R語言的小個性
這篇文章用來記錄我在學(xué)習(xí)使用R語言中遇到的一些區(qū)別于其他程序語言的小問題,以及一些解決方案���。會持續(xù)記錄下去。
1. 除法
R語言的除法運算符與其他常見語言一致:/
> 8/5
[1] 1.6
但是取余運算符為:%%
> 8%%5
[1] 3
除法運算取整除數(shù):%/%
> 8%/%5
[1] 1
除法四舍五入:round()
round()后面再帶一個參數(shù)表明保留到第幾位(為正數(shù)時是指保留幾位小數(shù)���,為負(fù)數(shù)時是指四舍五入到第幾位)
> round(8/5)
[1] 2
> round(3.141592653,2)
[1] 3.14
> round(3.141592653*100000,-2)
[1] 314200
2. list和data.frame的區(qū)別
list和data.frame是R中處理表格數(shù)據(jù)常見的兩種格式�,另外還有matrix���。
先說matrix���,它必須保證所有的數(shù)據(jù)都是同一類型的。
> b <-matrix(c(1,1,1, 2,2,3, 1,3,4, 2,1,4), ncol=3, byrow=T)
> b
[,1][,2] [,3]
[1,] 1 1 1
[2,] 2 2 3
[3,] 1 3 4
[4,] 2 1 4
> a <- matrix(c(1,1,"wo",2,2,3, 1,3,4, 2,1,4), ncol=3, byrow=T)
> a
[,1][,2] [,3]
[1,] "1" "1" "wo"
[2,] "2" "2" "3"
[3,] "1" "3" "4"
[4,] "2" "1" "4"
> mode(a)
[1] "character"
> mode(b)
[1] "numeric"
可以看到a跟b的差異就是a中有個字符類型的數(shù)據(jù)“wo”�����,但是打印出來后����,其他數(shù)值類型數(shù)據(jù)也被轉(zhuǎn)換為了字符類型�����。
現(xiàn)在來看list和data.frame的差異��,它們都可以包含不同類型的數(shù)據(jù)但是也有些差異����。
差異1:部分?jǐn)?shù)據(jù)查看及展示方式不同�。list按列展示數(shù)據(jù),data.frame按行展示���。
> list <-list(a=c("hai","tian","xiang","jie","de"),b=c("di","fang","jiu","shi","wo"),c=c("qian"
,"gua","de","gu","xiang"))
> list
$a
[1] "hai" "tian" "xiang" "jie" "de"
$b
[1] "di" "fang" "jiu" "shi" "wo"
$c
[1] "qian" "gua" "de" "gu" "xiang"
> dataframe
a b c
1 hai di qian
2 tianfang gua
3 xiang jiu de
4 jie shi gu
5 de wo xiang
> head(list,n=1)
$a
[1] "hai" "tian" "xiang" "jie" "de"
> head(dataframe,n=1)
a b c
1 hai di qian
差異2:查看列名����,對于list來說應(yīng)該是查看行名(我的說法)是用names()����,對于dataframe來說則是查看列名用colnames(),它還有查看行名rownames()����,沒有定義時,默認(rèn)為1,2,3,4……序列。
> names(list)
[1] "a" "b" "c"
> colnames(dataframe)
[1] "a" "b" "c"
> rownames(dataframe)
[1] "1" "2" "3""4" "5"
差異3:list可包含不同長度數(shù)據(jù)��,dataframe必須每列包含相同長度數(shù)據(jù)��,在list每行數(shù)據(jù)長度相同時�����,就可以使用as.data.frame()方法轉(zhuǎn)換為data.frame類型���。
> list2 <-list(a=1:5,b=1:4)
> list2
$a
[1] 1 2 3 4 5
$b
[1] 1 2 3 4
> dataframe2<- as.data.frame(list2)
Error in data.frame(a = 1:5, b =1:4, check.names = TRUE, stringsAsFactors = TRUE) :
參數(shù)值意味著不同的行數(shù): 5, 4
> list2 <-list(a=1:5,b=6:10)
> list2
$a
[1] 1 2 3 4 5
$b
[1] 6 7 8 9 10
> dataframe2<- as.data.frame(list2)
> dataframe2
a b
1 1 6
2 2 7
3 3 8
4 4 9
5 5 10
差異4:數(shù)據(jù)引用方式不同�。都可以用$引用符號�,但是[]引用和[[]]引用方式上有差異。
