數(shù)據(jù)挖掘案例—ReliefF和K-means算法的醫(yī)學(xué)應(yīng)用
數(shù)據(jù)挖掘方法的提出,讓人們有能力最終認(rèn)識數(shù)據(jù)的真正價(jià)值����,即蘊(yùn)藏在數(shù)據(jù)中的信息和知識��。數(shù)據(jù)挖掘 (DataMiriing)���,指的是從大型數(shù)據(jù)庫或數(shù)據(jù)倉庫中提取人們感興趣的知識,這些知識是隱含的��、事先未知的潛在有用信息���,數(shù)據(jù)挖掘是目前國際上�,數(shù)據(jù)庫和信息決策領(lǐng)域的最前沿研究方向之一���。因此分享一下很久以前做的一個(gè)小研究成果����。也算是一個(gè)簡單的數(shù)據(jù)挖掘處理的例子。
1.數(shù)據(jù)挖掘與聚類分析概述
數(shù)據(jù)挖掘一般由以下幾個(gè)步驟:
(l)分析問題:源數(shù)據(jù)數(shù)據(jù)庫必須經(jīng)過評估確認(rèn)其是否符合數(shù)據(jù)挖掘標(biāo)準(zhǔn)�����。以決定預(yù)期結(jié)果��,也就選擇了這項(xiàng)工作的最優(yōu)算法�����。
(2)提取���、清洗和校驗(yàn)數(shù)據(jù):提取的數(shù)據(jù)放在一個(gè)結(jié)構(gòu)上與數(shù)據(jù)模型兼容的數(shù)據(jù)庫中��。以統(tǒng)一的格式清洗那些不一致�����、不兼容的數(shù)據(jù)。一旦提取和清理數(shù)據(jù)后����,瀏覽所創(chuàng)建的模型,以確保所有的數(shù)據(jù)都已經(jīng)存在并且完整�。
(3)創(chuàng)建和調(diào)試模型:將算法應(yīng)用于模型后產(chǎn)生一個(gè)結(jié)構(gòu)�。瀏覽所產(chǎn)生的結(jié)構(gòu)中數(shù)據(jù)��,確認(rèn)它對于源數(shù)據(jù)中“事實(shí)”的準(zhǔn)確代表性���,這是很重要的一點(diǎn)���。雖然可能無法對每一個(gè)細(xì)節(jié)做到這一點(diǎn),但是通過查看生成的模型����,就可能發(fā)現(xiàn)重要的特征。
(4)查詢數(shù)據(jù)挖掘模型的數(shù)據(jù):一旦建立模型�,該數(shù)據(jù)就可用于決策支持了。
(5)維護(hù)數(shù)據(jù)挖掘模型:數(shù)據(jù)模型建立好后��,初始數(shù)據(jù)的特征���,如有效性�,可能發(fā)生改變�。一些信息的改變會對精度產(chǎn)生很大的影響,因?yàn)樗淖兓绊懽鳛榛A(chǔ)的原始模型的性質(zhì)���。因而�����,維護(hù)數(shù)據(jù)挖掘模型是非常重要的環(huán)節(jié)����。
聚類分析是數(shù)據(jù)挖掘采用的核心技術(shù),成為該研究領(lǐng)域中一個(gè)非?���;钴S的研究課題。聚類分析基于”物以類聚”的樸素思想�,根據(jù)事物的特征,對其進(jìn)行聚類或分類��。作為數(shù)據(jù)挖掘的一個(gè)重要研究方向���,聚類分析越來越得到人們的關(guān)注�����。聚類的輸入是一組沒有類別標(biāo)注的數(shù)據(jù)�����,事先可以知道這些數(shù)據(jù)聚成幾簇爪也可以不知道聚成幾簇。通過分析這些數(shù)據(jù)����,根據(jù)一定的聚類準(zhǔn)則,合理劃分記錄集合�����,從而使相似的記錄被劃分到同一個(gè)簇中�����,不相似的數(shù)據(jù)劃分到不同的簇中�����。
Relief為一系列算法�,它包括最早提出的Relief以及后來拓展的ReliefF和RReliefF,其中RReliefF算法是針對目標(biāo)屬性為連續(xù)值的回歸問題提出的����,下面僅介紹一下針對分類問題的Relief和ReliefF算法。
2.1Relief算法
