時(shí)間序列分析算法【R詳解】
在商業(yè)應(yīng)用中�,時(shí)間是最重要的因素,能夠提升成功率�。然而絕大多數(shù)公司很難跟上時(shí)間的腳步����。但是隨著技術(shù)的發(fā)展,出現(xiàn)了很多有效的方法���,能夠讓我們預(yù)測(cè)未來(lái)�。不要擔(dān)心�����,本文并不會(huì)討論時(shí)間機(jī)器�����,討論的都是很實(shí)用的東西���。
本文將要討論關(guān)于預(yù)測(cè)的方法�。有一種預(yù)測(cè)是跟時(shí)間相關(guān)的�,而這種處理與時(shí)間相關(guān)數(shù)據(jù)的方法叫做時(shí)間序列模型。這個(gè)模型能夠在與時(shí)間相關(guān)的數(shù)據(jù)中��,尋到一些隱藏的信息來(lái)輔助決策�。
當(dāng)我們處理時(shí)序序列數(shù)據(jù)的時(shí)候,時(shí)間序列模型是非常有用的模型�����。大多數(shù)公司都是基于時(shí)間序列數(shù)據(jù)來(lái)分析第二年的銷售量,網(wǎng)站流量�����,競(jìng)爭(zhēng)地位和更多的東西����。然而很多人并不了解的時(shí)間序列分析這個(gè)領(lǐng)域。
所以��,如果你不了解時(shí)間序列模型�����。這篇文章將會(huì)想你介紹時(shí)間序列模型的處理步驟以及它的相關(guān)技術(shù)�����。
本文包含的內(nèi)容如下所示:
目錄
* 1��、時(shí)間序列模型介紹
* 2�、使用R語(yǔ)言來(lái)探索時(shí)間序列數(shù)據(jù)
* 3����、介紹ARMA時(shí)間序列模型
* 4�����、ARIMA時(shí)間序列模型的框架與應(yīng)用
讓我們開始吧
1����、時(shí)間序列模型介紹
Let’s begin����。本節(jié)包括平穩(wěn)序列,隨機(jī)游走,Rho系數(shù),Dickey Fuller檢驗(yàn)平穩(wěn)性�����。如果這些知識(shí)你都不知道���,不用擔(dān)心-接下來(lái)這些概念本節(jié)都會(huì)進(jìn)行詳細(xì)的介紹����,我敢打賭你很喜歡我的介紹的��。
平穩(wěn)序列
判斷一個(gè)序列是不是平穩(wěn)序列有三個(gè)評(píng)判標(biāo)準(zhǔn):
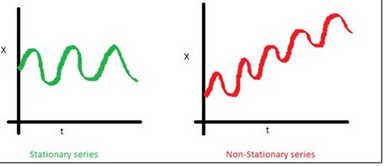
1. 均值 �����,是與時(shí)間t 無(wú)關(guān)的常數(shù)。下圖(左)滿足平穩(wěn)序列的條件��,下圖(右)很明顯具有時(shí)間依賴��。
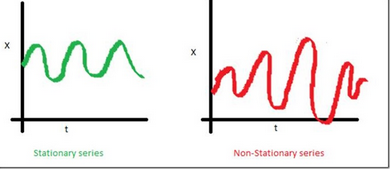
2.方差 �,是與時(shí)間t 無(wú)關(guān)的常數(shù)。這個(gè)特性叫做方差齊性�。下圖顯示了什么是方差對(duì)齊,什么不是方差對(duì)齊��。(注意右手邊途中的不同分布���。)
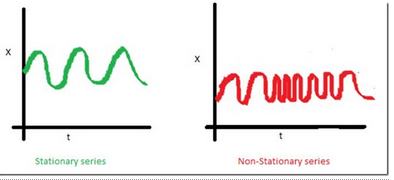
3.協(xié)方差 ����,只與時(shí)期間隔k有關(guān)��,與時(shí)間t 無(wú)關(guān)的常數(shù)�����。如下圖(右)����,可以注意到隨著時(shí)間的增加,曲線變得越來(lái)越近���。因此紅色序列的協(xié)方差并不是恒定的��。
我們?yōu)槭裁匆P(guān)心平穩(wěn)時(shí)間序列呢�����?
