R語言與點估計學習筆記(矩估計與MLE)
眾所周知���,R語言是個不錯的統(tǒng)計軟件�。今天分享一下利用R語言做點估計的內(nèi)容�����。主要有:矩估計、極大似然估計�、EM算法、最小二乘估計���、刀切法(Jackknife)���、自助法(Bootstrap)的相關(guān)內(nèi)容。
點估計是參數(shù)估計的一個組成部分。有許多的估計方法與估計理論���,具體內(nèi)容可以參見lehmann的《點估計理論》(推薦第一版����,第二版直接從UMVU估計開始的)
一�、矩估計
對于隨機變量來說,矩是其最廣泛�����,最常用的數(shù)字特征���,母體的各階矩一般與的分布中所含的未知參數(shù)有關(guān)���,有的甚至就等于未知參數(shù)。由辛欽大數(shù)定律知����,簡單隨機子樣的子樣原點矩依概率收斂到相應(yīng)的母體原點矩。這就啟發(fā)我們想到用子樣矩替換母體矩����,進而找出未知參數(shù)的估計����,基于這種思想求估計量的方法稱為矩法��。用矩法求得的估計稱為矩法估計��,簡稱矩估計����。它是由英國統(tǒng)計學家皮爾遜Pearson于1894年提出的。
因為不同的分布有著不同的參數(shù)�,所以在R的基本包中并沒有給出現(xiàn)成的函數(shù),我們通常使用人機交互的辦法處理矩估計的問題���,當然也可以自己編寫一些函數(shù)。
首先����,來看看R中給出的一些基本分布,如下表:
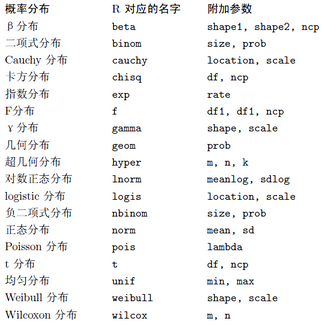
雖然R中基本包中沒有現(xiàn)成求各階矩的函數(shù)�����,但是對于給出的樣本��,R可以求出其平均值(函數(shù):mean),方差(var)���,標準差(sd)��,在fBasics包中還提供了計算偏度的函數(shù)skewness(),以及計算峰度的kurtosis()�。這樣我們也可以間接地得到分布一到四階矩的數(shù)據(jù)�����。由于低階矩包含信息較為豐富�,矩估計也一般采用低階矩去處理。
注:在actuar包中�,函數(shù)emm()可以計算樣本的任意階原點矩。但在參數(shù)估計時需要注意到原點矩的存在性
例如我們來看看正態(tài)分布N(0,1)的矩估計效果��。
> x<-rnorm(100) #產(chǎn)生N(0,1)的100個隨機數(shù)
> mu<-mean(x) #對N(mu,sigma)中的mu做矩估計
> sigma<-var(x) #這里的var并不是樣本方差的計算函數(shù)�����,而是修正的樣本方差���,其實也就是x的總體方差
> mu
[1] -0.1595923
> sigma
[1] 1.092255
可以看出����,矩估計的效果還是可以的。
我們再來看一個矩估計的例子:設(shè)總體X服從二項分布B(k,p)��,X1,X2,…,Xn�����,是總體的一個樣本��。K,p為未知參數(shù)�����。那么k,p的矩估計滿足方程:kp – M1= 0, kp(1 ? p) ?M2 = 0.
