R語言:異常值檢驗����、離群點分析、異常值處理
筆者寄語:異常值處理一般分為以下幾個步驟:異常值檢測����、異常值篩選、異常值處理�����。其中異常值檢測的方法主要有:箱型圖、簡單統(tǒng)計量(比如觀察極值)
異常值處理方法主要有:刪除法��、插補法���、替換法���。
提到異常值不得不說一個詞:魯棒性。就是不受異常值影響���,一般是魯棒性高的數(shù)據(jù)��,比較優(yōu)質(zhì)��。
一���、異常值檢驗
異常值大概包括缺失值、離群值�、重復(fù)值,數(shù)據(jù)不一致。
1���、基本函數(shù)
summary可以顯示每個變量的缺失值數(shù)量.
2���、缺失值檢驗
關(guān)于缺失值的檢測應(yīng)該包括:缺失值數(shù)量�、缺失值比例��、缺失值與完整值數(shù)據(jù)篩選���。
[plain] view plain copy
print?在CODE上查看代碼片派生到我的代碼片
#缺失值解決方案
sum(complete.cases(saledata)) #is.na(saledata)
sum(!complete.cases(saledata))
mean(!complete.cases(saledata)) #1/201數(shù)字,缺失值比例
saledata[!complete.cases(saledata),] #篩選出缺失值的數(shù)值
3����、箱型圖檢驗離群值
箱型圖的檢測包括:四分位數(shù)檢測(箱型圖自帶)+1δ標(biāo)準(zhǔn)差上下+異常值數(shù)據(jù)點。
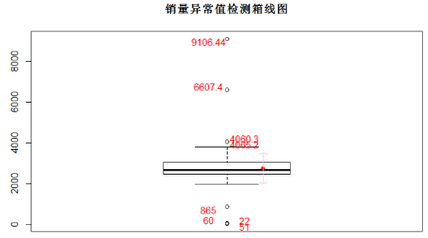
箱型圖有一個非常好的地方是�����,boxplot之后,結(jié)果中會自帶異常值,就是下面代碼中的sp$out����,這個是做箱型圖,按照上下邊界之外為異常值進行判定的��。
上下邊界����,分別是Q3+(Q3-Q1)、Q1-(Q3-Q1)��。
[plain] view plain copy
print?在CODE上查看代碼片派生到我的代碼片
sp=boxplot(saledata$"銷量",boxwex=0.7)
title("銷量異常值檢測箱線圖")
xi=1.1
sd.s=sd(saledata[complete.cases(saledata),]$"銷量")
mn.s=mean(saledata[complete.cases(saledata),]$"銷量")
points(xi,mn.s,col="red",pch=18)
arrows(xi, mn.s - sd.s, xi, mn.s + sd.s, code = 3, col = "pink", angle = 75, length = .1)
text(rep(c(1.05,1.05,0.95,0.95),length=length(sp$out)),labels=sp$out[order(sp$out)],
sp$out[order(sp$out)]+rep(c(150,-150,150,-150),length=length(sp$out)),col="red")
代碼中text函數(shù)的格式為text(x,label,y,col)���;points加入均值點�����;arrows加入均值上下1δ標(biāo)準(zhǔn)差范圍箭頭���。
4、數(shù)據(jù)去重
數(shù)據(jù)去重與數(shù)據(jù)分組合并存在一定區(qū)別�,去重是純粹的所有變量都是重復(fù)的,而數(shù)據(jù)分組合并可能是因為一些主鍵的重復(fù)��。
數(shù)據(jù)去重包括重復(fù)檢測(table�����、unique函數(shù))以及重復(fù)數(shù)據(jù)處理(unique/duplicated)��。
常見的有unique�、數(shù)據(jù)框中duplicated函數(shù),duplicated返回的是邏輯值���。
二��、異常值處理
常見的異常值處理辦法是刪除法��、替代法(連續(xù)變量均值替代��、離散變量用眾數(shù)以及中位數(shù)替代)�����、插補法(回歸插補�����、多重插補)
除了直接刪除��,可以先把異常值變成缺失值����、然后進行后續(xù)缺失值補齊�����。
實踐中�����,異常值處理,一般劃分為NA缺失值或者返回公司進行數(shù)據(jù)修整(數(shù)據(jù)返修為主要方法)
1��、異常值識別
利用圖形——箱型圖進行異常值檢測�����。
[plain] view plain copy
print?在CODE上查看代碼片派生到我的代碼片
#異常值識別
par(mfrow=c(1,2))#將繪圖窗口劃為1行兩列�����,同時顯示兩圖
dotchart(inputfile$sales)#繪制單變量散點圖,多蘭圖
pc=boxplot(inputfile$sales,horizontal=T)#繪制水平箱形圖
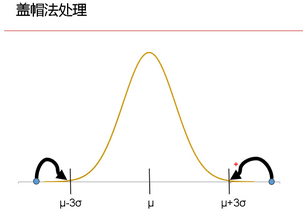
2���、蓋帽法
