開始從少變多,最初只有幾個(gè)維度,到現(xiàn)在有上百個(gè)維度。數(shù)據(jù)的體量,即記錄的條數(shù)也從少量到海量,從過去了百條規(guī)模到了現(xiàn)在億條規(guī)模�。伴隨著數(shù)據(jù)獲取的難度下降,數(shù)據(jù)的維度和記錄數(shù)量會(huì)越來越多。在這種情況下,數(shù)據(jù)的處理過程也越來越復(fù)雜,從過去簡(jiǎn)單的幾次加減計(jì)算得到結(jié)果,到了現(xiàn)在必須要經(jīng)歷上億次的復(fù)雜運(yùn)算�����。同時(shí),伴隨著計(jì)算性能的提升,對(duì)于從數(shù)據(jù)中提取信息而言,也從漸漸深入,過去只能發(fā)現(xiàn)一眼看出的淺表信息,如今可以不斷去挖掘隱含的知識(shí)。
數(shù)據(jù)挖掘的基本思想
數(shù)據(jù)挖掘的別名機(jī)器學(xué)習(xí)和統(tǒng)計(jì)學(xué)習(xí)一樣,數(shù)據(jù)挖掘的實(shí)質(zhì)是通過計(jì)算機(jī)的計(jì)算能力在一堆數(shù)據(jù)中發(fā)掘出規(guī)律并加以利用的過程����。因此對(duì)數(shù)據(jù)挖掘而言,就需要經(jīng)歷規(guī)則學(xué)習(xí)��、規(guī)則驗(yàn)證和規(guī)則使用的過程�。
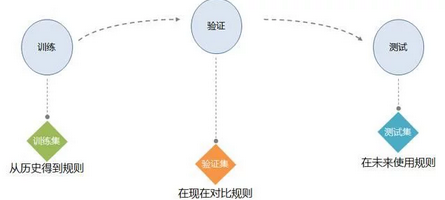
數(shù)據(jù)挖掘的基本思想
規(guī)則學(xué)習(xí)又稱為模型訓(xùn)練,在這個(gè)步驟中,有一個(gè)數(shù)據(jù)集將作為訓(xùn)練集。按照相關(guān)的算法和輸出規(guī)則的要求,從訓(xùn)練集中篩選出需要使用的變量,并根據(jù)這些變量生成相關(guān)的規(guī)則�����。有的時(shí)候,是將過去已經(jīng)發(fā)生的數(shù)據(jù)作為訓(xùn)練集,在對(duì)比已知的結(jié)果和輸入的變量的過程中,以盡可能降低輸出誤差的原則,擬合出相應(yīng)的模型�。
當(dāng)產(chǎn)生了規(guī)則后,就需要驗(yàn)證規(guī)則的效果和準(zhǔn)確度,這個(gè)時(shí)候就需要引入驗(yàn)證集。驗(yàn)證集和訓(xùn)練集具有相同的格式,既包含了已知的結(jié)果也包含了輸入的變量����。與訓(xùn)練集不同的是,對(duì)驗(yàn)證集的應(yīng)用是直接將規(guī)則應(yīng)用于驗(yàn)證集中,去產(chǎn)生出相應(yīng)的輸出結(jié)果,并用輸出的結(jié)果去對(duì)比實(shí)際情況,以來確定模型是否有效。如果有效的話,就可以在實(shí)際的場(chǎng)景中應(yīng)用����。如果效果不理想,則回頭去調(diào)整模型
測(cè)試集是將模型在實(shí)際的場(chǎng)景中使用,是直接應(yīng)用模型的步驟。在測(cè)試集中,只包含輸入變量卻沒有像其他兩個(gè)數(shù)據(jù)一樣存在的已知結(jié)果��。正因?yàn)榻Y(jié)果未知,就需要用測(cè)試集通過模型去產(chǎn)生的輸出的結(jié)果�����。這個(gè)輸出結(jié)果,將在為結(jié)果產(chǎn)生以后進(jìn)行驗(yàn)證,只要有效,模型就會(huì)一直使用下去。
數(shù)據(jù)挖掘的流程
數(shù)據(jù)挖掘與數(shù)據(jù)分析的流程相似,都是從數(shù)據(jù)中發(fā)現(xiàn)知識(shí)的過程,只不過由于數(shù)據(jù)體量和維度的原因,數(shù)據(jù)挖掘在計(jì)算上最大���。
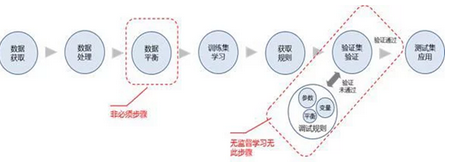
數(shù)據(jù)挖掘的流程
對(duì)數(shù)據(jù)挖掘而言,首先是進(jìn)行數(shù)據(jù)獲取,數(shù)據(jù)獲取的來源很多,有系統(tǒng)中自行記錄的數(shù)據(jù),對(duì)這種數(shù)據(jù)只要導(dǎo)出即可,同時(shí)也有外來數(shù)據(jù),比如網(wǎng)頁(yè)爬取得數(shù)據(jù),或者是購(gòu)買的數(shù)據(jù),這些數(shù)據(jù)需要按照分析系統(tǒng)的需求進(jìn)行導(dǎo)入���。