Relief算法最早由Kira提出����,最初局限于兩類數(shù)據(jù)的分類問題����。Relief算法是一種特征權(quán)重算法(Feature weighting algorithms),根據(jù)各個(gè)特征和類別的相關(guān)性賦予特征不同的權(quán)重���,權(quán)重小于某個(gè)閾值的特征將被移除�����。Relief算法中特征和類別的相關(guān)性是基于特征對近距離樣本的區(qū)分能力。算法從訓(xùn)練集D中隨機(jī)選擇一個(gè)樣本R��,然后從和R同類的樣本中尋找最近鄰樣本H�����,稱為Near Hit�,從和R不同類的樣本中尋找最近鄰樣本M,稱為NearMiss����,然后根據(jù)以下規(guī)則更新每個(gè)特征的權(quán)重:如果R和Near Hit在某個(gè)特征上的距離小于R和Near Miss上的距離����,則說明該特征對區(qū)分同類和不同類的最近鄰是有益的�,則增加該特征的權(quán)重����;反之,如果R和Near Hit在某個(gè)特征的距離大于R和Near Miss上的距離����,說明該特征對區(qū)分同類和不同類的最近鄰起負(fù)面作用,則降低該特征的權(quán)重�。以上過程重復(fù)m次,最后得到各特征的平均權(quán)重�����。特征的權(quán)重越大�����,表示該特征的分類能力越強(qiáng)�����,反之,表示該特征分類能力越弱����。Relief算法的運(yùn)行時(shí)間隨著樣本的抽樣次數(shù)m和原始特征個(gè)數(shù)N的增加線性增加,因而運(yùn)行效率非常高�����。具體算法如下所示:

2.2 ReliefF算法
由于Relief算法比較簡單����,但運(yùn)行效率高,并且結(jié)果也比較令人滿意����,因此得到廣泛應(yīng)用,但是其局限性在于只能處理兩類別數(shù)據(jù)�����,因此1994年Kononeill對其進(jìn)行了擴(kuò)展�,得到了ReliefF作算法,可以處理多類別問題��。該算法用于處理目標(biāo)屬性為連續(xù)值的回歸問題。ReliefF算法在處理多類問題時(shí)����,每次從訓(xùn)練樣本集中隨機(jī)取出一個(gè)樣本R,然后從和R同類的樣本集中找出R的k個(gè)近鄰樣本(near Hits)�����,從每個(gè)R的不同類的樣本集中均找出k個(gè)近鄰樣本(near Misses)���,然后更新每個(gè)特征的權(quán)重,如下式所示:

Relief系列算法運(yùn)行效率高�,對數(shù)據(jù)類型沒有限制,屬于一種特征權(quán)重算法���,算法會賦予所有和類別相關(guān)性高的特征較高的權(quán)重���,所以算法的局限性在于不能有效的去除冗余特征。
2.3 K-means聚類算法
由于聚類算法是給予數(shù)據(jù)自然上的相似劃法���,要求得到的聚類是每個(gè)聚類內(nèi)部數(shù)據(jù)盡可能的相似而聚類之間要盡可能的大差異��。所以定義一種尺度來衡量相似度就顯得非常重要了����。一般來說,有兩種定義相似度的方法����。第一種方法是定義數(shù)據(jù)之間的距離,描述的是數(shù)據(jù)的差異�。第二種方法是直接定義數(shù)據(jù)之間的相似度。下面是幾種常見的定義距離的方法:
1.Euclidean距離����,這是一種傳統(tǒng)的距離概念,適合于2��、3維空間�����。
2.Minkowski距離��,是Euclidean距離的擴(kuò)展�,可以理解為N維空間的距離。
聚類算法有很多種����,在需要時(shí)可以根據(jù)所涉及的數(shù)據(jù)類型�、聚類的目的以及具的應(yīng)用要求來選擇合適的聚類算法����。下面介紹 K-means聚類算法:
K-means算法是一種常用的基于劃分的聚類算法。K-means算法是以k為參數(shù)�,把n個(gè)對象分成k個(gè)簇,使簇內(nèi)具有較高的相似度��,而簇間的相似度較低�����。K-means的處理過程為:首先隨機(jī)選擇k個(gè)對象作為初始的k個(gè)簇的質(zhì)心�����;然后將余對象根據(jù)其與各個(gè)簇的質(zhì)心的距離分配到最近的簇���;最后重新計(jì)算各個(gè)簇的質(zhì)心。不斷重復(fù)此過程�,直到目標(biāo)函數(shù)最小為止。簇的質(zhì)心由公式下列式子求得:

在具體實(shí)現(xiàn)時(shí)�,為了防止步驟2中的條件不成立而出現(xiàn)無限循環(huán),往往定義一個(gè)最大迭代次數(shù)����。K-means嘗試找出使平方誤差函數(shù)值最小的k個(gè)劃分���。當(dāng)數(shù)據(jù)分布較均勻,且簇與簇之間區(qū)別明顯時(shí)���,它的效果較好����。面對大規(guī)模數(shù)據(jù)集��,該算法是相對可擴(kuò)展的�����,并且具有較高的效率��。其中���,n為數(shù)據(jù)集中對象的數(shù)目���,k為期望得到的簇的數(shù)目,t為迭代的次數(shù)�。通常情況下�,算法會終止于局部最優(yōu)解�。但用,例如涉及有非數(shù)值屬性的數(shù)據(jù)���。其次�,這種算法要求事先給出要生成的簇的數(shù)目k��,顯然這對用戶提出了過高的要求��,并且由于算法的初始聚類中心是隨機(jī)選擇的���,而不同的初始中心對聚類結(jié)果有很大的影響��。另外,K-means算法不適用于發(fā)現(xiàn)非凸面形狀的簇�,或者大小差別很大的簇,而且它對于噪音和孤立點(diǎn)數(shù)據(jù)是敏感的����。
3.一個(gè)醫(yī)學(xué)數(shù)據(jù)分析實(shí)例
3.1 數(shù)據(jù)說明
本文實(shí)驗(yàn)數(shù)據(jù)來自著名的UCI機(jī)器學(xué)習(xí)數(shù)據(jù)庫,該數(shù)據(jù)庫有大量的人工智能數(shù)據(jù)挖掘數(shù)據(jù)�����,網(wǎng)址為:http://archive.ics.uci.edu/ml/。該數(shù)據(jù)庫是不斷更新的���,也接受數(shù)據(jù)的捐贈�����。數(shù)據(jù)庫種類涉及生活�����、工程��、科學(xué)各個(gè)領(lǐng)域����,記錄數(shù)也是從少到多�����,最多達(dá)幾十萬條��。截止2010年底����,數(shù)據(jù)庫共有199個(gè)數(shù)據(jù)集����,每個(gè)數(shù)據(jù)集合中有不同類型��、時(shí)間的相關(guān)數(shù)據(jù)�。可以根據(jù)實(shí)際情況進(jìn)行選用���。
本文選用的數(shù)據(jù)來類型為:Breast Cancer Wisconsin (Original) Data Set�,中文名稱為:威斯康星州乳腺癌數(shù)據(jù)集��。這些數(shù)據(jù)來源美國威斯康星大學(xué)醫(yī)院的臨床病例報(bào)告�����,每條數(shù)據(jù)具有11個(gè)屬性��。下載下來的數(shù)據(jù)文件格式為“.data”,通過使用Excel和Matlab工具將其轉(zhuǎn)換為Matlab默認(rèn)的數(shù)據(jù)集保存�����,方便程序進(jìn)行調(diào)用�。
下表是該數(shù)據(jù)集的11個(gè)屬性名稱及說明:
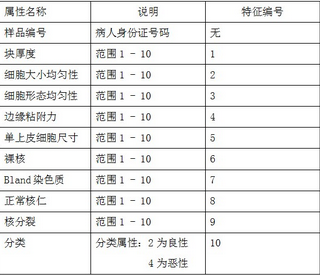
對上述數(shù)據(jù)進(jìn)行轉(zhuǎn)換后,以及數(shù)據(jù)說明可知�����,可以用于特征提取的有9個(gè)指標(biāo)����,樣品編號和分類只是用于確定分類。本文的數(shù)據(jù)處理思路是先采用ReliefF特征提取算法計(jì)算各個(gè)屬性的權(quán)重���,剔除相關(guān)性最小的屬性�,然后采用K-means聚類算法對剩下的屬性進(jìn)行聚類分析����。
3.2 數(shù)據(jù)預(yù)處理與程序
本文在轉(zhuǎn)換數(shù)據(jù)后,首先進(jìn)行了預(yù)處理�,由于本文的數(shù)據(jù)范圍都是1-10,因此不需要?dú)w一化�����,但是數(shù)據(jù)樣本中存在一些不完整��,會影響實(shí)際的程序運(yùn)行���,經(jīng)過程序處理��,將這一部分?jǐn)?shù)據(jù)刪除���。這些不完整的數(shù)據(jù)都是由于實(shí)際中一些原因沒有登記或者遺失的���,以“?”的形式代表。
本文采用Matlab軟件進(jìn)行編程計(jì)算�。根據(jù)第三章提到的ReliefF算法過程,先編寫ReliefF函數(shù)程序�����,用來計(jì)算特征屬性�,再編寫主程序,在主程序中調(diào)用該函數(shù)進(jìn)行計(jì)算���,并對結(jié)果進(jìn)行分析���,繪圖,得到有用的結(jié)論�。
程序統(tǒng)一在最后貼出。
3.3 乳腺癌數(shù)據(jù)集特征提取
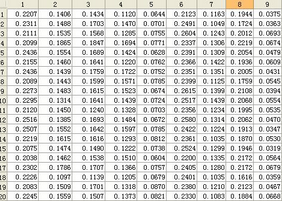