除非你的時(shí)間序列是平穩(wěn)的���,否則不能建立一個(gè)時(shí)間序列模型。在很多案例中時(shí)間平穩(wěn)條件常常是不滿足的�����,所以首先要做的就是讓時(shí)間序列變得平穩(wěn)���,然后嘗試使用隨機(jī)模型預(yù)測(cè)這個(gè)時(shí)間序列��。有很多方法來(lái)平穩(wěn)數(shù)據(jù)���,比如消除長(zhǎng)期趨勢(shì),差分化。
隨機(jī)游走
這是時(shí)間序列最基本的概念�。你可能很了解這個(gè)概念。但是��,很多工業(yè)界的人仍然將隨機(jī)游走看做一個(gè)平穩(wěn)序列����。在這一節(jié)中,我會(huì)使用一些數(shù)學(xué)工具��,幫助理解這個(gè)概念�����。我們先看一個(gè)例子
例子:想想一個(gè)女孩隨機(jī)的在想象一個(gè)女孩在一個(gè)巨型棋盤上面隨意移動(dòng)���。這里����,下一個(gè)位置只取決于上一個(gè)位置��。
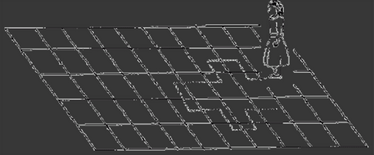
現(xiàn)在想象一下�����,你在一個(gè)封閉的房間里,不能看見這個(gè)女孩���。但是你想要預(yù)測(cè)不同時(shí)刻這個(gè)女孩的位置���。怎么才能預(yù)測(cè)的準(zhǔn)一點(diǎn)����?當(dāng)然隨著時(shí)間的推移你預(yù)測(cè)的越來(lái)越不準(zhǔn)。在t=0時(shí)刻���,你肯定知道這個(gè)女孩在哪里���。下一個(gè)時(shí)刻女孩移動(dòng)到附件8塊方格中的一塊,這個(gè)時(shí)候�,你預(yù)測(cè)到的可能性已經(jīng)降為1/8。繼續(xù)往下繼續(xù)預(yù)測(cè)��,現(xiàn)在我們將這個(gè)序列公式化:
X(t) = X(t-1) + Er(t)
這里的Er(t)代表這這個(gè)時(shí)間點(diǎn)t隨機(jī)干擾項(xiàng)��。這個(gè)就是女孩在每一個(gè)時(shí)間點(diǎn)帶來(lái)的隨機(jī)性��。
現(xiàn)在我們遞歸所有Xs時(shí)間點(diǎn)���,最后我們將得到下面的等式:
X(t) = X(0) + Sum(Er(1),Er(2),Er(3).....Er(t))
現(xiàn)在���,讓我們嘗試驗(yàn)證一下隨機(jī)游走的平穩(wěn)性假設(shè):
1. 是否均值為常數(shù)�����?
E[X(t)] = E[X(0)] + Sum(E[Er(1)],E[Er(2)],E[Er(3)].....E[Er(t)])
我們知道由于隨機(jī)過程的隨機(jī)干擾項(xiàng)的期望值為0.到目前為止:E[X(t)] = E[X(0)] = 常數(shù)
2. 是否方差為常數(shù)���?