在完成了數(shù)據(jù)獲取步驟后,就需要進(jìn)行數(shù)據(jù)處理,數(shù)據(jù)處理即是處理數(shù)據(jù)中的缺失值,錯(cuò)誤值以及異常值,按照相關(guān)的規(guī)則進(jìn)行修正或者刪除,同時(shí)在數(shù)據(jù)處理中也需要根據(jù)變臉之間的關(guān)系,產(chǎn)生出一系列的衍生變量?����?偠灾?數(shù)據(jù)處理的結(jié)果是可以進(jìn)行分析的數(shù)據(jù),所有數(shù)據(jù)在進(jìn)行分析以前都需要完成數(shù)據(jù)處理的步驟�。
如果數(shù)據(jù)在分布上存在較極端的情況,就需要經(jīng)歷數(shù)據(jù)平衡的不走。例如對(duì)于要輸出的原始變量而言,存在及其少量的一種類別以及及其大量的另一種類別,就像有大量的0和少量的1一樣,在這種情況下,就需要對(duì)數(shù)據(jù)進(jìn)行平衡,通過復(fù)制1或者削減0的形式生成平衡數(shù)據(jù)集�。
當(dāng)完成數(shù)據(jù)平衡后,將會(huì)把數(shù)據(jù)處理的結(jié)果分出一部分作為驗(yàn)證集使用,如果數(shù)據(jù)平衡性好,那么剩下的部分作為訓(xùn)練集,如果平衡性不好,那么平衡數(shù)據(jù)集就會(huì)作為訓(xùn)練集使用。當(dāng)有了訓(xùn)練集后,就按照相關(guān)的算法對(duì)訓(xùn)練集進(jìn)行學(xué)習(xí),從而產(chǎn)生出相關(guān)的規(guī)則和參數(shù)���。當(dāng)有了規(guī)則以后,就將產(chǎn)生的規(guī)則用在驗(yàn)證集中,通過對(duì)比已知結(jié)果和輸出結(jié)果之間的誤差情況,來判斷是否通過���。如果通過則在后面再測(cè)試集中使用,如果未通過,就通過數(shù)據(jù)平衡、參數(shù)調(diào)整,以及變量選擇等手段重新調(diào)整規(guī)則,并再次進(jìn)行驗(yàn)證,直到通過驗(yàn)證���。
對(duì)于驗(yàn)證集驗(yàn)證的步驟而言,在無監(jiān)督學(xué)習(xí)中沒有這個(gè)步驟,當(dāng)纏上規(guī)則后,就直接用于測(cè)試集����。

數(shù)據(jù)挖掘周而復(fù)始
數(shù)據(jù)挖掘是一個(gè)周而復(fù)始的過程,在生成規(guī)則的過程中,不斷地對(duì)模型進(jìn)行調(diào)整,從而提升精度。同時(shí)也將多批次的歷史數(shù)據(jù)引入到數(shù)據(jù)挖掘的過程中,進(jìn)行多次的驗(yàn)證,從而在時(shí)間上保證模型的穩(wěn)定性�。
數(shù)據(jù)挖掘的模式
在數(shù)據(jù)挖掘中,對(duì)于規(guī)則的獲取,存在三種方式,分別是監(jiān)督學(xué)習(xí),無監(jiān)督學(xué)習(xí)和半監(jiān)督學(xué)習(xí),這三種方式都是通過從數(shù)據(jù)的統(tǒng)計(jì)學(xué)習(xí)來制定規(guī)則。
在一個(gè)數(shù)據(jù)挖掘問題中,變量可以分為自變量和因變量,規(guī)則是以自變量為輸入,以因變量為輸出的結(jié)果,由此對(duì)數(shù)據(jù)挖掘問題,就把自變量定義為X,把因變量定義為Y�。
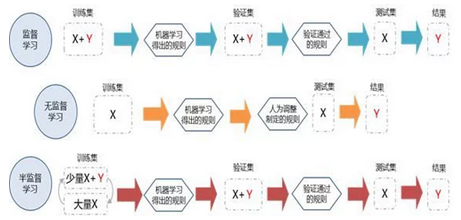
獲取規(guī)則的方式,來源于對(duì)數(shù)據(jù)的統(tǒng)計(jì)學(xué)習(xí)