本文采用3.1節(jié)中的ReliefF算法來計(jì)算各個(gè)特征的權(quán)重�����,權(quán)重小于某個(gè)閾值的特征將被移除�����,針對本文的實(shí)際情況�,將對權(quán)重最小的2-3種剔除。由于算法在運(yùn)行過程中���,會選擇隨機(jī)樣本R����,隨機(jī)數(shù)的不同將導(dǎo)致結(jié)果權(quán)重有一定的出入�����,因此本文采取平均的方法����,將主程序運(yùn)行20次,然后將結(jié)果匯總求出每種權(quán)重的平均值��。如下所示�����,列為屬性編號,行為每一次的計(jì)算結(jié)果:
下面是特征提取算法計(jì)算的特征權(quán)重趨勢圖���,計(jì)算20次的結(jié)果趨勢相同:
上述結(jié)果是否運(yùn)行主程序所得的計(jì)算結(jié)果���,看起來不直觀,下面將其按照順序繪圖����,可以直觀顯示各個(gè)屬性權(quán)重的大小分布,如下圖所示:
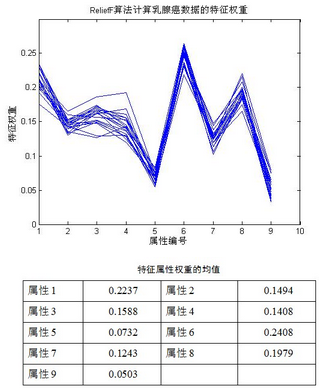
按照從小到大順序排列���,可知�����,各個(gè)屬性的權(quán)重關(guān)系如下:
屬性9<屬性5<屬性7<屬性4<屬性2<屬性3<屬性8<屬性1<屬性6
我們選定權(quán)重閥值為0.02����,則屬性9�、屬性4和屬性5剔除。
從上面的特征權(quán)重可以看出�,屬性6裸核大小是最主要的影響因素���,說明乳腺癌患者的癥狀最先表現(xiàn)了裸核大小上,將直接導(dǎo)致裸核大小的變化��,其次是屬性1和屬性8等��,后幾個(gè)屬性權(quán)重大小接近�����,但是從多次計(jì)算規(guī)律來看����,還是能夠說明其中不同的重要程度�,下面是著重對幾個(gè)重要的屬性進(jìn)行分析。下面是20次測試中�,裸核大小(屬性6)的權(quán)重變化:
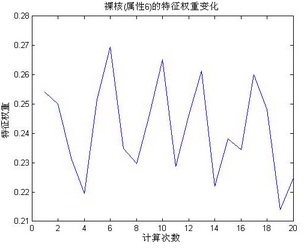
從上圖中可以看到該屬性權(quán)重大部分在0.22-0.26左右�����,是權(quán)重最大的一個(gè)屬性��。下面看看屬性1的權(quán)重分布:
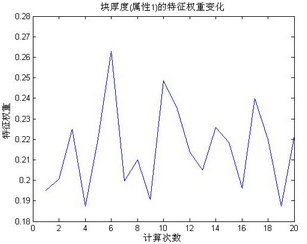
塊厚度屬性的特征權(quán)重在0.19-25左右變動�,也是權(quán)重極高的一個(gè)�,說明該特征屬性在乳腺癌患者檢測指標(biāo)中是相當(dāng)重要的一個(gè)判斷依據(jù)�����。進(jìn)一步分析顯示����,在單獨(dú)對屬性6,和屬性1進(jìn)行聚類分析����,其成功率就可以達(dá)到91.8%。本文將在下節(jié)中的Kmeans算法中詳細(xì)介紹�。
3.4 乳腺癌數(shù)據(jù)集聚類分析
上一節(jié)中通過ReliefF算法對數(shù)據(jù)集的分析,可以得到屬性權(quán)重的重要程度��,這些可以對臨床診斷有一些參考價(jià)值��,可以用來對實(shí)際案例進(jìn)行分析��,可以盡量的避免錯(cuò)誤診斷��,并提高診斷的速度和正確率�����。下面將通過K-menas聚類分析算法對數(shù)據(jù)進(jìn)行分析。本小節(jié)將分為幾個(gè)步驟來進(jìn)行對比���,確定聚類分析算法的結(jié)果以及與ReliefF算法結(jié)合的結(jié)果等���。
1.K-means算法單獨(dú)分析數(shù)據(jù)集
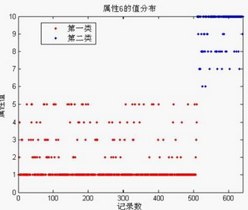
下面將采用Kmeans算法單獨(dú)對數(shù)據(jù)集進(jìn)行分析。Matlab中已經(jīng)包括了一些常規(guī)數(shù)據(jù)挖掘的算法����,例如本文所用到的K-means算法���。該函數(shù)名為kmeans��,可以對數(shù)據(jù)集進(jìn)行聚類分析����。首先本文對乳腺癌數(shù)據(jù)集的所有屬性列(除去身份信息和分類列)直接進(jìn)行分類�,由于數(shù)據(jù)集結(jié)果只有2種類型,所以首先進(jìn)行分2類的測試��,結(jié)果如下:總體將683條數(shù)據(jù)分成了2類�����,總體的正確率為94.44%,其中第一類的正確率為93.56%�,第二類的正確率為96.31%。下面是分類后對按照不同屬性的繪制的屬性值分布圖:
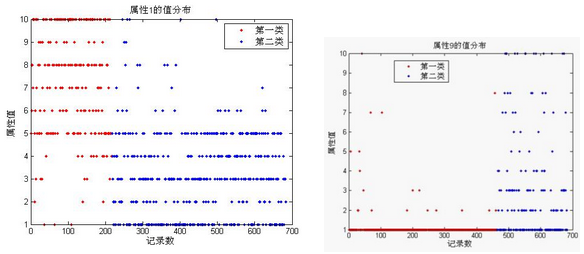
