R語言之?dāng)?shù)據(jù)管理
數(shù)據(jù)挖掘最重要的一環(huán)就是如何管理你的數(shù)據(jù)���,因?yàn)樵紨?shù)據(jù)一般都不能直接用來進(jìn)行分析�,需要對原始數(shù)據(jù)進(jìn)行增加衍生變量�、數(shù)據(jù)分箱、數(shù)據(jù)標(biāo)準(zhǔn)化處理��;對因子型變量進(jìn)行啞變量處理;數(shù)據(jù)抽樣和類失衡數(shù)據(jù)處理�����。本專題會詳細(xì)介紹以上內(nèi)容的數(shù)據(jù)挖掘技術(shù)及R語言實(shí)現(xiàn)����。
數(shù)據(jù)轉(zhuǎn)換
對于數(shù)據(jù)挖掘分析建模來說,數(shù)據(jù)轉(zhuǎn)換(Transformation)是最常用�����、最重要����,也是最有效的一種數(shù)據(jù)處理技術(shù)。經(jīng)過適當(dāng)?shù)?a href='/map/shujuzhuanhuan/' style='color:#000;font-size:inherit;'>數(shù)據(jù)轉(zhuǎn)換后����,模型的效果常常可以有明顯的提升�����,也正因?yàn)檫@個原因,數(shù)據(jù)轉(zhuǎn)換成了很多數(shù)據(jù)分析師在建模過程中最喜歡使用的一種數(shù)據(jù)處理手段��。另一方面����,在絕大數(shù)數(shù)據(jù)挖掘實(shí)踐中,由于原始數(shù)據(jù)���,在此主要是指區(qū)間型變量(Interval)的分布不光滑(或有噪聲)��,不對稱分布(Skewed
Distributions)����,也使得數(shù)據(jù)轉(zhuǎn)化成為一種必須的技術(shù)手段���。
按照采用的轉(zhuǎn)換邏輯和轉(zhuǎn)換目的的不同���,數(shù)據(jù)轉(zhuǎn)換主要分為以下四大類:
產(chǎn)生衍生變量。
這類轉(zhuǎn)換的目的很直觀���,即通過對原始數(shù)據(jù)進(jìn)行簡單�、適當(dāng)?shù)財?shù)據(jù)公式推導(dǎo)����,產(chǎn)生更有商業(yè)意義的新變量。例如�����,我們收集了最近一周的付費(fèi)人數(shù)和付費(fèi)金額����,此時想統(tǒng)計每日的日均付費(fèi)金額(arpu=revenue/user),此時就可以通過前兩個變量快速實(shí)現(xiàn)�。
> # 創(chuàng)建數(shù)據(jù)集
> w <- data.frame(day = 1:7,
+ revenue = sample(5000:6000,7),
+ user = sample(1000:1500,7))
> w
day revenue user
1 1 5391 1223
2 2 5312 1418
3 3 5057 1343
4 4 5354 1397
5 5 5904 1492
6 6 5064 1113
7 7 5402 1180
> # 增加衍生變量人均付費(fèi)金額(arpu)
> w$arpu <- w$revenue/w$user
> w
day revenue user arpu
1 1 5391 1223 4.408013
2 2 5312 1418 3.746121
3 3 5057 1343 3.765450
4 4 5354 1397 3.832498
5 5 5904 1492 3.957105
6 6 5064 1113 4.549865
7 7 5402 1180 4.577966
從中不難發(fā)現(xiàn),得到這些衍生變量所應(yīng)用到的數(shù)據(jù)公式很簡單�����,但是其商業(yè)意義是明確的�����,而且跟具體的分析背景和分析思路密切相關(guān)����。
衍生變量的產(chǎn)生主要依賴于數(shù)據(jù)分析師的業(yè)務(wù)熟悉程度和對項(xiàng)目思路的掌握程度,如果沒有明確的項(xiàng)目分析思路和對數(shù)據(jù)的透徹理解�����,是無法找到有針對性的衍生變量的。
改善變量分布特征的轉(zhuǎn)換��,這里主要是指不對稱分布所進(jìn)行的轉(zhuǎn)換��。