對(duì)于監(jiān)督學(xué)習(xí)而言,訓(xùn)練集中包括了自變量X和因變量Y,通過對(duì)比X和Y的關(guān)系,得除相應(yīng)的規(guī)則,同時(shí)再在驗(yàn)證集中,通過輸入驗(yàn)證集的自變量X,借助規(guī)則得到因變量Y的預(yù)測(cè)值,再將Y的預(yù)測(cè)值與實(shí)際值進(jìn)行對(duì)比,看是否可以將模型驗(yàn)證通過,如果通過了,就把只包含自變量X的測(cè)試集用于規(guī)則中,最終輸出因變量Y的預(yù)測(cè)值。在監(jiān)督學(xué)習(xí)中,因變量的實(shí)際值和預(yù)測(cè)值的對(duì)比,就起到監(jiān)督的作用,在規(guī)則制定中需要盡量引導(dǎo)規(guī)則輸出的結(jié)果向?qū)嶋H值靠攏��。
對(duì)無監(jiān)督學(xué)習(xí)而言,訓(xùn)練集中,就沒有包含因變量Y,需要根據(jù)模型的目標(biāo),通過對(duì)自變量X的分析和對(duì)比來得出相關(guān)的規(guī)則,并能夠產(chǎn)生合理的輸出結(jié)果,即Y,在制定規(guī)則的過程中,需要有一些人為的原則對(duì)規(guī)則進(jìn)行調(diào)整��。當(dāng)完成調(diào)整后,就可以把只包含自變量X的測(cè)試集放到規(guī)則中,去產(chǎn)生規(guī)則的結(jié)果Y�����。
對(duì)比監(jiān)督學(xué)習(xí)和無監(jiān)督學(xué)習(xí),最大的區(qū)別就是,在制定規(guī)則的過程中,是否有Y用于引導(dǎo)規(guī)則的生成���。監(jiān)督學(xué)習(xí)中,有Y存在,生成規(guī)則過程中和生成規(guī)則時(shí),也會(huì)對(duì)比Y的預(yù)測(cè)值和實(shí)際值。而在無監(jiān)督學(xué)習(xí)中,就沒有Y作為對(duì)比的標(biāo)準(zhǔn),相應(yīng)的規(guī)則都直接由X產(chǎn)生���。
半監(jiān)督學(xué)習(xí),與監(jiān)督學(xué)習(xí)類似,也需要因變量Y參與到規(guī)則生成和規(guī)則驗(yàn)證中去���。但是在訓(xùn)練集只用只有一少部分的對(duì)象既有自變量X和因變量Y,還有大部分對(duì)象只包含了自變量X。因此在對(duì)半監(jiān)督學(xué)習(xí)的規(guī)則生成中,需要有一些特殊的手段來處理只包含的自變量X的對(duì)象后,再生成相關(guān)的規(guī)則。在后面的驗(yàn)證和測(cè)試的流程都與監(jiān)督學(xué)習(xí)一致�����。因而對(duì)于半監(jiān)督學(xué)習(xí),最重要的問題就是如何借助少量的因變量Y而產(chǎn)生出可以適用的規(guī)則����。
數(shù)據(jù)挖掘的應(yīng)用場(chǎng)景
數(shù)據(jù)挖掘應(yīng)用的場(chǎng)景很多,通常有四種情況被廣泛的使用。
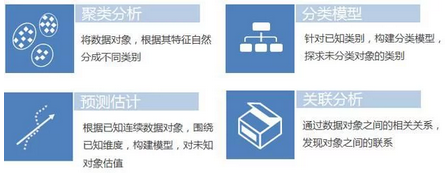
數(shù)據(jù)挖掘的應(yīng)用場(chǎng)景
首先是聚類分析,就是將不同的對(duì)象,根據(jù)其變量特征的分布自然地分成不同的類別�。此外是分類模型,這是針對(duì)已知的類別,構(gòu)建出分類的模型,通過分類的模型來探求其他未分類對(duì)象的類別。第三是預(yù)測(cè)估計(jì)�,集根據(jù)對(duì)象的連續(xù)數(shù)據(jù)因變量,通過圍繞已知的維度��,構(gòu)建出預(yù)測(cè)因變量的模型�,從而對(duì)因變量未知的對(duì)象進(jìn)行估計(jì)。最后是關(guān)聯(lián)分析����,即通過探求數(shù)據(jù)對(duì)象之間的相關(guān)關(guān)系,來發(fā)現(xiàn)對(duì)象之間的聯(lián)系�,在關(guān)聯(lián)分析中,更多是以對(duì)象之間的關(guān)系作為輸出�。
聚類分析
聚類分析是一種無監(jiān)督學(xué)習(xí)的數(shù)據(jù)挖掘方法,其目的是基于對(duì)象之間的特征����,自然地將變量劃分為不同的類別��。在聚類分析中��,基本的思想就是根據(jù)對(duì)象不同特征變量����,計(jì)算變量之間的距離����,距離理得越近,就越有可能被劃為一類���,離得越遠(yuǎn),就越有可能被劃分到不同的類別中去��。

會(huì)數(shù)據(jù)分析背后的挖掘思維,分析就完成了一半!")
