SPSS教程:做多重線性回歸,方差不齊怎么辦
一��、殘差方差齊性判斷
1. 殘差方差齊性
回顧一下前面介紹過的殘差方差齊性,即殘差ei的大小不隨預(yù)測值水平的變化而變化�����。我們在進(jìn)行殘差分析時(shí)�����,可以通過繪制標(biāo)準(zhǔn)化殘差和標(biāo)準(zhǔn)化預(yù)測值的散點(diǎn)圖來進(jìn)行判斷��。若殘差滿足方差齊性��,則標(biāo)準(zhǔn)化殘差的散點(diǎn)會在一定區(qū)域內(nèi)���,圍繞標(biāo)準(zhǔn)化殘差ei=0這條直線的上下兩側(cè)均勻分布����,不隨標(biāo)準(zhǔn)化預(yù)測值的變化而變化��,如圖1所示�����。
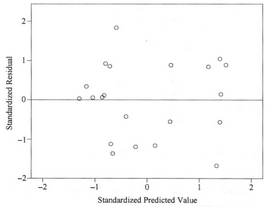
圖1. 標(biāo)準(zhǔn)化殘差散點(diǎn)圖(方差齊性)
2. 殘差方差不齊
但有時(shí)殘差不滿足方差齊性的假設(shè)����,其標(biāo)準(zhǔn)化殘差散點(diǎn)圖顯示,殘差的變異程度隨著變量取值水平的變化而發(fā)生變化����,如圖2(a)顯示標(biāo)準(zhǔn)化殘差的分布隨變量取值的增大而呈現(xiàn)擴(kuò)散趨勢,圖2(b)顯示標(biāo)準(zhǔn)化殘差的分布隨變量取值的增大而呈現(xiàn)收斂趨勢���,說明殘差不滿足方差齊性的條件��。
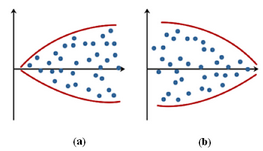
圖2. 標(biāo)準(zhǔn)化殘差散點(diǎn)圖(方差不齊)
二����、加權(quán)最小二乘法
在多重線性回歸模型中,我們采用的是普通最小二乘法(Ordinary Least Square��,OLS)來對參數(shù)進(jìn)行估計(jì)���,即要求每個(gè)觀測點(diǎn)的實(shí)際值與預(yù)測值之間的殘差平方和最小�,對于模型中的每個(gè)觀測點(diǎn)是同等看待的�,殘差滿足方差齊性的假設(shè)。
但是在有些研究問題中���,例如調(diào)查某種疾病的發(fā)病率��,以地區(qū)為觀測單位,很顯然地區(qū)人數(shù)越多�,所得到的率就越穩(wěn)定,變異程度越小�,而地區(qū)人數(shù)越少,所得到的率的變異就越大�����。在這種情況下��,因變量的變異程度會隨著自身數(shù)值或其他變量的變化而變化���,殘差不滿足方差齊性的條件�����。此時(shí)如果繼續(xù)采用OLS方法進(jìn)行模型估計(jì)�,則擬合結(jié)果就會受到變異程度較大的數(shù)據(jù)的影響,在這種情況下構(gòu)建的回歸模型就會發(fā)生偏差�,預(yù)測精度降低,甚至預(yù)測功能失效����。
為了解決這一問題,我們可以采用加權(quán)最小二乘法(Weighted Least Squares����,WLS)的方法來進(jìn)行模型估計(jì),即在模型擬合時(shí)�,根據(jù)數(shù)據(jù)變異程度的大小賦予不同的權(quán)重,對于變異程度較小��、測量更精確的數(shù)據(jù)賦予較大的權(quán)重��,對于變異程度較大����、測量不穩(wěn)定的數(shù)據(jù)賦予較小的權(quán)重�,從而使得加權(quán)后回歸直線的殘差平方和最小�����,保證擬合的模型具有更好的預(yù)測價(jià)值�。
三、SPSS操作
1. 研究問題
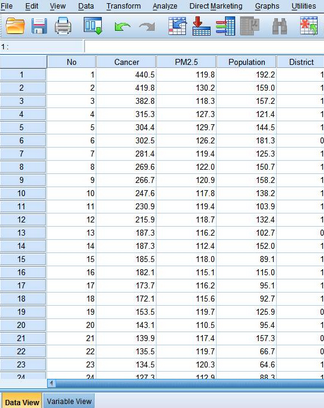
某研究人員擬研究PM2.5濃度與癌癥發(fā)病率之間的關(guān)聯(lián)性�����,以地區(qū)為觀測單位����,收集了40個(gè)地區(qū)的癌癥發(fā)病率(/10萬),PM2.5年平均濃度(μg/m3)�,人口數(shù)量(萬),地區(qū)來源(0=農(nóng)村���,1=城市)等信息。(注:數(shù)據(jù)為模擬數(shù)據(jù)��,不代表真實(shí)情況)