Var[X(t)] = Var[X(0)] + Sum(Var[Er(1)],Var[Er(2)],Var[Er(3)].....Var[Er(t)])
Var[X(t)] = t * Var(Error) = 時(shí)間相關(guān)
因此,我們推斷����,隨機(jī)游走不是一個(gè)平穩(wěn)的過程,因?yàn)樗幸粋€(gè)時(shí)變方差�。此外,如果我們檢查的協(xié)方差����,我們看到協(xié)方差依賴于時(shí)間。
我們看一個(gè)更有趣的東西
我們已經(jīng)知道一個(gè)隨機(jī)游走是一個(gè)非平穩(wěn)的過程���。讓我們?cè)诜匠讨幸胍粋€(gè)新的系數(shù)���,看看我們是否能制定一個(gè)檢查平穩(wěn)性的公式�。
Rho系數(shù)
X(t) = Rho * X(t-1) + Er(t)
現(xiàn)在��,我們將改變Rho看看我們可不可以讓這個(gè)序列變的平穩(wěn)�。這里我們只是看,并不進(jìn)行平穩(wěn)性檢驗(yàn)���。
讓我們從一個(gè)Rho=0的完全平穩(wěn)序列開始����。這里是時(shí)間序列的圖:
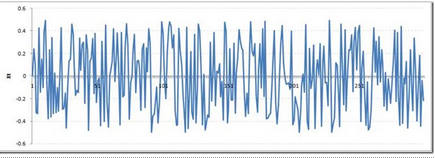
將Rho的值增加到0.5�����,我們將會(huì)得到如下圖:
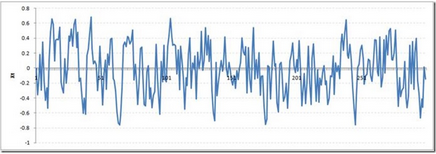
你可能會(huì)注意到�,我們的周期變長(zhǎng)了����,但基本上似乎沒有一個(gè)嚴(yán)重的違反平穩(wěn)性假設(shè)。現(xiàn)在讓我們采取更極端的情況下ρ= 0.9
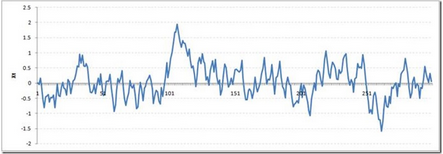
我們?nèi)匀豢吹?����,在一定的時(shí)間間隔后�����,從極端值返回到零。這一系列也不違反非平穩(wěn)性明顯?,F(xiàn)在,讓我們用ρ= 1隨機(jī)游走看看
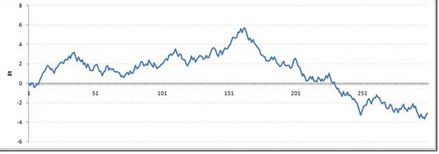
這顯然是違反固定條件�。是什么使rho= 1變得這么特殊的呢?��,這種情況并不滿足平穩(wěn)性測(cè)試����?我們來(lái)找找這個(gè)數(shù)學(xué)的原因
公式X(t) = Rho * X(t-1) + Er(t)的期望為:
E[X(t)] = Rho *E[ X(t-1)]
這個(gè)公式很有意義。下一個(gè)X(或者時(shí)間點(diǎn)t)被拉到Rho*上一個(gè)x的值�。
例如,如果X(t – 1 ) = 1, E[X(t)] = 0.5(Rho= 0.5)?�,F(xiàn)在����,如果從零移動(dòng)到任何方向下一步想要期望為0。唯一可以讓期望變得更大的就是錯(cuò)誤率����。當(dāng)Rho變成1呢?下一步?jīng)]有任何可能下降���。
Dickey Fuller Test平穩(wěn)性
這里學(xué)習(xí)的最后一個(gè)知識(shí)點(diǎn)是Dickey Fuller檢驗(yàn)�����。�。在統(tǒng)計(jì)學(xué)里,Dickey-Fuller檢驗(yàn)是測(cè)試一個(gè)自回歸模型是否存在單位根�����。這里根據(jù)上面Rho系數(shù)有一個(gè)調(diào)整�����,將公式轉(zhuǎn)換為Dickey-Fuller檢驗(yàn)
X(t) = Rho * X(t-1) + Er(t)
=> X(t) - X(t-1) = (Rho - 1) X(t - 1) + Er(t)
我們要測(cè)試如果Rho–1=0是否差異顯著�����。如果零假設(shè)不成立����,我們將得到一個(gè)平穩(wěn)時(shí)間序列��。
平穩(wěn)性測(cè)試和將一個(gè)序列轉(zhuǎn)換為平穩(wěn)性序列是時(shí)間序列模型中最重要的部分�。因此需要記住本節(jié)提到的所有概念方便進(jìn)入下一節(jié)�����。
接下來(lái)就看看時(shí)間序列的例子����。
2�����、使用R探索時(shí)間序列
本節(jié)我們將學(xué)習(xí)如何使用R處理時(shí)間序列����。這里我們只是探索時(shí)間序列,并不會(huì)建立時(shí)間序列模型���。
本節(jié)使用的數(shù)據(jù)是R中的內(nèi)置數(shù)據(jù):AirPassengers�。這個(gè)數(shù)據(jù)集是1949-1960年每個(gè)月國(guó)際航空的乘客數(shù)量的數(shù)據(jù)����。
在入數(shù)據(jù)集
下面的代碼將幫助我們?cè)谌霐?shù)據(jù)集并且能夠看到一些少量的數(shù)據(jù)集。
> data(AirPassengers)
> class(AirPassengers)
[1] "ts"
#查看AirPassengers數(shù)據(jù)類型��,這里是時(shí)間序列數(shù)據(jù)
> start(AirPassengers)
[1] 1949 1
#這個(gè)是Airpassengers數(shù)據(jù)開始的時(shí)間
> end(AirPassengers)
[1] 1960 12
#這個(gè)是Airpassengers數(shù)據(jù)結(jié)束的時(shí)間
> frequency(AirPassengers)
[1] 12
#時(shí)間序列的頻率是一年12個(gè)月
> summary(AirPassengers)
Min. 1st Qu. Median Mean 3rd Qu. Max.