> list$a
[1] "hai" "tian" "xiang" "jie" "de"
> dataframe$a
[1] hai tian xiang jie de
Levels: de hai jie tian xiang
> list[1]
$a
[1] "hai" "tian" "xiang" "jie" "de"
> dataframe[1]
a
1 hai
2 tian
3 xiang
4 jie
5 de
> list[[1]]
[1] "hai" "tian" "xiang" "jie" "de"
> dataframe[[1]]
[1] hai tian xiang jie de
Levels: de hai jie tian xiang
> list[[2]][1]
[1] "di"
> dataframe[[2]][1]
[1] di
Levels: di fang jiu shi wo
> list[2,1]
Error in list[2, 1] : incorrectnumber of dimensions
> dataframe[2,1]
[1] tian
Levels: de hai jie tian xiang
差異5:data.frame有一個factor因子��,在差異四中��,查看dataframe的某一列或者某一項數(shù)據(jù)時����,數(shù)據(jù)下面會有Levels的內(nèi)容,這個就是這一列的因子����。相當(dāng)于這一列的取值范圍,有哪些唯一值��。后面會講到factor因子的來歷以及作用���,這里就不細(xì)說了�����。
3. 刪除某一行或者某一列的數(shù)據(jù)��。
對list和dataframe都適用���。刪除行可以直接引用這一行并賦值為NULL����,或者用-操作符號���,具體實現(xiàn)過程如下示。
> list$a <-NULL
> list
$b
[1] "di" "fang" "jiu" "shi" "wo"
$c
[1] "qian" "gua" "de" "gu" "xiang"
> list[-1]
$b
[1] "di" "fang" "jiu" "shi" "wo"
$c
[1] "qian" "gua" "de" "gu" "xiang"
> list$a
[1] "hai" "tian" "xiang" "jie" "de"
> list$a[-1]
[1] "tian" "xiang" "jie" "de"
> list[-1,]
Error in list[-1, ] : incorrectnumber of dimensions
> list[,-1]
Error in list[, -1] : incorrectnumber of dimensions
> dataframe$a<- NULL
> dataframe
b c
1 di qian
2 fang gua
3 jiu de
4 shi gu
5 woxiang
> dataframe<- as.data.frame(list)
> dataframe[-1,]
a b c
2 tianfang gua
3 xiang jiu de
4 jie shi gu
5 de wo xiang
> dataframe <- as.data.frame(list)
> dataframe[,-1]
b c
1 di qian
2 fang gua
3 jiu de
4 shi gu
5 woxiang
> dataframe$b
[1] di fang jiu shi wo
Levels: di fang jiu shi wo
> dataframe$b[-2]
[1] di jiu shi wo
Levels: di fang jiu shi wo
Matrix也可用類似的操作來刪除某行某列的數(shù)據(jù)����,還可以一次刪除多個行多列或者多個值。
> dataframe$c
[1] qian gua de gu xiang
Levels: de gu gua qian xiang
> dataframe$c[c(-1,-3,-5)]
[1] gua gu
Levels: de gu gua qian xiang
4. 讀取數(shù)據(jù)�����。
主要是為了講read.table()和read.csv()方法的一些小細(xì)節(jié)���。數(shù)據(jù)讀入后都被存為data.frame的類型����。
編碼:read.csv()默認(rèn)讀取中文的格式是gbk格式的,無法設(shè)置���。如果你的讀入文件中文編碼格式是UTF-8格式�,使用read.csv就會出現(xiàn)亂碼�����。但是read.table()方法默認(rèn)讀取UTF-8格式中文�,并且包含encoding參數(shù),可以設(shè)置讀取數(shù)據(jù)的編碼格式�。
表頭:read.csv()默認(rèn)是含有表頭的也就是header=T,read.table()默認(rèn)沒有表頭header=F����。