限于篇幅����,只選擇了上述3個(gè)特征屬性進(jìn)行圖像繪制,從結(jié)果來看����, 可以很直觀的觀察到K-means算法分類后的情況,第一類與第一類的分類界限比較清晰�����。但是不容易觀察到正確和錯(cuò)誤的情況�����。下表是分類結(jié)果中各個(gè)屬性的聚類中心:
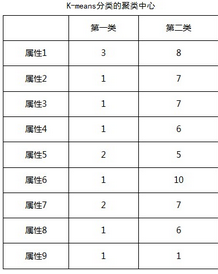
從K-means算法的效果來看����,能夠很準(zhǔn)確的將數(shù)據(jù)集進(jìn)行分類。一方面是由于該數(shù)據(jù)集���,可能是該案例特征比較明顯���,另一方面是由于K-menas算法對這種2類的作用較大����。
2.K-means結(jié)合ReliefF分析數(shù)據(jù)集
單從分類正確率和結(jié)果方面來看����,K-mens算法已經(jīng)完全可以對乳腺癌數(shù)據(jù)集做出非常準(zhǔn)確的判斷。但是考慮ReliefF算法對屬性權(quán)重的影響�,本小節(jié)將結(jié)合ReliefF算法和K-means算法來對該數(shù)據(jù)集進(jìn)行分析,一方面得到處理該問題一些簡單的結(jié)論�,另外一方面可以得到一些對醫(yī)學(xué)處理數(shù)據(jù)的方法研究方法����。
首先,本小節(jié)首先根據(jù)3.2節(jié)中的一些結(jié)論�,根據(jù)不同屬性的權(quán)重來對k-menas分類數(shù)據(jù)進(jìn)行預(yù)處理,以得到更精確的結(jié)論和對該數(shù)據(jù)更深度的特征規(guī)律���。
從3.2節(jié)中��,得知屬性9<屬性5<屬性7<屬性4<屬性2<屬性3<屬性8<屬性1<屬性6�,根據(jù)ReliefF算法原理本文可以認(rèn)為,對于這種屬性6和屬性1重要的特征屬性����,應(yīng)該對分類起到更加到的作用。所以下面將單獨(dú)對各個(gè)屬性的數(shù)據(jù)進(jìn)行分類測試��,詳細(xì)結(jié)果如下表:
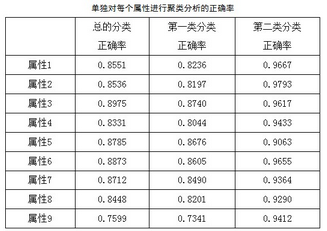
總的分類正確率中����,屬性9最低,屬性6最高���,這與ReliefF算法測試的結(jié)果大致相似�,但是由于ReliefFar算法中間部分權(quán)重接近��,所以也區(qū)分不明顯�。說明特征屬性權(quán)重的判斷對分類是有影響的。上述單獨(dú)分類中���,只將需要分類的列數(shù)據(jù)取出來���,輸入到K-means算法中即可。由于輸入數(shù)據(jù)的變化�,K-means分類時(shí)結(jié)果肯定是有差距的���,所以單獨(dú)從一個(gè)屬性判斷其類型是不可靠的。下面選擇了單個(gè)分類時(shí)最高和最低的情況��,繪制其分類屬性值分布圖����,如下圖所示:
下面將對特征權(quán)重按照從大到小的順序,選擇相應(yīng)的數(shù)據(jù)����,進(jìn)行聚類分析,結(jié)論如下:
1.直接選擇全部9種屬性����,分類成功率為:94.44%;
2.選擇屬性6�����,屬性1����,分類成功率為:91.36%���;
3.選擇屬性6�,1,8�,3,分類成功率為:93.85%���;
4.選擇屬性6���,1,8�,3,2�����,4�,分類成功率為:94.48%;
5.選擇屬性6����,1,8��,3��,2,4���,5�����,7�����,分類成功率為:95.02%��;
從上面的測試可以看出�,選擇特征權(quán)重最大的6個(gè)屬性��,其正確率就達(dá)到選擇所有屬性的情況����,因此我們可以認(rèn)為特征權(quán)重最小的幾個(gè)屬性在乳腺癌診斷過程的作用實(shí)際可能比較小,實(shí)際有可能造成反作用����,也就是這幾個(gè)屬性值與乳腺癌沒有必然的聯(lián)系��。這一點(diǎn)可以給診斷參考,或者引起注意�����,進(jìn)行進(jìn)一步的研究���,確認(rèn)����。
3. K-means分成3類的情況
雖然從上述2小節(jié)的實(shí)驗(yàn)中可以得到該數(shù)據(jù)集的大部分結(jié)果和結(jié)論�����。但是為了將相同類型的數(shù)據(jù)更加準(zhǔn)確的分出�,下面將嘗試分為3類的情況。一方面��,可以分析在乳腺癌良性和惡性情況下的顯著特征屬性�;另一方面也可以根據(jù)此結(jié)果找到更加合理的解決方法。