整行替換數(shù)據(jù)框里99%以上和1%以下的點����,將99%以上的點值=99%的點值��;小于1%的點值=1%的點值���。
[html] view plain copy
print?在CODE上查看代碼片派生到我的代碼片
#異常數(shù)據(jù)處理
q1<-quantile(result$tot_derog, 0.001) #取得時1%時的變量值
q99<-quantile(result$tot_derog, 0.999) #replacement has 1 row, data has 0 說明一個沒換
result[result$tot_derog result[result$tot_derog>q99,]$tot_derog<-q99
summary(result$tot_derog) #蓋帽法之后�,查看數(shù)據(jù)情況
fix(inputfile)#表格形式呈現(xiàn)數(shù)據(jù)
which(inputfile$sales==6607.4)#可以找到極值點序號是啥
把缺失值數(shù)據(jù)集����、非缺失值數(shù)據(jù)集分開�。
[plain] view plain copy
print?在CODE上查看代碼片派生到我的代碼片
#缺失值的處理
inputfile$date=as.numeric(inputfile$date)#將日期轉(zhuǎn)換成數(shù)值型變量
sub=which(is.na(inputfile$sales))#識別缺失值所在行數(shù)
inputfile1=inputfile[-sub,]#將數(shù)據(jù)集分成完整數(shù)據(jù)和缺失數(shù)據(jù)兩部分
inputfile2=inputfile[sub,]
3�����、噪聲數(shù)據(jù)處理——分箱法
將連續(xù)變量等級化之后����,不同的分位數(shù)的數(shù)據(jù)就會變成不同的等級數(shù)據(jù),連續(xù)變量離散化了���,消除了極值的影響。
4���、異常值處理——均值替換
數(shù)據(jù)集分為缺失值���、非缺失值兩塊內(nèi)容。缺失值處理如果是連續(xù)變量�����,可以選擇均值��;離散變量,可以選擇眾數(shù)或者中位數(shù)���。
計算非缺失值數(shù)據(jù)的均值�,
然后賦值給缺失值數(shù)據(jù)�����。
[plain] view plain copy
print?在CODE上查看代碼片派生到我的代碼片
#均值替換法處理缺失��,結(jié)果轉(zhuǎn)存
#思路:拆成兩份�,把缺失值一份用均值賦值,然后重新合起來
avg_sales=mean(inputfile1$sales)#求變量未缺失部分的均值
inputfile2$sales=rep(avg_sales,n)#用均值替換缺失
result2=rbind(inputfile1,inputfile2)#并入完成插補的數(shù)據(jù)
5�、異常值處理——回歸插補法
[plain] view plain copy
print?在CODE上查看代碼片派生到我的代碼片
#回歸插補法處理缺失,結(jié)果轉(zhuǎn)存
model=lm(sales~date,data=inputfile1)#回歸模型擬合
inputfile2$sales=predict(model,inputfile2)#模型預(yù)測
result3=rbind(inputfile1,inputfile2)
6��、異常值處理——多重插補——mice包
注意:多重插補的處理有兩個要點:先刪除Y變量的缺失值然后插補
1����、被解釋變量有缺失值的觀測不能填補,只能刪除����,不能自己亂補;
2、只對放入模型的解釋變量進行插補���。
比較詳細(xì)的來介紹一下這個多重插補法���。筆者整理了大致的步驟簡介如下:
缺失數(shù)據(jù)集——MCMC估計插補成幾個數(shù)據(jù)集——每個數(shù)據(jù)集進行插補建模(glm、lm模型)——將這些模型整合到一起(pool)——評價插補模型優(yōu)劣(模型系數(shù)的t統(tǒng)計量)——輸出完整數(shù)據(jù)集(compute)
步驟詳細(xì)介紹:
函數(shù)mice()首先從一個包含缺失數(shù)據(jù)的數(shù)據(jù)框開始�����,然后返回一個包含多個(默認(rèn)為5個)完整數(shù)據(jù)集的對象���。
每個完整數(shù)據(jù)集都是通過對原始數(shù)據(jù)框中的缺失數(shù)據(jù)進行插補而生成的�。 由于插補有隨機的成分����,因此每個完整數(shù)據(jù)集都略有不同。
其中�,mice中使用決策樹cart有以下幾個要注意的地方:該方法只對數(shù)值變量進行插補����,分類變量的缺失值保留,cart插補法一般不超過5k數(shù)據(jù)集�。
然后, with()函數(shù)可依次對每個完整數(shù)據(jù)集應(yīng)用統(tǒng)計模型(如線性模型或廣義線性模型) �,
最后��, pool()函數(shù)將這些單獨的分析結(jié)果整合為一組結(jié)果�。最終模型的標(biāo)準(zhǔn)誤和p值都將準(zhǔn)確地反映出由于缺失值和多重插補而產(chǎn)生的不確定性��。