104.0 180.0 265.5 280.3 360.5 622.0
矩陣中詳細(xì)數(shù)據(jù)
#The number of passengers are distributed across the spectrum
> plot(AirPassengers)
#繪制出時(shí)間序列
>abline(reg=lm(AirPassengers~time(AirPassengers)))
# 擬合一條直線
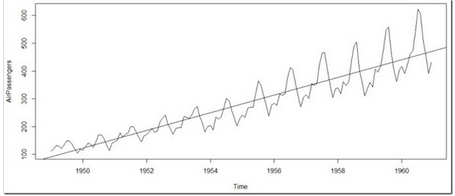
有一些更多的操作需要做
> cycle(AirPassengers)
#打印每年的周期
2 Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec
3 1949 1 2 3 4 5 6 7 8 9 10 11 12
4 1950 1 2 3 4 5 6 7 8 9 10 11 12
5 1951 1 2 3 4 5 6 7 8 9 10 11 12
6 1952 1 2 3 4 5 6 7 8 9 10 11 12
7 1953 1 2 3 4 5 6 7 8 9 10 11 12
8 1954 1 2 3 4 5 6 7 8 9 10 11 12
9 1955 1 2 3 4 5 6 7 8 9 10 11 12
10 1956 1 2 3 4 5 6 7 8 9 10 11 12
11 1957 1 2 3 4 5 6 7 8 9 10 11 12
12 1958 1 2 3 4 5 6 7 8 9 10 11 12
13 1959 1 2 3 4 5 6 7 8 9 10 11 12
14 1960 1 2 3 4 5 6 7 8 9 10 11 12
>plot(aggregate(AirPassengers,FUN=mean))
#This will aggregate the cycles and display a year on year trend
> boxplot(AirPassengers~cycle(AirPassengers))
#Box plot across months will give us a sense on seasonal effect
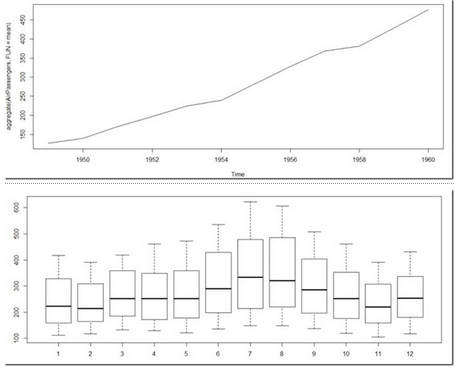
重要推論
每年的趨勢(shì)顯示旅客的數(shù)量每年都在增加
七八月的均值和方差比其他月份要高很多
每個(gè)月的平均值并不相同,但是方差差異很小�。因此,可以看出具有很強(qiáng)的周期性����。,一個(gè)周期為12個(gè)月或更少���。
查看數(shù)據(jù)���,試探數(shù)據(jù)是建立時(shí)間序列模型最重要的一部-如果沒有這一步,你將不知道這個(gè)序列是不是平穩(wěn)序列���。就像這個(gè)例子一樣���,我們已經(jīng)知道了很多關(guān)于這個(gè)模型的很多細(xì)節(jié)。
接下來(lái)我們會(huì)建立一些時(shí)間序列模型以及這些模型的特征����,也會(huì)最一些預(yù)測(cè)����。
3、ARMA時(shí)間序列模型
ARMA也叫自回歸移動(dòng)平均混合模型。ARMA模型經(jīng)常在時(shí)間序列中使用��。在ARMA模型中��,AR代表自回歸��,MA代表移動(dòng)平均����。如果這些術(shù)語(yǔ)聽起來(lái)很復(fù)雜,不用擔(dān)心-下面將會(huì)用幾分鐘的時(shí)間簡(jiǎn)單介紹這些概念��。