我們可以編寫函數(shù):
moment <-function(p){
f<-c(p[1]*p[2]-M1,p[1]*p[2]-p[1]*p[2]^2-M2)
J<-matrix(c(p[2],p[1],p[2]-p[2]^2,p[1]-2*p[1]*p[2]),nrow=2,byrow=T)#jicobi矩陣
list(f=f,J=J)
}# p[2]=p, p[1]=k,
檢驗程序
x<-rbinom(100, 20, 0.7); n<-length(x)
M1<-mean(x);M2<-(n-1)/n*var(x)
p<-c(10,0.5)
Newtons(moment, p)$root #是用牛頓法解方程的程序��,見附件1
運行結(jié)果為:
[1]22.973841 0.605036
可以得到k,p的數(shù)值解
二���、極大似然估計(MLE)
極大似然估計的基本思想是:基于樣本的信息參數(shù)的合理估計量是產(chǎn)生獲得樣本的最大概率的參數(shù)值��。值得一提的是:極大似然估計具有不變性,這也為我們求一些奇怪的參數(shù)提供了便利��。
在單參數(shù)場合��,我們可以使用函數(shù)optimize()來求極大似然估計值��,函數(shù)的介紹如下:
optimize(f = , interval = , ..., lower = min(interval),
upper = max(interval), maximum = FALSE,
tol = .Machine$double.eps^0.25)
例如我們來處理Poisson分布參數(shù)lambda的MLE。
設(shè)X1,X2,…,X100為來自P(lambda)的獨立同分布樣本���,那么似然函數(shù)為:
L(lambda�����,x)=lambda^(x1+x2+…+x100)*exp(10*lambda)/(gamma(x1+1)…gamma(x100+1))
這里涉及到的就是一個似然函數(shù)的選擇問題:是直接使用似然函數(shù)還是使用對數(shù)似然函數(shù)��,為了說明這個問題�,我們可以看這樣一段R程序:
> x<-rpois(100,2)
> sum(x)
[1] 215
> ga(x)#這是一個求解gamma(x1+1)…gamma(x100+1)的函數(shù)��,用gamma函數(shù)求階乘是為了提高計算效率(源代碼見附1)
[1] 1.580298e+51
> f<-function(lambda)lambda^(215)*exp(10*lambda)/(1.580298*10^51)#這里有一些magic number +
hard code 的嫌疑����,其實用ga(x)帶入,在函數(shù)參數(shù)中多加一個x就好
> optimize(f,c(1,3),maximum=T)
$maximum
[1] 2.999959
$objective
[1] 2.568691e+64
> fun<-function(lambda)-100*lambda+215*log(lambda)-log(1.580298*10^51)
> optimize(fun,c(1,3),maximum=T)
$maximum
[1] 2.149984 #MLE
$objective
[1] -168.3139
為什么會有這樣的差別�����?這個源于函數(shù)optimize��,這個函數(shù)本質(zhì)上就是求一個函數(shù)的最大值以及取最大值時的自變量����。但是這里對函數(shù)的穩(wěn)定性是有要求的�,取對數(shù)無疑增加了函數(shù)的穩(wěn)定性�,求極值才會合理。這也就是當你擴大了MLE存在區(qū)間時warning會出現(xiàn)的原因���。當然�,限定范圍時�,MLE會在邊界取到,但是�����,出現(xiàn)邊界時�,我們需要更多的信息去判斷它。這個例子也說明多數(shù)情況下利用對數(shù)似然估計要優(yōu)于似然函數(shù)���。
在多元ML估計時���,你能用的函數(shù)將變?yōu)閛ptim,nlm,nlminb它們的調(diào)用格式分別為:
optim(par, fn, gr = NULL, ..., method = c("Nelder-Mead", "BFGS", "CG", "L-BFGS-B", "SANN", "Brent"), lower = -Inf, upper = Inf, control = list(), hessian = FALSE)nlm(f, p, ..., hessian = FALSE, typsize = rep(1, length(p)), fscale = 1, print.level = 0, ndigit = 12, gradtol = 1e-6, stepmax = max(1000 * sqrt(sum((p/typsize)^2)), 1000), steptol = 1e-6, iterlim = 100, check.analyticals = TRUE)nlminb(start, objective, gradient = NULL, hessian = NULL, ..., scale = 1, control = list(), lower = -Inf, upper = Inf)
> x<-rnorm(1000,2,6) #6是標準差,而我們估計的是方差
> ll<-function(theta,data){
+ n<-length(data)
+ ll<--0.5*n*log(2*pi)-0.5*n*log(theta[2])-1/2/theta[2]*sum((data-theta[1])^2)
+ return(-ll)
+ }
>nlminb(c(0.5,2),ll,data=x,lower=c(-100,0),upper=c(100,100)) $par
[1] 1.984345 38.926692
看看結(jié)果估計的還是不錯的����,可以利用函數(shù)mean�����,var驗證對正態(tài)分布而言,矩估計與MLE是一致.
然而這里還有一些沒有解決的問題�,比如使用nlminb初始值的選取。希望閱讀到這的朋友給出些建議����。
最后指出在stata4,maxLik等擴展包中有更多關(guān)于mle的東西����,你可以通過查看幫助文檔來學習它。
附1:輔助程序代碼
Newtons<-function (fun, x, ep=1e-5,it_max=100){
index<-0; k<-1
while (k<=it_max){
x1 <- x; obj <- fun(x);
x <- x - solve(obj$J, obj$f);
norm <- sqrt((x-x1) %*% (x-x1))
if (norm<ep){
index<-1; break
}
k<-k+1
}
obj <- fun(x);
list(root=x, it=k, index=index, FunVal= obj$f)
}
ga<-function(x){
ga<-1
for(i in 1:length(x)){
ga<-ga*gamma(x[i]+1)
}
ga
}
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認證考試�����,點擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學習CDA考試教材�����,點擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量�����,點擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330