2. 判斷殘差是否滿足方差齊性
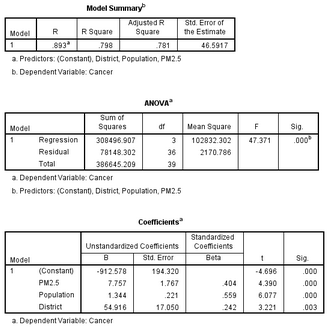
參考多重線性回歸的SPSS操作步驟��,結(jié)果顯示采用普通最小二乘法方法擬合的線性回歸模型具有統(tǒng)計(jì)學(xué)意義(P<0.001),決定系數(shù)R Square為0.798��,PM2.5平均濃度��、不同地區(qū)來源(District)和不同人口數(shù)量對癌癥發(fā)病率的影響有統(tǒng)計(jì)學(xué)顯著性(P<0.05)�。
殘差散點(diǎn)圖顯示,標(biāo)準(zhǔn)化殘差的變異程度會隨著標(biāo)準(zhǔn)化預(yù)測值的增大而增大�����,呈現(xiàn)擴(kuò)散趨勢����,表明殘差不滿足方差齊性的假設(shè)。
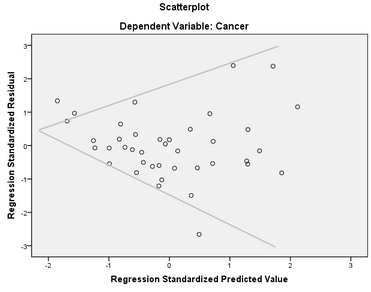
3. 權(quán)重估計(jì)
根據(jù)專業(yè)知識和經(jīng)驗(yàn)判斷����,人口數(shù)量(Population)可能為導(dǎo)致殘差不滿足方差齊性的一個(gè)重要因素,下面對人口數(shù)量進(jìn)行權(quán)重估計(jì)��。
(1)選擇Analyze → Regression → Weight Estimation�����,在Weight Estimation對話框中�,將Cancer選入Dependent,將District和PM2.5選入Independent(s)中。
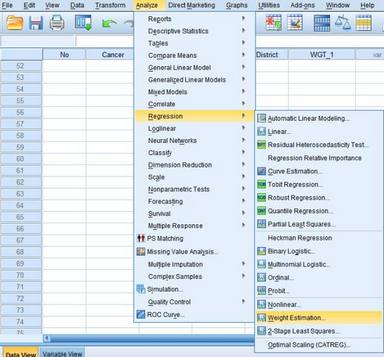
(2)將擬加權(quán)的變量Population選入Weight Variable中���,系統(tǒng)將按照1/(權(quán)重變量)的power次冪對每條記錄進(jìn)行加權(quán)�����。
(3)Power
range用于定義權(quán)重變量的指數(shù)����,默認(rèn)為-2~2��,步長為0.5�,即將擬合指數(shù)分為-2、-1.5����、-1、-0.5�����、0��、0.5��、1���、1.5和2一共構(gòu)建9個(gè)方程中�,并從中選取效果最佳的一個(gè)擬合指數(shù)����。本例中標(biāo)準(zhǔn)化殘差隨著標(biāo)準(zhǔn)化預(yù)測值的增大而增大,因此Power
range為正值��,此處設(shè)定Power range的范圍為0~5���,步長為0.5��。
(4)點(diǎn)擊Option���,選擇Save best weight as new variable,生成一個(gè)新的變量用以保存效果最佳的權(quán)重��。最后點(diǎn)擊Continue回到Weight Estimation主對話框���,點(diǎn)擊OK完成操作�����。
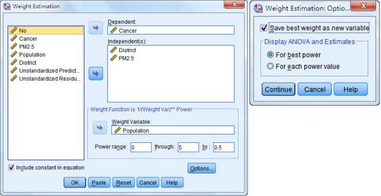
(5)結(jié)果匯總
Log-Likelihood Values表中輸出了在給定步長下每個(gè)指數(shù)值對應(yīng)的對數(shù)似然值���,選取對數(shù)似然值最大的一項(xiàng)為最優(yōu)指數(shù)�,因此本例中最終確定的最優(yōu)指數(shù)值為3�,即權(quán)重按照1/population3的函數(shù)關(guān)系來計(jì)算權(quán)重。同時(shí)系統(tǒng)會在確定最優(yōu)指數(shù)的情況下�,自動生成一個(gè)名為WGT_1的變量用于保存權(quán)重系數(shù)。
4. 最小二乘法操作
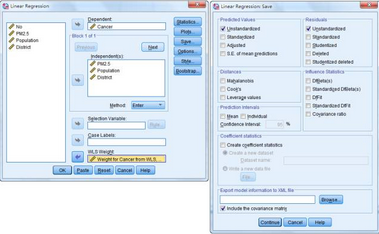
(1)選擇Analyze → Regression → Linear�,在Linear Regression對話框中,將Cancer選入Dependent��,將District�、PM2.5、Population選入Independent(s)中��,將新生成的變量Weight for Cancer from WLS(WGT_1)選入WLS Weight中����。