聚類分析基本思想
例如在坐標(biāo)系中��,B距離A的距離遠(yuǎn)遠(yuǎn)小于��,B到C的距離�����,因此,AB更容易劃分為一類�,而BC更容易為不同的類別。通常來說��,一個(gè)對(duì)象距離同類的距離是最近的���,都小于其他類別中對(duì)象的距離�����。
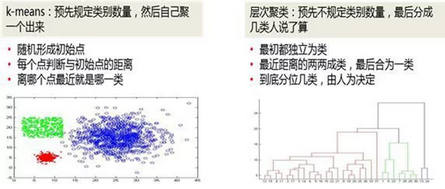
在聚類分析中�,有兩種常用的方法���,一種是K-means聚類�,一種是層次聚類���。
會(huì)數(shù)據(jù)分析背后的挖掘思維,分析就完成了一半!")
K-means聚類VS層次聚類
在K-means聚類中��,是預(yù)先規(guī)定出要產(chǎn)生多少個(gè)類別的數(shù)量,再根據(jù)類別數(shù)量自動(dòng)聚成相應(yīng)的類���。對(duì)K-means而言��,首先是隨機(jī)產(chǎn)生于類別數(shù)相同的初始點(diǎn)��,然后判斷每個(gè)點(diǎn)與初始點(diǎn)的距離��,每個(gè)點(diǎn)選擇最近的一個(gè)初始點(diǎn)����,作為其類別�����。當(dāng)類別產(chǎn)生后����,在計(jì)算各個(gè)類別的中心點(diǎn)����,然后計(jì)算每個(gè)點(diǎn)到中心點(diǎn)的距離,并根據(jù)距離再次選擇類別����。當(dāng)新類別產(chǎn)生后��,再次根據(jù)中心點(diǎn)重復(fù)選擇類別的過程����,直到中心點(diǎn)的變化不再明顯���。最終根據(jù)中心點(diǎn)產(chǎn)生的類別����,就是聚類的結(jié)果���。正如圖中所示���,一組對(duì)象中需要生成三個(gè)類別,各個(gè)類別之間都自然聚焦在一起����。
在層次聚類中,不需要規(guī)定出類別的數(shù)量�����,最終聚類的數(shù)量可以根據(jù)人為要求進(jìn)行劃分。對(duì)層次聚類���,首先每個(gè)對(duì)象都是單獨(dú)的類別��,通過比較兩兩之間距離�����,首先把距離最小的兩個(gè)對(duì)象聚成一類�����。接著把距離次小的聚成一類��,然后就是不斷重復(fù)按距離最小的原則�����,不斷聚成一類的過程�,直到所有對(duì)象都被聚成一類���。在層次聚類中,可以以一張樹狀圖來表示聚類的過程��,如果要講對(duì)象分類的話,就可以從根節(jié)點(diǎn)觸發(fā)��,按照樹狀圖的分叉情況���,劃分出不同的類別來��。在圖中���,把一組對(duì)象分成了三個(gè)類別,可見這三個(gè)類別就是構(gòu)成了樹狀圖最開始的三個(gè)分支��。
聚類分析的過程���,和分桔子其實(shí)很很像�,人們通常都把特征相同的桔子分成一類�,聚類分析中,也是同樣的方式���。
會(huì)數(shù)據(jù)分析背后的挖掘思維��,分析就完成了一半!")
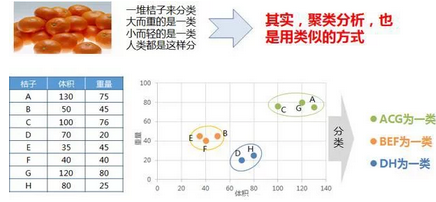
聚類分析案例
正如在這個(gè)例子中��,有A-H的8個(gè)桔子��,對(duì)每個(gè)桔子而言有提體積和變量?jī)蓚€(gè)變量���。通過將各個(gè)桔子投射到重量和體積構(gòu)成的坐標(biāo)系中�����,可以發(fā)現(xiàn)BEF距離很近�����,ACG距離很近���,而DH距離很近。如果聚成3類的話�����,可以是ACG��、BEF����,DH各為一類。如果是聚成兩類����,BEFDH與ACG相對(duì)更近,因此可以是ACG為一類�����,而BEFDH為另外一類
分類模型
分類模型通常是通過監(jiān)督學(xué)習(xí)產(chǎn)生的����,根據(jù)已知的對(duì)象的類別和其具體特征特征的數(shù)據(jù),通過訓(xùn)練從而產(chǎn)生由特征判斷類別的規(guī)則�。在分類模型中,規(guī)則的輸出就是具體的類別�����。

會(huì)數(shù)據(jù)分析背后的挖掘思維�,分析就完成了一半!")
