如何解決機(jī)器學(xué)習(xí)中數(shù)據(jù)不平衡問題
這幾年來��,機(jī)器學(xué)習(xí)和數(shù)據(jù)挖掘非?����;馃?���,它們逐漸為世界帶來實際價值��。與此同時����,越來越多的機(jī)器學(xué)習(xí)算法從學(xué)術(shù)界走向工業(yè)界����,而在這個過程中會有很多困難����。數(shù)據(jù)不平衡問題雖然不是最難的,但絕對是最重要的問題之一���。
一�、數(shù)據(jù)不平衡
在學(xué)術(shù)研究與教學(xué)中����,很多算法都有一個基本假設(shè),那就是數(shù)據(jù)分布是均勻的��。當(dāng)我們把這些算法直接應(yīng)用于實際數(shù)據(jù)時�����,大多數(shù)情況下都無法取得理想的結(jié)果��。因為實際數(shù)據(jù)往往分布得很不均勻���,都會存在“長尾現(xiàn)象”��,也就是所謂的“二八原理”���。下圖是新浪微博交互分布情況:
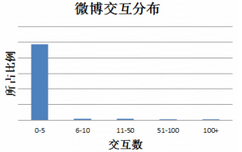
可以看到大部分微博的總互動數(shù)(被轉(zhuǎn)發(fā)、評論與點贊數(shù)量)在0-5之間��,交互數(shù)多的微博(多于100)非常之少���。如果我們?nèi)ヮA(yù)測一條微博交互數(shù)所在檔位�,預(yù)測器只需要把所有微博預(yù)測為第一檔(0-5)就能獲得非常高的準(zhǔn)確率�����,而這樣的預(yù)測器沒有任何價值����。那如何來解決機(jī)器學(xué)習(xí)中數(shù)據(jù)不平衡問題呢?這便是這篇文章要討論的主要內(nèi)容�。
嚴(yán)格地講,任何數(shù)據(jù)集上都有數(shù)據(jù)不平衡現(xiàn)象�,這往往由問題本身決定的,但我們只關(guān)注那些分布差別比較懸殊的��;另外,雖然很多數(shù)據(jù)集都包含多個類別��,但這里著重考慮二分類��,因為解決了二分類中的數(shù)據(jù)不平衡問題后��,推而廣之就能得到多分類情況下的解決方案�����。綜上���,這篇文章主要討論如何解決二分類中正負(fù)樣本差兩個及以上數(shù)量級情況下的數(shù)據(jù)不平衡問題�����。
不平衡程度相同(即正負(fù)樣本比例類似)的兩個問題���,解決的難易程度也可能不同,因為問題難易程度還取決于我們所擁有數(shù)據(jù)有多大���。比如在預(yù)測微博互動數(shù)的問題中,雖然數(shù)據(jù)不平衡�����,但每個檔位的數(shù)據(jù)量都很大——最少的類別也有幾萬個樣本,這樣的問題通常比較容易解決����;而在癌癥診斷的場景中,因為患癌癥的人本來就很少����,所以數(shù)據(jù)不但不平衡,樣本數(shù)還非常少�,這樣的問題就非常棘手。綜上�,可以把問題根據(jù)難度從小到大排個序:大數(shù)據(jù)+分布均衡<大數(shù)據(jù)+分布不均衡<小數(shù)據(jù)+數(shù)據(jù)均衡<小數(shù)據(jù)+數(shù)據(jù)不均衡。對于需要解決的問題�,拿到數(shù)據(jù)后,首先統(tǒng)計可用訓(xùn)練數(shù)據(jù)有多大�,然后再觀察數(shù)據(jù)分布情況。經(jīng)驗表明�����,訓(xùn)練數(shù)據(jù)中每個類別有5000個以上樣本�����,數(shù)據(jù)量是足夠的,正負(fù)樣本差一個數(shù)量級以內(nèi)是可以接受的�����,不太需要考慮數(shù)據(jù)不平衡問題(完全是經(jīng)驗���,沒有理論依據(jù)�����,僅供參考)����。
二�、如何解決
解決這一問題的基本思路是讓正負(fù)樣本在訓(xùn)練過程中擁有相同的話語權(quán),比如利用采樣與加權(quán)等方法����。為了方便起見,我們把數(shù)據(jù)集中樣本較多的那一類稱為“大眾類”�,樣本較少的那一類稱為“小眾類”。