因子:read.csv()和read.table()兩個方法都有stringsAsFactors參數(shù),默認(rèn)為TRUE��。如果你不設(shè)置的話���,數(shù)據(jù)讀入時�,每一列字符型的數(shù)據(jù)都按因子方式存儲。如下面例子����,fruit列被轉(zhuǎn)換成了因子,數(shù)據(jù)被轉(zhuǎn)換成了1,1,3,4,2����,這幾個數(shù)值1-4按順序分別對應(yīng)著Levels:蘋果葡萄
香蕉 柚子。但是我們查看這一列數(shù)據(jù)時���,顯示的還是字符型數(shù)據(jù)����。
> test
fruitprice
1 蘋果 5.98
2 蘋果 3.50
3 香蕉 4.50
4 柚子 4.80
5 葡萄 8.70
> test$fruit
[1]蘋果蘋果香蕉柚子葡萄
Levels:蘋果葡萄香蕉柚子
從clipboard上讀入數(shù)據(jù):見上一個列子中��,我們能直接從clipboard上讀取數(shù)據(jù)�,先在Excel上選中需要讀入的數(shù)據(jù)區(qū)域,右鍵復(fù)制�,再執(zhí)行read.table("clipboard")語句即可����。
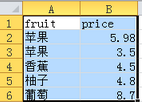
> test <-read.table("clipboard",header=T)
> test
fruitprice
1 蘋果 5.98
2 蘋果 3.50
3 香蕉 4.50
4 柚子 4.80
5 葡萄 8.70
5. 兩表合并的方法
這里是兩個表類似MySQL中join的方法——merge(),默認(rèn)根據(jù)兩個表相同列名相交��。方法的介紹見鏈接:http://my.oschina.net/u/1791586/blog/337054,里面有很詳細(xì)的方法說明���。想說明的是參數(shù)all/x.all/y.all��,這三個參數(shù)取值T/F��,用來定義是否取兩個數(shù)據(jù)框x或者y的所有列�����。效果分別類似join的全連接�,左連接���,右連接����。就不另外舉例子了��,參考鏈接里有很好的例子����。
6. 查看數(shù)據(jù)。
View()可以查看list��、vector、dataframe數(shù)據(jù)��,但是在Rstudio中�,用View()查看時會有中文亂碼。不過mac和Linux平臺上不存在這個問題�,只用Windows平臺上才有,好像沒看到有什么設(shè)置Rstudio的方式可以避免這個的中文亂碼����。R中不存在亂碼的問題。
fix()也可以查看list�、vector、dataframe數(shù)據(jù)����。
區(qū)別在于fix()方法可以查看列所包含的字段數(shù)不同的list的內(nèi)容。View()只能查看整齊的數(shù)據(jù)�,就是行列數(shù)都相同時的數(shù)據(jù)。另外fix()方法是查看數(shù)據(jù)�,打開數(shù)據(jù)編輯框,并能夠在其中修改數(shù)據(jù)�。View()方法只是單純的查看數(shù)據(jù)。
> test <-list(a=c("a","b","c","d"),b=1:4)
> View(test)
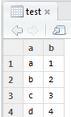
> fix(test)
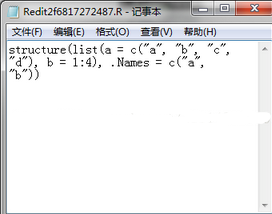
> fix(dataframe)
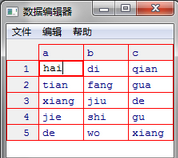
7. R語言的數(shù)據(jù)類型查看mode()/class()/typeof()
沒有找到一個很細(xì)致的說明����,只能根據(jù)我自己的大概理解來看,可能會有誤�����,歡迎指正��。這三個函數(shù)都是能夠查看數(shù)據(jù)類型的函數(shù)���。但是有些小細(xì)節(jié)的差異�����。
R語言中����,所有的數(shù)據(jù)��、對象�、方法、語句都可以查看mode()����,主要的mode類型有:complex、raw�、character��、list�、expression���、name�����、symbol�、function����,mode可以說是大的類型。
所有對象都有typeof屬性和class屬性�,但是相比class而言,typeof更細(xì)致��。
>x <- c(1,2,3,4,5)
>mode(x)
[1]"numeric"
> class(x)
[1]"numeric"
> typeof(x)
[1] "double"
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認(rèn)證考試����,點擊>>>
“CDA報名”
了解CDA考試詳情;
? 想學(xué)習(xí)CDA考試教材�����,點擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫���,點擊>>> “CDA題庫” 了解CDA考試詳情;
? 想了解CDA考試含金量���,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330