還是采用Matlab中的kmeans函數(shù)�,將分類數(shù)改為3,由于分為3類后數(shù)據(jù)類型增多��,判斷較復(fù)雜����,所以手動對數(shù)據(jù)進(jìn)行分析���,將所有特征屬性加入進(jìn)去。運(yùn)行結(jié)果如下��,測試數(shù)據(jù)中總共683條��,其中良性共444條��,惡性共239條:
1.分為第一類的記錄中�����,良性占96.88%����;
2.分為第二類的記錄中,惡性占 100% �����;
3.分為第三類的記錄中����,惡性占 92%;
根據(jù)上述結(jié)果可以認(rèn)為第一類為良性的分類����,第二類為惡性分類,第三類為混合類���。對于混合類����,說明里面的數(shù)據(jù)較其他數(shù)據(jù)更加接近于偏離病例的典型數(shù)據(jù)����,所以進(jìn)一步分析在第一類中和第二類中的分類正確率:
1.第一類為良性,共448條數(shù)據(jù)���,分類正確率為96.88%���;
2.第二類為惡性,共99條數(shù)據(jù)�����,分類正確率為 100% ����;
3.第三類為混合類��,共136條數(shù)據(jù)
因此單獨(dú)從分類后的正確率來看�����,效果有提高���,說明對典型的病例數(shù)據(jù)分類更準(zhǔn)確,但是對于第三類數(shù)據(jù)�����,而無法區(qū)分�,因此這種情況下,其意義不在于分類的整體正確率����,而在于在一些特殊情況下,可以根據(jù)一些重要的特征屬性值就可以為患者確診�,從而提高效率和準(zhǔn)確率,減少誤診斷的幾率�。
上面是將所有屬性進(jìn)行K-means變換,下面將結(jié)合ReliefF算法,先去掉一部分特征權(quán)重較小的特征屬性后�����,再進(jìn)行K-means處理���。根據(jù)4.2節(jié)中的結(jié)論,下面提取權(quán)重最大的6個(gè)屬性進(jìn)行測試����,分別是:屬性6,屬性 1�����,屬性 8�,屬性 3����,屬性2,屬性 4�。
1.第一類為良性,共281條數(shù)據(jù)��,分類正確率為97.51% ;
2.第二類為惡性�,共211條數(shù)據(jù),分類正確率為 97.16% ;
3.第三類為混合類����,共191條數(shù)據(jù)
因此,對比可以看到,雖然良性的正確率增加了�����,但是檢測出的數(shù)據(jù)減少了��。第三類混合的數(shù)量也增多了�,說明提出了特種屬性較小的屬性,可以更加容易區(qū)分極端的病例數(shù)據(jù),對極端數(shù)據(jù)的檢測更加準(zhǔn)確����。
4.主要的Matlab源代碼
1.ReliefF特征提取算法Matlab主程序
1 %主函數(shù)
2 clear;clc;
3 load('matlab.mat')
4 D=data(:,2:size(data,2));%
5 m =80 ;%抽樣次數(shù)
6 k = 8;
7 N=20;%運(yùn)行次數(shù)
8 for i =1:N
9 W(i,:) = ReliefF (D,m,k) ;
10 end
11 for i = 1:N %將每次計(jì)算的權(quán)重進(jìn)行繪圖,繪圖N次���,看整體效果
12 plot(1:size(W,2),W(i,:));
13 hold on ;
14 end
15 for i = 1:size(W,2) %計(jì)算N次中�,每個(gè)屬性的平均值
16 result(1,i) = sum(W(:,i))/size(W,1) ;
17 end
18 xlabel('屬性編號');
19 ylabel('特征權(quán)重');
20 title('ReliefF算法計(jì)算乳腺癌數(shù)據(jù)的特征權(quán)重');
21 axis([1 10 0 0.3])
22 %------- 繪制每一種的屬性變化趨勢
23 xlabel('計(jì)算次數(shù)');
24 ylabel('特征權(quán)重');
25 name =char('塊厚度','細(xì)胞大小均勻性','細(xì)胞形態(tài)均勻性','邊緣粘附力','單上皮細(xì)胞尺寸','裸核','Bland染色質(zhì)','正常核仁','核分裂');
26 name=cellstr(name);
27
28 for i = 1:size(W,2)
29 figure