1. 采樣
采樣方法是通過對訓(xùn)練集進(jìn)行處理使其從不平衡的數(shù)據(jù)集變成平衡的數(shù)據(jù)集�����,在大部分情況下會對最終的結(jié)果帶來提升�。
采樣分為上采樣(Oversampling)和下采樣(Undersampling),上采樣是把小種類復(fù)制多份��,下采樣是從大眾類中剔除一些樣本��,或者說只從大眾類中選取部分樣本�。
隨機(jī)采樣最大的優(yōu)點是簡單,但缺點也很明顯����。上采樣后的數(shù)據(jù)集中會反復(fù)出現(xiàn)一些樣本,訓(xùn)練出來的模型會有一定的過擬合���;而下采樣的缺點顯而易見��,那就是最終的訓(xùn)練集丟失了數(shù)據(jù)�,模型只學(xué)到了總體模式的一部分�����。
上采樣會把小眾樣本復(fù)制多份��,一個點會在高維空間中反復(fù)出現(xiàn)�,這會導(dǎo)致一個問題���,那就是運(yùn)氣好就能分對很多點,否則分錯很多點���。為了解決這一問題���,可以在每次生成新數(shù)據(jù)點時加入輕微的隨機(jī)擾動,經(jīng)驗表明這種做法非常有效��。
因為下采樣會丟失信息����,如何減少信息的損失呢?第一種方法叫做EasyEnsemble����,利用模型融合的方法(Ensemble):多次下采樣(放回采樣,這樣產(chǎn)生的訓(xùn)練集才相互獨立)產(chǎn)生多個不同的訓(xùn)練集����,進(jìn)而訓(xùn)練多個不同的分類器,通過組合多個分類器的結(jié)果得到最終的結(jié)果�����。第二種方法叫做BalanceCascade,利用增量訓(xùn)練的思想(Boosting):先通過一次下采樣產(chǎn)生訓(xùn)練集��,訓(xùn)練一個分類器�����,對于那些分類正確的大眾樣本不放回����,然后對這個更小的大眾樣本下采樣產(chǎn)生訓(xùn)練集����,訓(xùn)練第二個分類器,以此類推��,最終組合所有分類器的結(jié)果得到最終結(jié)果����。第三種方法是利用KNN試圖挑選那些最具代表性的大眾樣本,叫做NearMiss�,這類方法計算量很大,感興趣的可以參考“Learning
from Imbalanced Data”這篇綜述的3.2.1節(jié)��。
2. 數(shù)據(jù)合成
數(shù)據(jù)合成方法是利用已有樣本生成更多樣本�����,這類方法在小數(shù)據(jù)場景下有很多成功案例,比如醫(yī)學(xué)圖像分析等�����。
其中最常見的一種方法叫做SMOTE���,它利用小眾樣本在特征空間的相似性來生成新樣本���。對于小眾樣本 xi∈Sminxi∈Smin ,從它屬于小眾類的K近鄰中隨機(jī)選取一個樣本點 ^xix^i �,生成一個新的小眾樣本 xnewxnew : xnew=xi+(^x?xi)×δxnew=xi+(x^?xi)×δ ,其中 δ∈[0,1]δ∈[0,1] 是隨機(jī)數(shù)�����。
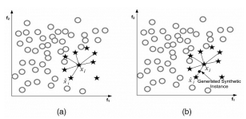
上圖是SMOTE方法在 K=6
近鄰下的示意圖�,黑色方格是生成的新樣本。
SMOTE為每個小眾樣本合成相同數(shù)量的新樣本����,這帶來一些潛在的問題:一方面是增加了類之間重疊的可能性,另一方面是生成一些沒有提供有益信息的樣本。為了解決這個問題���,出現(xiàn)兩種方法:Borderline-SMOTE與ADASYN����。
Borderline-SMOTE的解決思路是尋找那些應(yīng)該為之合成新樣本的小眾樣本��。即為每個小眾樣本計算K近鄰��,只為那些K近鄰中有一半以上大眾樣本的小眾樣本生成新樣本�����。直觀地講��,只為那些周圍大部分是大眾樣本的小眾樣本生成新樣本�,因為這些樣本往往是邊界樣本�。確定了為哪些小眾樣本生成新樣本后再利用SMOTE生成新樣本。