在數(shù)據(jù)挖掘實(shí)戰(zhàn)中���,有些數(shù)據(jù)是不對稱的��,嚴(yán)重不對稱出現(xiàn)在自變量中常常會干擾模型的擬合���,最終會影響模型的效果和效率。如果通過各種數(shù)學(xué)變換����,使得變量的分布呈現(xiàn)(或者近似)正態(tài)分布,并形成倒鐘形曲線�����,那么模型的擬合常常會有明顯的提升�����,轉(zhuǎn)換后自變量的預(yù)測性能也可能得到改善,最終將會提高模型的效果和效率��。
常見的改善分布的轉(zhuǎn)換措施如下:
取對數(shù)(Log)
開平方根(SquareRoot)
取倒數(shù)(Inverse)
開平方(Square)
取指數(shù)(Exponential)
這邊以取對數(shù)為例進(jìn)行說明�。在R的擴(kuò)展包ggplot2中自帶了一份鉆石數(shù)據(jù)集(diamonds)�����,我們從中抽取1000個樣本最為研究對象����,研究數(shù)據(jù)中變量carat(克拉數(shù))、price(價格)的數(shù)據(jù)分布情況�,并研究兩者之間的關(guān)系,最后利用克拉數(shù)預(yù)測鉆石的價格�。
> library(ggplot2)
> set.seed(1234)
> dsmall <- diamonds[sample(1:nrow(diamonds),1000),] # 數(shù)據(jù)抽樣
> head(dsmall) # 查看數(shù)據(jù)前六行
carat cut color clarity depth table price x y z
6134 0.91 Ideal G SI2 61.6 56 3985 6.24 6.22 3.84
33567 0.43 Premium D SI1 60.1 58 830 4.89 4.93 2.95
32864 0.32 Ideal D VS2 61.5 55 808 4.43 4.45 2.73
33624 0.33 Ideal G SI2 61.7 55 463 4.46 4.48 2.76
46435 0.70 Good H SI1 64.2 58 1771 5.59 5.62 3.60
34536 0.33 Ideal G VVS1 61.8 55 868 4.42 4.45 2.74
> par(mfrow = c(1,2))
> plot(density(dsmall$carat),main = "carat變量的正態(tài)分布曲線") # 繪制carat變量的正態(tài)分布曲線
> plot(density(dsmall$price),main = "price變量的正態(tài)分布曲線") # 繪制price變量的正態(tài)分布曲線
> par(mfrow = c(1,1))
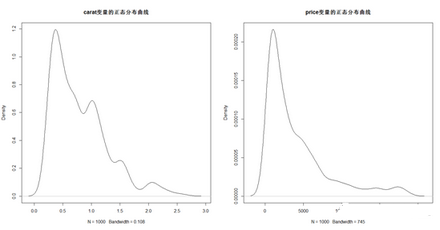
從正態(tài)分布圖可知,變量carat和price均是嚴(yán)重不對稱分布�����。此時我們利用R語言中的log函數(shù)對兩者進(jìn)行對數(shù)轉(zhuǎn)換�����,再次繪制正態(tài)密度圖�����。
> par(mfrow = c(1,2))
> plot(density(log(dsmall$carat)),main = "carat變量取對數(shù)后的正態(tài)分布曲線")
> plot(density(log(dsmall$price)),main = "price變量取對數(shù)后的正態(tài)分布曲線")
> par(mfrow = c(1,1))
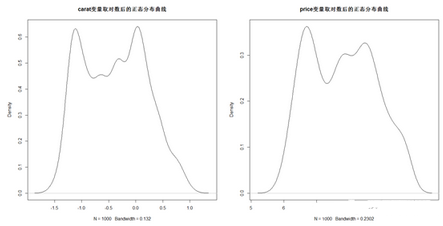
可見,經(jīng)過對數(shù)處理后�,兩者的正態(tài)分布密度曲線就對稱很多。最后�����,讓我們一起來驗(yàn)證對原始數(shù)據(jù)建立線性回歸模型與經(jīng)過對數(shù)變量后再建模的區(qū)別��。
> # 建立線性回歸模型
> fit1 <- lm(dsmall$price~dsmall$carat,data = dsmall) # 對原始變量進(jìn)行建模
> summary(fit1) # 查看模型詳細(xì)結(jié)果
Call:
lm(formula = dsmall$price ~ dsmall$carat, data = dsmall)
Residuals:
Min 1Q Median 3Q Max
-8854.8 -821.9 -42.2 576.0 8234.2