[plain] view plain copy
print?在CODE上查看代碼片派生到我的代碼片
#多重插補法處理缺失��,結(jié)果轉(zhuǎn)存
library(lattice) #調(diào)入函數(shù)包
library(MASS)
library(nnet)
library(mice) #前三個包是mice的基礎(chǔ)
imp=mice(inputfile,m=4) #4重插補����,即生成4個無缺失數(shù)據(jù)集
fit=with(imp,lm(sales~date,data=inputfile))#選擇插補模型
pooled=pool(fit)
summary(pooled)
result4=complete(imp,action=3)#選擇第三個插補數(shù)據(jù)集作為結(jié)果
結(jié)果解讀:
(1)imp對象中,包含了:每個變量缺失值個數(shù)信息����、每個變量插補方式(PMM,預(yù)測均值法常見)����、插補的變量有哪些、預(yù)測變量矩陣(在矩陣中����,行代表插補變量,列代表為插補提供信息的變量�����, 1和0分別表示使用和未使用);
同時 利用這個代碼imp$imp$sales 可以找到���,每個插補數(shù)據(jù)集缺失值位置的數(shù)據(jù)補齊具體數(shù)值是啥��。
[plain] view plain copy
print?在CODE上查看代碼片派生到我的代碼片
> imp$imp$sales
1 2 3 4
9 3614.7 3393.1 4060.3 3393.1
15 2332.1 3614.7 3295.5 3614.7
(2)with對象�����。插補模型可以多樣化����,比如lm�����,glm都是可以直接應(yīng)用進去����,詳情可見《R語言實戰(zhàn)》第十五章;
(3)pool對象��。summary之后�,會出現(xiàn)lm模型系數(shù),可以如果出現(xiàn)系數(shù)不顯著�����,那么則需要考慮換插補模型�;
(4)complete對象。m個完整插補數(shù)據(jù)集����,同時可以利用此函數(shù)輸出。
其他:
mice包提供了一個很好的函數(shù)md.pattern()�,用它可以對缺失數(shù)據(jù)的模式有個更好的理解。還有一些可視化的界面�����,通過VIM�、箱型圖、lattice來展示缺失值情況���。
三��、離群點檢測
離群點檢測與第二節(jié)異常值主要的區(qū)別在于����,異常值針對單一變量,而離群值指的是很多變量綜合考慮之后的異常值����。下面介紹一種基于聚類+歐氏距離的離群點檢測方法。
基于聚類的離群點檢測的步驟如下:數(shù)據(jù)標(biāo)準(zhǔn)化——聚類——求每一類每一指標(biāo)的均值點——每一類每一指標(biāo)生成一個矩陣——計算歐式距離——畫圖判斷��。
[plain] view plain copy
print?在CODE上查看代碼片派生到我的代碼片
Data=read.csv(".data.csv",header=T)[,2:4]
Data=scale(Data)
set.seed(12)
km=kmeans(Data,center=3)
print(km)
km$centers #每一類的均值點
#各樣本歐氏距離��,每一行
x1=matrix(km$centers[1,], nrow = 940, ncol =3 , byrow = T)
juli1=sqrt(rowSums((Data-x1)^2))
x2=matrix(km$centers[2,], nrow = 940, ncol =3 , byrow = T)
juli2=sqrt(rowSums((Data-x2)^2))
x3=matrix(km$centers[3,], nrow = 940, ncol =3 , byrow = T)
juli3=sqrt(rowSums((Data-x3)^2))
dist=data.frame(juli1,juli2,juli3)
##歐氏距離最小值
y=apply(dist, 1, min)
plot(1:940,y,xlim=c(0,940),xlab="樣本點",ylab="歐氏距離")
points(which(y>2.5),y[which(y>2.5)],pch=19,col="red")
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認(rèn)證考試���,點擊>>>
“CDA報名”
了解CDA考試詳情�;
? 想學(xué)習(xí)CDA考試教材�,點擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫���,點擊>>> “CDA題庫” 了解CDA考試詳情����;
? 想了解CDA考試含金量����,點擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330