ADASYN的解決思路是根據(jù)數(shù)據(jù)分布情況為不同小眾樣本生成不同數(shù)量的新樣本��。首先根據(jù)最終的平衡程度設(shè)定總共需要生成的新小眾樣本數(shù)量 GG ���,然后為每個小眾樣本 xixi 計算分布比例 ΓiΓi : Γi=Δi/KZΓi=Δi/KZ �����,其中 ΓiΓi 是 xixi K近鄰中大眾樣本的數(shù)量�, ZZ 用來歸一化使得 ∑Γi=1∑Γi=1 ,最后為小眾樣本 xixi 生成新樣本的個數(shù)為 gi=Γi×Ggi=Γi×G ����,確定個數(shù)后再利用SMOTE生成新樣本。
3. 加權(quán)
除了采樣和生成新數(shù)據(jù)等方法����,我們還可以通過加權(quán)的方式來解決數(shù)據(jù)不平衡問題,即對不同類別分錯的代價不同���,如下圖:
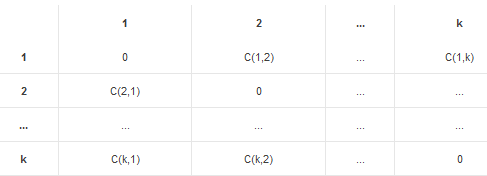
橫向是真實分類情況���,縱向是預(yù)測分類情況,C(i,j)是把真實類別為j的樣本預(yù)測為i時的損失����,我們需要根據(jù)實際情況來設(shè)定它的值。
這種方法的難點在于設(shè)置合理的權(quán)重��,實際應(yīng)用中一般讓各個分類間的加權(quán)損失值近似相等�。當(dāng)然這并不是通用法則,還是需要具體問題具體分析。
4. 一分類
對于正負(fù)樣本極不平衡的場景�,我們可以換一個完全不同的角度來看待問題:把它看做一分類(One
Class Learning)或異常檢測(Novelty
Detection)問題。這類方法的重點不在于捕捉類間的差別�,而是為其中一類進(jìn)行建模,經(jīng)典的工作包括One-class SVM等���。
三��、如何選擇
解決數(shù)據(jù)不平衡問題的方法有很多��,上面只是一些最常用的方法�,而最常用的方法也有這么多種���,如何根據(jù)實際問題選擇合適的方法呢?接下來談?wù)勔恍┪业慕?jīng)驗����。
在正負(fù)樣本都非常之少的情況下,應(yīng)該采用數(shù)據(jù)合成的方式��;在負(fù)樣本足夠多�����,正樣本非常之少且比例及其懸殊的情況下,應(yīng)該考慮一分類方法���;在正負(fù)樣本都足夠多且比例不是特別懸殊的情況下�,應(yīng)該考慮采樣或者加權(quán)的方法�。
采樣和加權(quán)在數(shù)學(xué)上是等價的,但實際應(yīng)用中效果卻有差別��。尤其是采樣了諸如Random Forest等分類方法���,訓(xùn)練過程會對訓(xùn)練集進(jìn)行隨機(jī)采樣����。在這種情況下��,如果計算資源允許上采樣往往要比加權(quán)好一些�����。
另外�,雖然上采樣和下采樣都可以使數(shù)據(jù)集變得平衡,并且在數(shù)據(jù)足夠多的情況下等價�����,但兩者也是有區(qū)別的�。實際應(yīng)用中��,我的經(jīng)驗是如果計算資源足夠且小眾類樣本足夠多的情況下使用上采樣��,否則使用下采樣�,因為上采樣會增加訓(xùn)練集的大小進(jìn)而增加訓(xùn)練時間,同時小的訓(xùn)練集非常容易產(chǎn)生過擬合�����。對于下采樣,如果計算資源相對較多且有良好的并行環(huán)境�����,應(yīng)該選擇Ensemble方法��。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認(rèn)證考試����,點擊>>>
“CDA報名”
了解CDA考試詳情��;
? 想學(xué)習(xí)CDA考試教材����,點擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情;
? 想了解CDA考試含金量���,點擊>>> “CDA含金量” 了解CDA考試詳情�����;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330