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -2391.74 97.44 -24.55 <2e-16 ***
dsmall$carat 7955.35 104.45 76.16 <2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 1582 on 998 degrees of freedom
Multiple R-squared: 0.8532, Adjusted R-squared: 0.8531
F-statistic: 5801 on 1 and 998 DF, p-value: < 2.2e-16
> fit2 <-lm(log(dsmall$price)~log(dsmall$carat),data=dsmall) # 對兩者進(jìn)行曲對數(shù)后再建模
> summary(fit2) # 查看模型結(jié)果
Call:
lm(formula = log(dsmall$price) ~ log(dsmall$carat), data = dsmall)
Residuals:
Min 1Q Median 3Q Max
-1.07065 -0.16438 -0.01159 0.16476 0.83140
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 8.451358 0.009937 850.5 <2e-16 ***
log(dsmall$carat) 1.686009 0.014135 119.3 <2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.2608 on 998 degrees of freedom
Multiple R-squared: 0.9345, Adjusted R-squared: 0.9344
F-statistic: 1.423e+04 on 1 and 998 DF, p-value: < 2.2e-16
通過對比MultipleR-squared發(fā)現(xiàn)�,模型1的R平方是0.8532,模型2的R平方是0.9345��,R平方的值是越接近1說明模型擬合的越好�����,所以經(jīng)過對數(shù)處理后建立的模型2優(yōu)于模型1�。我們也可以通過在散點(diǎn)圖繪制擬合曲線的可視化方式進(jìn)行查看。
> # 在散點(diǎn)圖中 繪制擬合曲線
> par(mfrow=c(1,2))
> plot(dsmall$carat,dsmall$price,
+ main = "未處理的散點(diǎn)圖及擬合直線")
> abline(fit1,col="red",lwd=2)
> plot(log(dsmall$carat),log(dsmall$price),
+ main = "取對數(shù)后的散點(diǎn)圖及擬合直線")
> abline(fit2,col="red",lwd=2)
> par(mfrow=c(1,1))
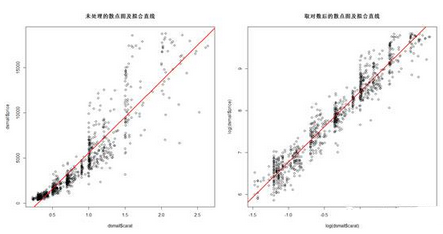
可見����,取對數(shù)后繪制的散點(diǎn)更集中在紅色的線性回歸線上。
區(qū)間型變量的分箱轉(zhuǎn)換�����。
分箱轉(zhuǎn)換(Binning)就是把區(qū)間型變量 (Interval)轉(zhuǎn)換成次序型變量(Ordinal),其轉(zhuǎn)換的目的如下:
降低變量(主要是指自變量)的復(fù)雜性�����,簡化數(shù)據(jù)���。比如,有一組用戶的年齡����,原始數(shù)據(jù)是區(qū)間型的,從10~60歲�,每1歲都是1個年齡段;如果通過分箱轉(zhuǎn)換���,每10歲構(gòu)成1個年齡組�����,就可以有效簡化數(shù)據(jù)�����。R語言中有cut函數(shù)可以輕易實(shí)現(xiàn)數(shù)據(jù)分箱操作����。
> age <- sample(10:60,15)
> age <- sample(10:60,15) # 創(chuàng)建年齡變量
> age
[1] 26 41 59 33 50 16 28 18 52 30 25 44 37 23 47
> age_cut <- cut(age,breaks = seq(10,60,10))
> age_cut