分類模型基本思想
分類模型的規(guī)則產(chǎn)生的過程中,類別判別的原則與訓(xùn)練集中各特征變量的分布息息相關(guān),通常就是在對(duì)比各個(gè)類別下特征變量的互相關(guān)系��,而劃分出相關(guān)的規(guī)則����,這個(gè)過程遵循的原則就是盡可能讓輸出的類別與實(shí)際的類別保持一致。
當(dāng)前���,不管在學(xué)術(shù)研究領(lǐng)域還是業(yè)務(wù)應(yīng)用領(lǐng)域都有大量的分類模型����,通常來說��,決策樹和樸素貝葉斯是非常普遍的分類模型算法�,這兩個(gè)算法在一些文獻(xiàn)中也被列為十大數(shù)據(jù)挖掘算法。

會(huì)數(shù)據(jù)分析背后的挖掘思維,分析就完成了一半!")
決策樹VS樸素貝葉斯
決策樹的規(guī)則生成算法是將對(duì)象按照相關(guān)的特診變量進(jìn)行依次拆分��,在拆分中不斷迭代條件����,最終劃分為最終的類別。決策樹的劃分過程��,就像是一個(gè)樹一樣,從根節(jié)點(diǎn)觸發(fā)�����,依次開支散葉�,最終形成分類準(zhǔn)則����。
在圖中�����,首先就按照年齡進(jìn)行分支�����,直接將所有對(duì)象分成了三堆�����,其中年齡在31-40歲的被劃定為購(gòu)買類�����,另外的兩堆對(duì)象,還需要繼續(xù)進(jìn)行分支�。對(duì)年齡小于30歲�,按照是否為學(xué)生進(jìn)行分支�,其中是學(xué)生的被判定為購(gòu)買類����,不是學(xué)生的被判定為不買類���。同樣對(duì)年齡大于40歲����,按照信用等級(jí)進(jìn)行分類,信用等級(jí)高的被判定為不買類,信息等級(jí)低的被判定為購(gòu)買類�。就這樣,任何一個(gè)對(duì)象��,都可以根據(jù)條件達(dá)成的情況�,最終到達(dá)購(gòu)買或者不買的節(jié)點(diǎn)�,完成分類過程。
樸素貝葉斯的規(guī)則生成算法相對(duì)決策樹而言�����,就沒有這么直觀了��,其依賴于概率中的貝葉斯公式。由公式P(AB)=P(A/B)×P(B)=P(B/A)×P(A)得來的后驗(yàn)概率公式P(A/B)=P(B/A)×P(A)/P(B)�����,其中A類別�����,B表示條件即特征變量�。P(A/B)表示在特定條件下該類別的概率,P(B/A)表示在特定類別下該條件的分布概率�����,P(A)表示已知的特定分類的概率����,而P(B)表示已知的特定條件的概率。
在算法中�����,P(B/A)、P(A)��、P(B)都通過訓(xùn)練集能夠得到,再加上在條件一定時(shí),P(B)是恒定的,同時(shí)每個(gè)條件互相獨(dú)立����,根據(jù)概率公式����,P(類別/總條件)是P(類別)和所有P(條件/類別)的乘積�。因此在樸素貝葉斯中,最大的P(類別/總條件)對(duì)應(yīng)的類別����,就是被劃分的類別。
最近這幾年���,網(wǎng)上總有要遠(yuǎn)離女司機(jī)的段子,在網(wǎng)友心中女司機(jī)簡(jiǎn)直如洪水猛獸一般�����,這種說法一方面來自于個(gè)別事例的傳播,另外一方面也來自于女司機(jī)在低速駕駛時(shí)對(duì)他人的困擾造成的誤解。其實(shí)��,對(duì)于女司機(jī)是不是應(yīng)該害怕的問題,就可以用分類模型的解決�����。

會(huì)數(shù)據(jù)分析背后的挖掘思維��,分析就完成了一半!")