我們現(xiàn)在就會(huì)領(lǐng)略這些模型的特點(diǎn)�����。在開始之前��,你首先要記住�,AR或者M(jìn)A并不是應(yīng)用在非平穩(wěn)序列上的。
在實(shí)際應(yīng)用中可能會(huì)得到一個(gè)非平穩(wěn)序列��,你首先要做的就是將這個(gè)序列變成平穩(wěn)序列(通過差分化/轉(zhuǎn)換)��,然后選擇可以使用的時(shí)間序列模型��。
首先,本文將介紹分開介紹兩個(gè)模型(AR&MA)����。接下來(lái)我們看一看這些模型的特點(diǎn)。
自回歸時(shí)間序列模型
讓我們從下面的例子理解AR模型:
現(xiàn)狀一個(gè)國(guó)家的GDP(x(t))依賴與去年的GDP(x(t-1)).這個(gè)假設(shè)一個(gè)國(guó)家今年的GDP總值依賴與去年的GDP總值和今年的新開的工廠和服務(wù)�����。但是GDP的主要依賴與去年去年的GDP����。
那么,GDP的公式為:
x(t) = alpha * x(t – 1) + error (t)
這個(gè)等式就是AR公式�����。公式(1)表示下一個(gè)點(diǎn)完全依賴與前面一個(gè)點(diǎn)����。alpha是一個(gè)系數(shù),希望能夠找到alpha最小化錯(cuò)誤率���。x(t-1)同樣依賴x(t)。
例如�����,x(t)代表一個(gè)城市在某一天的果汁的銷售量。在冬天���,極少的供應(yīng)商進(jìn)果汁���。突然有一天,溫度上升了����,果汁的需求猛增到1000.然而過了幾天,氣溫有下降了�。但是眾所周知,人們?cè)跓崽鞎?huì)喝果汁���,這些人會(huì)有50%在冷天仍然喝果汁���。在接下來(lái)的幾天,這個(gè)比例降到了25%(50%的50%)���,然后幾天后逐漸降到一個(gè)很小的數(shù)���。下圖解釋了AR序列的慣性:
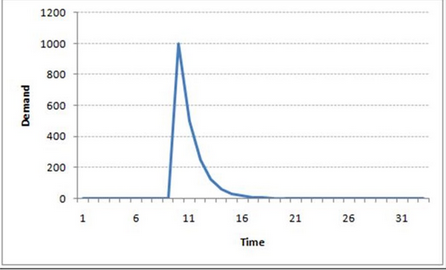
移動(dòng)平均時(shí)間序列模型
接下來(lái)另一個(gè)關(guān)于移動(dòng)平均的例子�。
一個(gè)公司生成某種類型的包�����,這個(gè)很容易理解����。作為一個(gè)競(jìng)爭(zhēng)的市場(chǎng),包的銷售量從零開始增加的�。所以,有一天他做了一個(gè)實(shí)驗(yàn)�����,設(shè)計(jì)并制作了不同的包����,這種包并不會(huì)被隨時(shí)購(gòu)買。因此�,假設(shè)市場(chǎng)上總需求是1000個(gè)這種包。在某一天��,這個(gè)包的需求特別高��,很快庫(kù)存快要完了����。這天結(jié)束了還有100個(gè)包沒賣掉。我們把這個(gè)誤差成為時(shí)間點(diǎn)誤差����。接下來(lái)的幾天仍有幾個(gè)客戶購(gòu)買這種包。下面通過一個(gè)簡(jiǎn)單的公式來(lái)描述這個(gè)場(chǎng)景:
x(t) = beta * error(t-1) + error (t)
嘗試把這個(gè)圖畫出來(lái)��,就是這個(gè)樣子的:
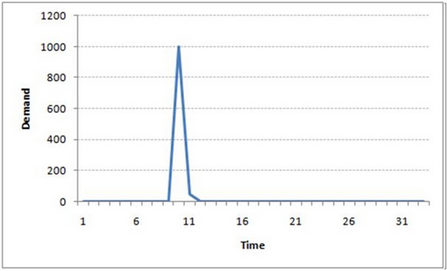