30 plot(1:size(W,1),W(:,i));
31 xlabel('計(jì)算次數(shù)') ;
32 ylabel('特征權(quán)重') ;
33 title([char(name(i)) '(屬性' num2Str(i) ')的特征權(quán)重變化']);
34 end
2.ReliefF函數(shù)程序
1 %Relief函數(shù)實(shí)現(xiàn)
2 %D為輸入的訓(xùn)練集合,輸入集合去掉身份信息項(xiàng)目;k為最近鄰樣本個(gè)數(shù)
3 function W = ReliefF (D,m,k)
4 Rows = size(D,1) ;%樣本個(gè)數(shù)
5 Cols = size(D,2) ;%特征熟練,不包括分類列
6 type2 = sum((D(:,Cols)==2))/Rows ;
7 type4 = sum((D(:,Cols)==4))/Rows ;
8 %先將數(shù)據(jù)集分為2類,可以加快計(jì)算速度
9 D1 = zeros(0,Cols) ;%第一類
10 D2 = zeros(0,Cols) ;%第二類
11 for i = 1:Rows
12 if D(i,Cols)==2
13 D1(size(D1,1)+1,:) = D(i,:) ;
14 elseif D(i,Cols)==4
15 D2(size(D2,1)+1,:) = D(i,:) ;
16 end
17 end
18 W =zeros(1,Cols-1) ;%初始化特征權(quán)重��,置0
19 for i = 1 : m %進(jìn)行m次循環(huán)選擇操作
20 %從D中隨機(jī)選擇一個(gè)樣本R
21 [R,Dh,Dm] = GetRandSamples(D,D1,D2,k) ;
22 %更新特征權(quán)重值
23 for j = 1:length(W) %每個(gè)特征累計(jì)一次����,循環(huán)
24 W(1,j)=W(1,j)-sum(Dh(:,j))/(k*m)+sum(Dm(:,j))/(k*m) ;%按照公式更新權(quán)重
25 end
26 end
ReliefF輔助函數(shù),尋找最近的樣本數(shù)K
1 %獲取隨機(jī)R 以及找出鄰近樣本
2 %D:訓(xùn)練集;D1:類別1數(shù)據(jù)集;D2:類別2數(shù)據(jù)集;
3 %Dh:與R同類相鄰的樣本距離;Dm:與R不同類的相鄰樣本距離
4 function [R,Dh,Dm] = GetRandSamples(D,D1,D2,k)
5 %先產(chǎn)生一個(gè)隨機(jī)數(shù)�����,確定選定的樣本R
6 r = ceil(1 + (size(D,1)-1)*rand) ;
7 R=D(r,:); %將第r行選中��,賦值給R
8 d1 = zeros(1,0) ;%先置0,d1是與R的距離�����,是不是同類在下面判斷
9 d2 = zeros(1,0) ;%先置0,d2是與R的距離
10 %D1,D2是先傳入的參數(shù)����,在ReliefF函數(shù)中已經(jīng)分類好了
11 for i =1:size(D1,1) %計(jì)算R與D1的距離
12 d1(1,i) = Distance(R,D1(i,:)) ;
13 end
14 for j = 1:size(D2,1)%計(jì)算R與D2的距離
15 d2(1,j) = Distance(R,D2(j,:)) ;
16 end
17 [v1,L1] = sort(d1) ;%d1排序�,
18 [v2,L2] = sort(d2) ;%d2排序
19 if R(1,size(R,2))==2 %如果R樣本=2��,是良性
20 H = D1(L1(1,2:k+1),:) ; %L1中是與R最近的距離的編號���,賦值給H���。
21 M = D2(L2(1,1:k),:) ; %v2(1,1:k) ;
22 else
23 H = D1(L1(1,1:k),:);
24 M = D2(L2(1,2:k+1),:) ;
25 end
26 %循環(huán)計(jì)算每2個(gè)樣本特征之間的特征距離:(特征1-特征2)/(max-min)
27 for i = 1:size(H,1)
28 for j =1 :size(H,2)
29 Dh(i,j) = abs(H(i,j)-R(1,j))/9 ; % 本文數(shù)據(jù)范圍都是1-10��,所以max-min=9為固定