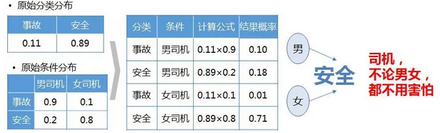
用分類模型解決女司機(jī)問題
已知道路上的車輛中的分布如下����,會(huì)發(fā)生的事故的概率有0.11���,而是安全的概率有0.89,車輛的分布就是對(duì)事件的原始分類分布���。同時(shí)��,對(duì)發(fā)生條件的分布如下����,發(fā)生事故時(shí)���,男司機(jī)概率為0.9����,女司機(jī)概率為0.1��,在安全情況下時(shí)����,男司機(jī)概率為0.2����,女司機(jī)概率為0.8。
會(huì)數(shù)據(jù)分析背后的挖掘思維�,分析就完成了一半!")
分類模型案例計(jì)算流程
那么根據(jù)貝葉斯公式�����,可以知道,當(dāng)遇到男司機(jī)時(shí)�����,發(fā)生事故的概率為0.1���,而女司機(jī)是0.01,兩者的事故的概率都很低�。對(duì)男女司機(jī)而言��,其發(fā)生事故的概率都低于安全的概率��,因此在職考慮性別的情況下�,所有司機(jī)都是被分為安全類別,尤其是女司機(jī)����,安全的概率遠(yuǎn)遠(yuǎn)大于事故。因此不能簡(jiǎn)單的通過司機(jī)的性別����,就做出是否危險(xiǎn)的判別�,尤其是遇到女司機(jī)�。
關(guān)聯(lián)分析
關(guān)聯(lián)分析模型常用于揭示事件之間的關(guān)系,是通過無監(jiān)督學(xué)習(xí)的方式�,產(chǎn)生的輸出事件之間發(fā)生關(guān)系的規(guī)則。關(guān)聯(lián)分析最開始在零售領(lǐng)域常常用到��,比如可以提供買了方便面時(shí)很多情況都會(huì)買火腿腸的關(guān)系�,因此在某些情況下,關(guān)聯(lián)分析又被稱為購(gòu)物籃分析�。

會(huì)數(shù)據(jù)分析背后的挖掘思維��,分析就完成了一半!")
關(guān)聯(lián)分析基本思想
在購(gòu)物籃分析中�,其核心思想就是對(duì)比單個(gè)事件發(fā)生的概率,和多個(gè)事件同時(shí)發(fā)生的概率的情況����,如果同時(shí)發(fā)生的概率與單獨(dú)發(fā)生的概率相近,則可以考慮發(fā)生了一個(gè)事件后��,很有可能會(huì)存在同時(shí)發(fā)生另外一個(gè)事件的情況�。
有事件X和事件Y,以及XY同時(shí)發(fā)生的概率��,在購(gòu)物籃分析中��,支持度是XY同時(shí)發(fā)生的概率,置信度是當(dāng)X發(fā)生了���,Y也發(fā)生的條件概率�。

關(guān)聯(lián)分析算法
如果在規(guī)則中�����,兩個(gè)事件的支持度和置信度都達(dá)到了制定的閾值�����,則可以認(rèn)為這兩個(gè)事件具有強(qiáng)關(guān)聯(lián)的關(guān)系�����。關(guān)聯(lián)分析正是體現(xiàn)了這種強(qiáng)關(guān)系�。在強(qiáng)關(guān)系中����,還有提升度來確認(rèn)這種強(qiáng)關(guān)系的力度,提升度是指�,當(dāng)X出現(xiàn)同時(shí)出現(xiàn)Y的概率���,與Y總體出現(xiàn)的概率之比,即X對(duì)Y的置信度與Y發(fā)生概率的比值���,通常來說提升度都是大于1的�����,提升度越大�����,說明強(qiáng)關(guān)系力度越大����。
在關(guān)聯(lián)分析中�����,強(qiáng)關(guān)系存在兩種情況���,這種情況具有不同的時(shí)間上的考慮���,第一種是序列關(guān)系,即事情順次發(fā)生,比如購(gòu)買了A了以后又繼續(xù)購(gòu)買B�����,另外一種是同時(shí)關(guān)聯(lián)��,即事件同時(shí)發(fā)生��,比如買了A的同時(shí)也買了B��。
啤酒和尿布是關(guān)聯(lián)分析中的經(jīng)典案例�����,盡管最近出現(xiàn)了這個(gè)只是編造的案例而已�,然而去仍然能體現(xiàn)出關(guān)聯(lián)分析的價(jià)值出來�����。

在啤酒和尿布中發(fā)現(xiàn)關(guān)聯(lián)分析的價(jià)值