注意到MA和AR模型的不同了沒���?在MA模型中����,噪聲/沖擊迅速小時(shí)���。在AR模型中會(huì)受到長(zhǎng)時(shí)間的影響����。
AR模型與MA模型的不同
AR與MA模型的主要不同在于時(shí)間序列對(duì)象在不同時(shí)間點(diǎn)的相關(guān)性����。
MA模型用過去各個(gè)時(shí)期的隨機(jī)干擾或預(yù)測(cè)誤差的線性組合來(lái)表達(dá)當(dāng)前預(yù)測(cè)值。當(dāng)n>某一個(gè)值時(shí)�,x(t)與x(t-n)的相關(guān)性總為0.AM模型僅通過時(shí)間序列變量的自身歷史觀測(cè)值來(lái)反映有關(guān)因素對(duì)預(yù)測(cè)目標(biāo)的影響和作用����,步驟模型變量相對(duì)獨(dú)立的假設(shè)條件約束���,所構(gòu)成的模型可以消除普通回退預(yù)測(cè)方法中由于自變量選擇��、多重共線性等造成的困難����。即AM模型中x(t)與x(t-1)的相關(guān)性隨著時(shí)間的推移變得越來(lái)越小���。這個(gè)差別要好好利用起來(lái)�����。
利用ACF和PACF繪圖
一旦我們得到一個(gè)平穩(wěn)時(shí)間序列���。我們必須要回答兩個(gè)最重要的問題;
Q1:這個(gè)是AR或者M(jìn)A過程����?
Q2:我們需要利用的AR或者M(jìn)A過程的順序是什么?
解決這兩個(gè)問題我們要借助兩個(gè)系數(shù):
時(shí)間序列x(t)滯后k階的樣本自相關(guān)系數(shù)(ACF)和滯后k期的情況下樣本偏自相關(guān)系數(shù)(PACF)�。公式省略���。
AR模型的ACF和PACF:
通過計(jì)算證明可知:
- AR的ACF為拖尾序列,即無(wú)論滯后期k取多大����,ACF的計(jì)算值均與其1到p階滯后的自相關(guān)函數(shù)有關(guān)���。
- AR的PACF為截尾序列����,即當(dāng)滯后期k>p時(shí)PACF=0的現(xiàn)象�����。
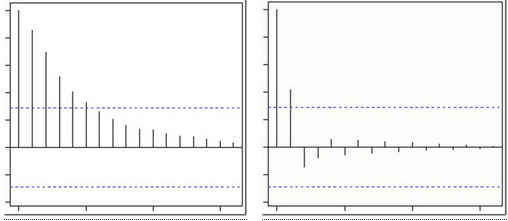
上圖藍(lán)線顯示值與0具有顯著的差異�����。很顯然上面PACF圖顯示截尾于第二個(gè)滯后����,這意味這是一個(gè)AR(2)過程。
MA模型的ACF和PACF:
- MA的ACF為截尾序列�,即當(dāng)滯后期k>p時(shí)PACF=0的現(xiàn)象��。
- AR的PACF為拖尾序列�,即無(wú)論滯后期k取多大��,ACF的計(jì)算值均與其1到p階滯后的自相關(guān)函數(shù)有關(guān)����。
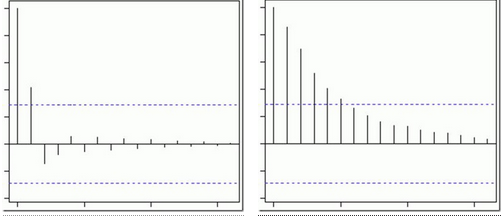
很顯然,上面ACF圖截尾于第二個(gè)滯后����,這以為這是一個(gè)MA(2)過程。
目前��,本文已經(jīng)介紹了關(guān)于使用ACF&PACF圖識(shí)別平穩(wěn)序列的類型?����,F(xiàn)在����,我將介紹一個(gè)時(shí)間序列模型的整體框架。此外�����,還將討論時(shí)間序列模型的實(shí)際應(yīng)用。
4�、ARIMA時(shí)間序列模型的框架與應(yīng)用
到此,本文快速介紹了時(shí)間序列模型的基礎(chǔ)概念����、使用R探索時(shí)間序列和ARMA模型。現(xiàn)在我們將這些零散的東西組織起來(lái)�����,做一件很有趣的事情。