[1] (20,30] (40,50] (50,60] (30,40] (40,50] (10,20] (20,30] (10,20] (50,60]
[10] (20,30] (20,30] (40,50] (30,40] (20,30] (40,50]
Levels: (10,20] (20,30] (30,40] (40,50] (50,60]
> table(age_cut) # 查看不同年齡段的人數(shù)
age_cut
(10,20] (20,30] (30,40] (40,50] (50,60]
2 5 2 4 2
可見,利用cut函數(shù)分箱得到的區(qū)間段是左開右閉的����,我們通過table函數(shù)查看不同區(qū)間段的人數(shù),發(fā)現(xiàn)有5人在20到30歲之間�����。
針對區(qū)間型變量進(jìn)行的標(biāo)準(zhǔn)化操作�����。
數(shù)據(jù)的標(biāo)準(zhǔn)化(Normalization)轉(zhuǎn)換也是數(shù)據(jù)挖掘中常見的數(shù)據(jù)轉(zhuǎn)換措施之一���,數(shù)據(jù)標(biāo)準(zhǔn)轉(zhuǎn)換的目的是將數(shù)據(jù)按照比例進(jìn)行縮放���,使之落入一個小的區(qū)間范圍之內(nèi),使得不同的變量經(jīng)過標(biāo)準(zhǔn)化處理后可以有平等分析和比較的基礎(chǔ)��。
最簡單的數(shù)據(jù)標(biāo)準(zhǔn)化轉(zhuǎn)換是Min-Max標(biāo)準(zhǔn)化,也叫離差標(biāo)準(zhǔn)化���,是對原始數(shù)據(jù)進(jìn)行線性變換�����,使得結(jié)果在[0,1]區(qū)間�����,其轉(zhuǎn)換公式如下:
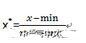
其中���,max為樣本數(shù)據(jù)的最大值��,min為樣本數(shù)據(jù)的最小值��。
在R中���,我們可以利用max函數(shù)和min函數(shù)非常輕易地構(gòu)建一個Normalization函數(shù)����,實(shí)現(xiàn)Min-Max標(biāo)準(zhǔn)化過程��。
> dat <- sample(1:20,10) # 從1到20中有放回隨機(jī)抽取10個
> normalization <- function(x) {
+ (x-min(x))/(max(x)-min(x))
+ } # 構(gòu)建Min-Max標(biāo)準(zhǔn)化的自定義函數(shù)
> dat # 原始數(shù)據(jù)
[1] 19 5 8 13 15 18 16 1 3 9
> normalization(dat) # 經(jīng)過Min-Max標(biāo)準(zhǔn)化的 數(shù)據(jù)
[1] 1.0000000 0.2222222 0.3888889 0.6666667 0.7777778 0.9444444 0.8333333
[8] 0.0000000 0.1111111 0.4444444
另一種常用的標(biāo)準(zhǔn)化處理是零-均值標(biāo)準(zhǔn)化,即把數(shù)據(jù)處理稱符合標(biāo)準(zhǔn)正態(tài)分布�����。也就是均值為0����,標(biāo)準(zhǔn)差為1,轉(zhuǎn)換公式如下:
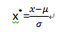
其中�����,μ為所有樣本數(shù)據(jù)的均值��,σ為所有樣本數(shù)據(jù)的標(biāo)準(zhǔn)差���。
在R中���,用scale( )函數(shù)得到Z-Score標(biāo)準(zhǔn)化。其表達(dá)形式為:scale(x, center = TRUE, scale = TRUE)����。
總體來說,數(shù)據(jù)變換的方式多種多樣�,操作起來簡單、靈活、方便���,在 實(shí)踐應(yīng)用中的價值也是比較明顯的�����。
2. 數(shù)據(jù)抽樣