啤酒和尿布���,兩個(gè)看起來不無相關(guān)的物品���,卻可以通過關(guān)聯(lián)分析,找出進(jìn)行同時(shí)銷售的機(jī)會(huì)出來,其背后的原理就是發(fā)現(xiàn)了�,啤酒和尿布之間的強(qiáng)關(guān)聯(lián)關(guān)系。
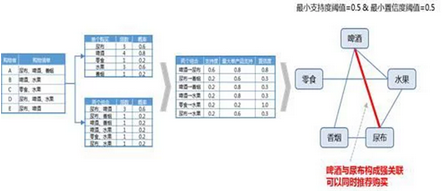
關(guān)聯(lián)分析案例計(jì)算過程
假設(shè)有尿布����,啤酒,零食�����,水果和香煙的五種商品����,同時(shí)也知道了各個(gè)商品購(gòu)買的清單,根據(jù)清單可以提取單個(gè)產(chǎn)品的頻數(shù)和其對(duì)應(yīng)的概率��,以及產(chǎn)品之間兩兩組合帶來頻數(shù)和概率���。根據(jù)支持度和置信度的計(jì)算公式�����,可以得到���,每個(gè)產(chǎn)品組合的支持度���,以及置信度。設(shè)置強(qiáng)關(guān)聯(lián)最小支出度閾值以及最小置信度閾值都為0.5時(shí)�,啤酒對(duì)尿布達(dá)到了強(qiáng)關(guān)聯(lián)的閾值,因此啤酒對(duì)尿布這對(duì)組合可以認(rèn)為具有強(qiáng)關(guān)聯(lián)���,因此在購(gòu)買啤酒時(shí)推薦購(gòu)買尿布���,能夠增加尿布的銷量。
預(yù)測(cè)估計(jì)
預(yù)測(cè)估計(jì)的規(guī)則�,是用來輸出連續(xù)的數(shù)值,即通過預(yù)測(cè)估計(jì)的規(guī)則�,模型輸出的是系列的數(shù)值,這些數(shù)值可以進(jìn)行加減乘除的一系列計(jì)算���。
預(yù)測(cè)估計(jì)基本思想
預(yù)測(cè)估計(jì)的規(guī)則通常以一個(gè)公式存在,這個(gè)公式可以體現(xiàn)出要輸出的因變量Y與特征變量X的關(guān)系����,最簡(jiǎn)單的來說,像一條在坐標(biāo)系反應(yīng)Y和X關(guān)系的直線一樣���,知道了X是多少的情況����,就可以根據(jù)線性關(guān)系,輸出對(duì)應(yīng)的Y�����。這種思路正式用于生成回歸方程���,因此有的時(shí)候預(yù)測(cè)估計(jì)也被稱為是回歸��。
在預(yù)測(cè)估計(jì)中�����,首先是對(duì)比訓(xùn)練集中要輸出的因變量Y和特征變量X的關(guān)系�,通常來說����,X不只有一個(gè),而是有X1�,X2,X3��,Xn等多個(gè)��,在這種情況下,通過學(xué)習(xí)X1到Xn與Y的數(shù)學(xué)關(guān)系�����,從而產(chǎn)生出能夠基于X1到XN預(yù)測(cè)出Y的規(guī)則�。如果規(guī)則通過驗(yàn)證集的驗(yàn)證,就可以在實(shí)習(xí)情況中與預(yù)測(cè)要輸出的因變量Y����。

會(huì)數(shù)據(jù)分析背后的挖掘思維���,分析就完成了一半!")
預(yù)測(cè)估計(jì)算法
預(yù)測(cè)估計(jì)的輸出變量可以是絕對(duì)值也可以是相對(duì)值���,在輸出絕對(duì)值的情況下,線性回歸是常用的模型��,即生成一條關(guān)于Y與X1到Xn的直線方程����,用來預(yù)測(cè)Y����。在輸出相對(duì)值得情況�����,邏輯回歸是常用的模型�����。在邏輯回歸中�,輸出的Y是概率���,在規(guī)則中通過擬合X的直線�����,產(chǎn)生出一個(gè)結(jié)果���,再將直線輸出結(jié)果進(jìn)行指數(shù)化轉(zhuǎn)換,最終結(jié)果就是的Y����,即事件發(fā)生概率。
下面是一個(gè)用預(yù)測(cè)估計(jì)的模型來預(yù)測(cè)誰(shuí)可以得獎(jiǎng)的例子���,在這個(gè)例子中����,并不是直接用模型預(yù)測(cè)得獎(jiǎng)的人員,而是通過對(duì)過去得獎(jiǎng)的人員的數(shù)據(jù)進(jìn)行學(xué)習(xí)����,從而得出計(jì)算得獎(jiǎng)概率的規(guī)則,并通過學(xué)習(xí)到的規(guī)則���,根據(jù)本次所有人的表現(xiàn)的數(shù)據(jù)���,來預(yù)測(cè)各自的將概率。

會(huì)數(shù)據(jù)分析背后的挖掘思維�����,分析就完成了一半!")