(2)點(diǎn)擊Save選項(xiàng),在Predicted Values和Residuals框下均選擇Unstandardized���。最后點(diǎn)擊Continue回到Linear Regression主對話框����,點(diǎn)擊OK完成操作。
(3)繪制殘差散點(diǎn)圖
由于在SPSS中使用WLS模型無法直接繪制加權(quán)殘差散點(diǎn)圖�����,SPSS會給出相應(yīng)的警示(如下圖所示)���,因此我們需要按照SPSS提示中提供的計(jì)算公式,對加權(quán)預(yù)測值和加權(quán)殘差值進(jìn)行一定的轉(zhuǎn)換����,然后再繪制轉(zhuǎn)換后的加權(quán)殘差散點(diǎn)圖。

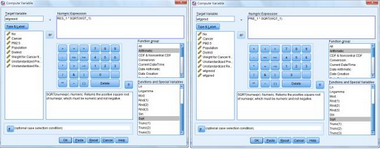
選擇Transform
→ Compute
Variable�,利用前幾步操作生成的權(quán)重值(WGT_1)、加權(quán)預(yù)測值(PRE_1)和加權(quán)殘差值(RES_1)來計(jì)算生成兩個(gè)新變量���,即轉(zhuǎn)換的加權(quán)預(yù)測值wgtpred
= PRE_1 * sqrt(WGT_1)和轉(zhuǎn)換的加權(quán)殘差值wgtresid = RES_1 * sqrt(WGT_1)���。
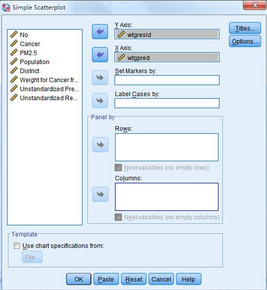
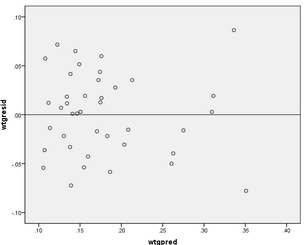
然后選擇Graphs → Legacy Dialogs → Scatter/Dot → Simple Scatter,將wtgpred選入X Axis��,將wtgresid選入Y Axis�,點(diǎn)擊OK繪制散點(diǎn)圖。
5. 結(jié)果匯總
(1)結(jié)果顯示����,采用加權(quán)最小二乘法擬合的線性回歸模型仍具有統(tǒng)計(jì)學(xué)意義(P<0.001)�,決定系數(shù)R Square為0.779�����。由于決定系數(shù)計(jì)算方法本身的問題�����,在加權(quán)線性回歸里會出現(xiàn)一定的偏差���,導(dǎo)致加權(quán)方法計(jì)算得到的R2往往要小于普通最小二乘法的R2��,但這并不代表加權(quán)的模型比普通模型的擬合效果差�����,兩者不能簡單相比�。
(2)模型結(jié)果顯示����,PM2.5平均濃度、不同地區(qū)來源(District)和不同人口數(shù)對癌癥發(fā)病率的影響有統(tǒng)計(jì)學(xué)顯著性(P<0.05)�,且偏回歸系數(shù)較普通最小二乘法更為穩(wěn)健����。
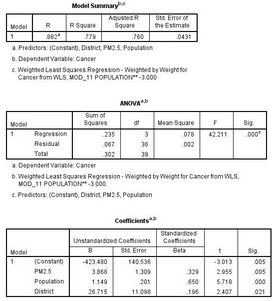
(3)轉(zhuǎn)換后的加權(quán)殘差散點(diǎn)圖顯示��,殘差的散點(diǎn)圍繞ei=0這條直線的上下兩側(cè)均勻分布���,不隨預(yù)測值的變化而變化,說明經(jīng)過加權(quán)校正后�����,殘差已滿足方差齊性的條件�����,達(dá)到了加權(quán)校正的目的����。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情����;
? 想學(xué)習(xí)CDA考試教材,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫���,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情���;
? 想了解CDA考試含金量,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330