“抽樣”對于數(shù)據(jù)分析和挖掘來說是一種常見的前期數(shù)據(jù)處理技術(shù)和階段�,之所以要采取抽樣,主要原因在于如果數(shù)據(jù)全集的規(guī)模太大�����,針對數(shù)據(jù)全集進(jìn)行分析運(yùn)算不但會消耗更多的運(yùn)算資源��,還會顯著增加運(yùn)算分析的時間�,甚至太大的數(shù)據(jù)量有時候會導(dǎo)致分析挖掘軟件運(yùn)行時的崩潰�����。而采用了抽樣措施��,就可以顯著降低這些負(fù)面的影響�����;另一個常見的需要通過抽樣來解決的場景就是:我們需要將原始數(shù)據(jù)進(jìn)行分區(qū),其中一部分作為訓(xùn)練集��,用來訓(xùn)練模型�,剩下的部分作為測試集,用來對訓(xùn)練好的模型進(jìn)行效果評估��。
R中的sample( )函數(shù)可以實(shí)現(xiàn)數(shù)據(jù)的隨機(jī)抽樣��?��;颈磉_(dá)形式為:
sample(x, size, replace = FALSE, prob = NULL)
其中x是數(shù)值型向量�,size是抽樣個數(shù)��,replace表示是否有放回抽樣�����,默認(rèn)FALSE是無放回抽樣��,TURE是有放回抽樣��。
> # sample小例子
> set.seed(1234)
> # 創(chuàng)建對象x�����,有1~10組成
> x <- seq(1,10);x
[1] 1 2 3 4 5 6 7 8 9 10
> # 利用sample函數(shù)對x進(jìn)行無放回抽樣
> a <- sample(x,8,replace=FALSE);a
[1] 2 6 5 8 9 4 1 7
> # 利用sample函數(shù)對x進(jìn)行有放回抽樣
> b <- sample(x,8,replace=TRUE);b
[1] 7 6 7 6 3 10 3 9
> # 當(dāng)size大于x的長度
> (c <- sample(x,15,replace = F))
Error in sample.int(length(x), size, replace, prob) :
cannot take a sample larger than the population when 'replace = FALSE'
> (c <- sample(x,15,replace = T))
[1] 3 3 2 3 4 4 2 1 3 9 6 10 9 1 5
可見,b中抽取的元素有重復(fù)值�。如果我們要抽取的長度大于x的長度,需要將replace參數(shù)設(shè)置為T(有放回抽樣)��。
有時候����,我們想根據(jù)某一個變量對數(shù)據(jù)進(jìn)行等比例抽樣(即抽樣后的數(shù)據(jù)子集中的該變量各因子水平占比與原來相同),雖然我們利用sample函數(shù)也可以構(gòu)建�����,但是這里給大家介紹caret擴(kuò)展包中的createDataPartition函數(shù)�,可以快速實(shí)現(xiàn)數(shù)據(jù)按照因子變量的類別進(jìn)行快速等比例抽樣。其函數(shù)基本表達(dá)形式為:
createDataPartition(y,times = 1,p = 0.5,list = TRUE,groups = min(5, length(y)))
其中y是一個向量����,times表示需要進(jìn)行抽樣的次數(shù),p表示需要從數(shù)據(jù)中抽取的樣本比例�����,list表示結(jié)果是否是list形式�����,默認(rèn)為TRUE�,groups表示果輸出變量為數(shù)值型數(shù)據(jù),則默認(rèn)按分位數(shù)分組進(jìn)行取樣���。
以鳶尾花數(shù)據(jù)集為例�����,我們想按照物種分類變量進(jìn)行等比例隨機(jī)抽取其中10%的樣本進(jìn)行研究�。
> # 載入caret包����,如果本地未安裝就在線安裝caret包
> if(!require(caret)) install.packages("caret")
載入需要的程輯包:caret
載入需要的程輯包:lattice
載入需要的程輯包:ggplot2
Warning message:
程輯包‘ggplot2’是用R版本3.3.3 來建造的
> # 提取下標(biāo)集
> splitindex <- createDataPartition(iris$Species,times=1,p=0.1,list=FALSE)
> iris_subset <- iris[splitindex,]