30 Dm(i,j) = abs(M(i,j)-R(1,j))/9 ;
31 end
32 end
3.K-means算法主程序
1 clc;clear;
2 load('matlab.mat')%加載測試數(shù)據(jù)
3 N0 =1 ; %從多少列開始的數(shù)據(jù)進(jìn)行預(yù)測分類
4 N1 = size(data,1);%所有數(shù)據(jù)的行數(shù)
5 data=data(N0:N1,:);%只選取需要測試的數(shù)據(jù)
6 data1=data(:,[2,3,4,5,6,7,8,9]);% [2,4,7,9] 2:size(data,2)-1
7 opts = statset('Display','final');%控制選項(xiàng)
8 [idx,ctrs,result,D] = kmeans(data1,2,... %data1為要分類的數(shù)據(jù),2為分類的類別數(shù),本文只有2類
9 'Distance','city',... %選擇的距離的計(jì)算方式
10 'Options',opts); % 控制選項(xiàng),參考matlab幫助
11 t=[data(:,size(data,2)),idx(:,1)];%把測試數(shù)據(jù)最后一列�����,也就是分類屬性 和 分類結(jié)果取出來:列 + 列
12 d2 = data(idx==1,11);%提取原始數(shù)據(jù)中屬于第1類的數(shù)據(jù)的最后一列
13 a = sum(d2==2) ;
14 b=a/length(d2) ;
15 totalSum = 0 ;%總的正確率
16 rate1 = 0 ;%第一類的判斷正確率.分類類別中數(shù)據(jù)的正確性
17 rate2 = 0 ;%第二類的判斷正確率.
18 if(b>0.5) %說明第1類屬于良性,則a的值就是良性中判斷正確的個(gè)數(shù)
19 totalSum = totalSum + a ;
20 rate1 = a/length(d2) ;
21 %然后加上惡性中判斷正確的比例
22 totalSum = totalSum + sum(data(idx==2,11)==4) ;
23 rate2 = sum(data(idx==2,11)==4)/length(data(idx==2,11)) ;
24 else %說明第1類屬于惡性
25 totalSum = totalSum + sum(data(idx==1,11)==4) ;
26 totalSum = totalSum + sum(data(idx==2,11)==2) ;
27 rate1 = sum(data(idx==2,11)==2)/length(data(idx==2,11)) ;
28 rate2 = sum(data(idx==1,11)==4)/length(data(idx==1,11)) ;
29 end
30 x1 =1;%第x1個(gè)屬性
31 x2 =1 ;%第x2個(gè)屬性
32 plot(1:sum(idx==1),data1(idx==1,x1),'r.','MarkerSize',12);
33 hold on ;
34 plot(sum(idx==1)+1:sum(idx==1)+sum(idx==2),data1(idx==2,x1),'b.','MarkerSize',12);
35 xlabel('記錄數(shù)');
36 ylabel('屬性值');
37 title('屬性9的值分布');
38 legend('第一類','第二類');
39 axis([0 640 0 10])
40 rate = totalSum/size(t,1) %總的判斷準(zhǔn)確率
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試���,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情;
? 想學(xué)習(xí)CDA考試教材���,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫�,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情;
? 想了解CDA考試含金量���,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330