用預(yù)測(cè)估計(jì)知道得獎(jiǎng)概率
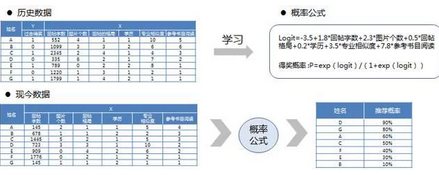
在這個(gè)例子中���,共有7個(gè)變量,其中過去得獎(jiǎng)是作為0-1因變量存在�,1表示得獎(jiǎng),0表示未得獎(jiǎng)。在自變量中有另外6個(gè)變量��。通過對(duì)歷史的數(shù)據(jù)的學(xué)習(xí)���,能夠得到logit的計(jì)算公式,并根據(jù)概率換算的公式�,得到概率的公式。
會(huì)數(shù)據(jù)分析背后的挖掘思維���,分析就完成了一半!")
再進(jìn)一步地,取得當(dāng)前數(shù)據(jù)后����,根據(jù)概率公式,得到每個(gè)人為的得獎(jiǎng)概率�,概率最大的即為最可能得獎(jiǎng)的人。
挖掘思維總結(jié)
在挖掘思維是與數(shù)據(jù)挖掘相關(guān)��,相比前面幾種思維而言�,挖掘思維似乎要晦澀難懂一些,畢竟數(shù)據(jù)挖掘涉及的已經(jīng)不局限于簡(jiǎn)單的數(shù)學(xué)�,而且還擴(kuò)充到了計(jì)算機(jī)科學(xué)層面。這里設(shè)置挖掘思維���,其目的就是在解答����,當(dāng)數(shù)據(jù)量實(shí)在太大時(shí),維度實(shí)在太多時(shí)����,應(yīng)該如何來處理的問題。
挖掘思維總結(jié)
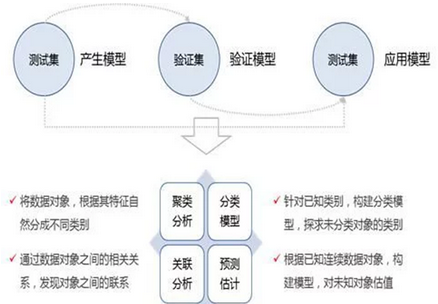
數(shù)據(jù)挖掘的實(shí)質(zhì)�,其實(shí)還是為了得到一個(gè)模型,產(chǎn)生結(jié)果�����。當(dāng)數(shù)據(jù)需要特別復(fù)雜的計(jì)算過程時(shí)��,數(shù)據(jù)挖掘就能夠產(chǎn)生作用了�����。數(shù)據(jù)挖掘通常通過已知輸出的結(jié)果的數(shù)據(jù)中作為訓(xùn)練集產(chǎn)生出模型��,再用另外一部分知道已知輸出結(jié)果的數(shù)據(jù)作為驗(yàn)證集來驗(yàn)證模型的可信程度����,通過驗(yàn)證后�����,再用到測(cè)試集中去取得實(shí)際的效果。
數(shù)據(jù)挖掘分為四種類型����,就像前面所述,四種類型分別是聚類分析����、分類模型、關(guān)聯(lián)分析和預(yù)測(cè)估計(jì)��。聚類分析是將數(shù)據(jù)對(duì)象��,根據(jù)其特征自然分成不同類別��。分類模型是針對(duì)已知類別��,構(gòu)建分類模型�,探求未分類對(duì)象的類別。關(guān)聯(lián)分析是通過數(shù)據(jù)對(duì)象之間的相關(guān)關(guān)系���,發(fā)現(xiàn)對(duì)象之間的聯(lián)系����。預(yù)測(cè)估計(jì)就是根據(jù)已知連續(xù)數(shù)據(jù)對(duì)象,構(gòu)建模型�,對(duì)未知對(duì)象估值。
舉一個(gè)簡(jiǎn)單的例子�,知道一個(gè)班之間學(xué)生平時(shí)作業(yè)的情況,將學(xué)生自動(dòng)分成若干類別�,就是聚類分析,這些有可能是學(xué)霸型��,學(xué)渣型���,還有可能是偏科型����,到底類別怎么樣���,事前都不知道�,要聚類以后才知道����。已知一部分學(xué)生的類別����,而不知道另外一部分學(xué)生��,就用分類模型的方式得出另外一些學(xué)生的類別���。知道一些學(xué)生掛語(yǔ)文的同時(shí)還容易掛哪些學(xué)科���,就是關(guān)聯(lián)分析��。從學(xué)生平時(shí)作業(yè)來預(yù)測(cè)他們期末考試分?jǐn)?shù)就是預(yù)測(cè)估計(jì)��。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試����,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情;
? 想學(xué)習(xí)CDA考試教材���,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫(kù)���,點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情���;
? 想了解CDA考試含金量,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330