> prop.table(table(iris$Species)) # 查看原來數(shù)據(jù)集Species變量各因子占比
setosa versicolor virginica
0.3333333 0.3333333 0.3333333
> prop.table(table(iris_subset$Species))# 查看子集中Species變量各因子占比
setosa versicolor virginica
0.3333333 0.3333333 0.3333333
可見,抽樣后的子集中Species中各類別的占比與原來數(shù)據(jù)集的相同�。
3. 類失衡數(shù)據(jù)處理
另外一個常見的需要通過抽樣來解決的場景就是:在很多小概率事件、稀有事件的預(yù)測建模過程中����,比如信用卡欺詐事件,在整個信用卡用戶中��,屬于惡意欺詐的用戶只占0.2%甚至更少�,如果按照原始的數(shù)據(jù)全集、原始的稀有占比來進(jìn)行分析挖掘����,0.2%的稀有事件是很難通過分析挖掘得到有意義的預(yù)測和結(jié)論的��,所有對此類稀有事件的分析建模�����,通常會采取抽樣的措施���,即認(rèn)為增加樣本中“稀有事件”的濃度和在樣本中的占比。對抽樣后得到的分析樣本進(jìn)行分析挖掘���,可以比較容易地發(fā)現(xiàn)稀有時間與分析變量之間的價值�����,有意義的一些關(guān)聯(lián)性和邏輯性���。
克服類失衡問題常用的技術(shù)有以下兩種:
偏置學(xué)習(xí)過程的方法,它應(yīng)用特定的對少數(shù)類更敏感的評價指標(biāo)����。
用抽樣方法來操作訓(xùn)練數(shù)據(jù),從而改變類的分布���。
有多種抽樣方法用于改變數(shù)據(jù)集中類的失衡����,常用的有以下兩種:
欠采樣法�,它從多數(shù)類中選擇一小部分案例,并把它們和少數(shù)類個案一起構(gòu)成一個有更加平衡的類分布的數(shù)據(jù)集�。
過采樣法,它采用另外的工作模式���,使用某些進(jìn)程來復(fù)制少數(shù)類個案���。
在R中,DMwR包中的SMOTE(
)函數(shù)可以實(shí)現(xiàn)SMOTE方法�����。主要參數(shù)有如下三個:perc.over:過采樣時�����,生成少數(shù)類的樣本個數(shù);k:過采樣中使用K近鄰算法生成少數(shù)類樣本時的K值��,默認(rèn)是5��;perc.under:欠采樣時,對應(yīng)每個生成的少數(shù)類樣本����,選擇原始數(shù)據(jù)多數(shù)類樣本的個數(shù)。例如���,perc.over=500表示對原始數(shù)據(jù)集中的每個少數(shù)樣本�����,都將生成5個新的少數(shù)樣本����;perc.under=80表示從原始數(shù)據(jù)集中選擇的多數(shù)類的樣本是新生的數(shù)據(jù)集中少數(shù)樣本的80%�����。
> # 加載DMwR包
> if(!require(DMwR)) install.packages("DMwR")
載入需要的程輯包:DMwR
載入需要的程輯包:lattice
載入需要的程輯包:grid
> dat <- iris[, c(1, 2, 5)]
> dat$Species <- factor(ifelse(dat$Species == "setosa","rare","common"))
> table(dat$Species)
common rare
100 50
> # 進(jìn)行類失衡處理
> # perc.over=600:表示少數(shù)樣本數(shù)=50+50*600%=350
> # perc.under=100:表示多數(shù)樣本數(shù)(新增少數(shù)樣本數(shù)*100%=300*100%=300)
> newData <- SMOTE(Species ~ ., dat, perc.over = 600,perc.under=100)
> table(newData$Species)
common rare
300 350
> # perc.over=100:表示少數(shù)樣本數(shù)=50+50*100%=100
> # perc.under=200:表示多數(shù)樣本數(shù)(新增少數(shù)樣本數(shù)*200%=50*200%=100)