框架
下圖的框架展示了如何一步一步的“做一個(gè)時(shí)間序列分析”
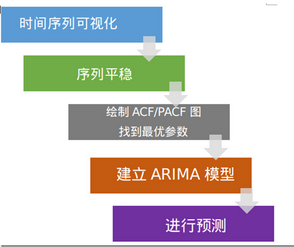
前三步我們?cè)谇拔囊庖娪懻摿?����。盡管如此�,這里還是需要簡(jiǎn)單說(shuō)明一下:
第一步:時(shí)間序列可視化
在構(gòu)建任何類型的時(shí)間序列模型之前,分析其趨勢(shì)是至關(guān)重要的�。我們感興趣的細(xì)節(jié)包括序列中的各種趨勢(shì)、周期\季節(jié)性或者隨機(jī)行為��。在本文的第二部分已經(jīng)介紹了���。
第二步:序列平穩(wěn)
一旦我們知道了模式�、趨勢(shì)、周期����。我們就可以檢查序列是否平穩(wěn)。Dicky-Fuller是一種很流行的檢驗(yàn)方式���。在第一部分意見介紹了這種檢驗(yàn)方式��。在這里還沒有結(jié)束��!如果發(fā)現(xiàn)序列是非平穩(wěn)序列怎么辦����?
這里有三種比較常用的技術(shù)來(lái)讓一個(gè)時(shí)間序列平穩(wěn)��。
1 消除趨勢(shì):這里我們簡(jiǎn)單的刪除時(shí)間序列中的趨勢(shì)成分���。例如���,我的時(shí)間序列的方程是:
x(t) = (mean + trend * t) + error
這里我簡(jiǎn)單的刪除上述公式中的trend*t部分,建立x(t)=mean+error模型
2 差分:這個(gè)技術(shù)常常用來(lái)消除非平穩(wěn)性����。這里我們是對(duì)序列的差分的結(jié)果建立模型而不是真正的序列�。例如:
x(t) – x(t-1) = ARMA (p , q)
這個(gè)差分也是ARIMA的部分?,F(xiàn)在我們有3個(gè)參數(shù)了:
p : AR
d : I
q : MA
3 季節(jié)性:季節(jié)性直接被納入ARIMA模型中。下面的應(yīng)用部分我們?cè)儆懻撨@個(gè)���。
第三步:找到最優(yōu)參數(shù)
參數(shù)p,q可以使用ACF和PACF圖發(fā)現(xiàn)��。除了這種方法�,如果相關(guān)系數(shù)ACF和偏相關(guān)系數(shù)PACF逐漸減小�,這表明我們需要進(jìn)行時(shí)間序列平穩(wěn)并引入d參數(shù)。
第四步:簡(jiǎn)歷ARIMA模型
找到了這些參數(shù)����,我們現(xiàn)在就可以嘗試簡(jiǎn)歷ARIMA模型了�����。從上一步找到的值可能只是一個(gè)近似估計(jì)的值���,我們需要探索更多(p,d,q)的組合��。最小的BIC和AIC的模型參數(shù)才是我們要的��。我們也可以嘗試一些季節(jié)性成分����。在這里,在ACF/PACF圖中我們會(huì)注意到一些季節(jié)性的東西����。
第五步:預(yù)測(cè)
到這步,我們就有了ARIMA模型����,我們現(xiàn)在就可以做預(yù)測(cè)了。我們也可以將這種趨勢(shì)可視化�����,進(jìn)行交叉驗(yàn)證��。
時(shí)間序列模型的應(yīng)用����。
這里我們用前面的例子。使用這個(gè)時(shí)間序列做預(yù)測(cè)�����。我們建議你在進(jìn)行下一步之前,先觀察這個(gè)數(shù)據(jù)���。
我們從哪里開始呢����?
下圖是這些年的乘客數(shù)的圖�。在往下看之前,觀察這個(gè)圖����。
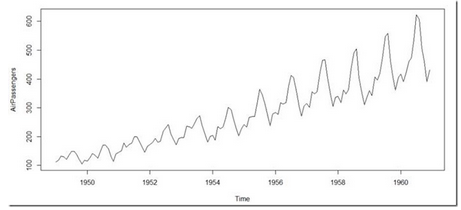
這里是我的觀察:
1. 乘客有著逐年增加的趨勢(shì)。
2. 這看起來(lái)有季節(jié)性�����,每一個(gè)周期不超過12個(gè)月�。
3. 數(shù)據(jù)的方差逐年增加。
在我們進(jìn)行平穩(wěn)性測(cè)試之前我們需要解決兩個(gè)問題���。第一,我們需要消除方差不齊��。這里我們對(duì)這個(gè)序列做求對(duì)數(shù)�。第二我們需要解決序列的趨勢(shì)性�����。我們通過對(duì)時(shí)序序列做差分?����,F(xiàn)在��,我們來(lái)檢驗(yàn)最終序列的平穩(wěn)性����。
adf.test(diff(log(AirPassengers)), alternative="stationary", k=0)
#這里可能會(huì)顯示沒有這個(gè)函數(shù)�����,需要安裝一下.install.packages("tseries")
#加在這個(gè)包,library(tseries)
Augmented Dickey-Fuller Test
data: diff(log(AirPassengers))
Dickey-Fuller = -9.6003, Lag order = 0,
p-value = 0.01
alternative hypothesis: stationary
我們可以看出這個(gè)序列是足夠平穩(wěn)做任何時(shí)間序列模型�����。
下一步就是找到ARIMA模型的正確的參數(shù)����。我們意見知道’d‘是1,因此我們需要做1差分讓序列平穩(wěn)�。這里我們繪制出相關(guān)圖�����。下面就是這個(gè)序列的ACF圖�����。
#ACF Plots
acf(log(AirPassengers))
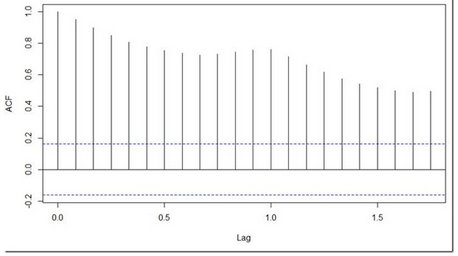
從上述表格可以看出什么���?
很顯然ACF下降的十分的慢,這就意味著乘客的數(shù)量并不是平穩(wěn)的��。我們?cè)谇懊嬉呀?jīng)討論了����,我們現(xiàn)狀準(zhǔn)備在序列去對(duì)數(shù)后的差分上做回歸,而不是直接在序列去對(duì)數(shù)后的數(shù)據(jù)熵差分���。讓我們看一下差分后的ACF和PACF曲線吧�。
acf(diff(log(AirPassengers)))
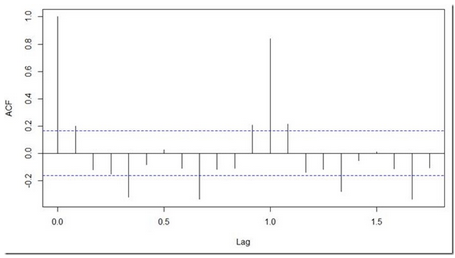
pacf(diff(log(AirPassengers)))
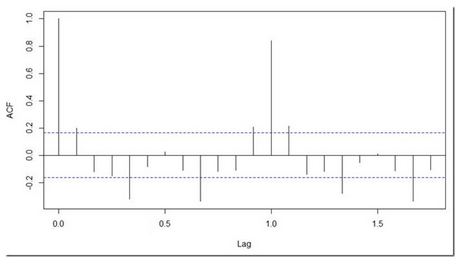
顯然ACF截止與第一個(gè)滯后��,因此我們知道p的值應(yīng)該是0.而q的值應(yīng)該是1或者2.幾次迭代以后����,我們發(fā)現(xiàn)(p,d,q)取(0,1,1)時(shí),AIC和BIC最小���。
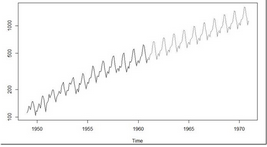
(fit <- arima(log(AirPassengers), c(0, 1, 1),seasonal = list(order = c(0, 1, 1), period = 12)))
pred <- predict(fit, n.ahead = 10*12)
ts.plot(AirPassengers,2.718^pred$pred, log = "y", lty = c(1,3))
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試�����,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情��;
? 想學(xué)習(xí)CDA考試教材����,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫(kù)��,點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情�����;
? 想了解CDA考試含金量�����,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330