> newData <- SMOTE(Species ~ ., dat, perc.over = 100,perc.under=200)
> table(newData$Species)
common rare
100 100
4. 數(shù)據(jù)啞變量處理
虛擬變量 ( Dummy Variables) 又稱虛設(shè)變量��、名義變量或啞變量�����,用以反映質(zhì)的屬性的一個人工變量,是量化了的自變量�,通常取值為0或1。引入啞變量可使線形回歸模型變得更復(fù)雜��,但對問題描述更簡明�����,一個方程能達(dá)到兩個方程的作用�,而且接近現(xiàn)實(shí)��。
舉一個例子�,假如變量“性別”的取值為:男性、女性����。我們可以增加2個啞變量來代替“性別”這個變量,分別為性別.男性(1=男性/0=女性)���、性別.女性(1=女性/0=男性)��。
caret擴(kuò)展包中的dummyVars(
)函數(shù)是專門用來處理變量啞變量處理的函數(shù)�����,其表達(dá)形式為:dummyVars(formula,data, sep = ".",
levelsOnly = FALSE, fullRank = FALSE,
...)���。其中��,formula表示模型公式�����,data是需要處理的數(shù)據(jù)集����,sep表示列名和因子水平間的連接符號��,levelsOnly默認(rèn)是FALSE��,當(dāng)為TRUE時表示僅用因子水平表示新列名�,fullRank默認(rèn)是FALSE,當(dāng)為TRUE時表示進(jìn)行虛擬變量處理后不需要出現(xiàn)代表相同意思的兩列�����。
假如有一份customers數(shù)據(jù)集����,包括id����、gender����、mood和outcome變量,其中g(shù)ender和mood都是因子型變量��,我們需要將它們進(jìn)行啞變量處理�����。
> customers <- data.frame(
+ id=c(10,20,30,40,50),
+ gender=c('male','female','female','male','female'),
+ mood=c('happy','sad','happy','sad','happy'),
+ outcome=c(1,1,0,0,0))
> customers
id gender mood outcome
1 10 male happy 1
2 20 female sad 1
3 30 female happy 0
4 40 male sad 0
5 50 female happy 0
> library(caret)
載入需要的程輯包:ggplot2
Warning message:
程輯包‘ggplot2’是用R版本3.3.3 來建造的
> # 啞變量處理
> dmy <- dummyVars(" ~ .", data = customers)
> trsf <- data.frame(predict(dmy, newdata = customers))
> print(trsf)
id gender.female gender.male mood.happy mood.sad outcome
1 10 0 1 1 0 1
2 20 1 0 0 1 1
3 30 1 0 1 0 0
4 40 0 1 0 1 0
5 50 1 0 1 0 0
經(jīng)過啞變量處理后��,原來的變量gender變成兩列g(shù)ender.female和gender.male���,變量mood變成mood.happy和mood.sad兩列,新生成的列里面的內(nèi)容均是0/1�,已經(jīng)幫我們做了歸一化處理。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認(rèn)證考試��,點(diǎn)擊>>>
“CDA報名”
了解CDA考試詳情�����;
? 想學(xué)習(xí)CDA考試教材,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫�,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情;
? 想了解CDA考試含金量��,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330