R語(yǔ)言-選擇“最佳”的回歸模型
嘗試獲取一個(gè)回歸方程時(shí)���,實(shí)際上你就面對(duì)著從眾多可能的模型中做選擇的問題���。是不是所有的變量都要包括?抑或去掉那個(gè)對(duì)預(yù)測(cè)貢獻(xiàn)不顯著的變量����?還是需要添加多項(xiàng)式項(xiàng)和/或交互項(xiàng)來提高擬合度��?最終回歸模型的選擇總是會(huì)涉及預(yù)測(cè)精度(模型盡可能地?cái)M合數(shù)據(jù))與模型簡(jiǎn)潔度(一個(gè)簡(jiǎn)單且能復(fù)制的模型)的調(diào)和問題���。如果有兩個(gè)幾乎相同預(yù)測(cè)精度的模型,你肯定喜歡簡(jiǎn)單的那個(gè)����。本節(jié)討論的問題,就是如何在候選模型中進(jìn)行篩選����。注意,“最佳”是打了引號(hào)的�����,因?yàn)闆]有做評(píng)價(jià)的唯一標(biāo)準(zhǔn)����,最終的決定需要調(diào)查者的評(píng)判。
8.6.1 模型比較
用基礎(chǔ)安裝中的anova()函數(shù)可以比較兩個(gè)嵌套模型的擬合優(yōu)度���。所謂嵌套模型��,即它的一些項(xiàng)完全包含在另一個(gè)模型中�。在states的多元回歸模型中,我們發(fā)現(xiàn)Income和Frost的回歸系數(shù)不顯著�����,此時(shí)你可以檢驗(yàn)不含這兩個(gè)變量的模型與包含這兩項(xiàng)的模型預(yù)測(cè)效果是否一樣好(見代碼清單8-11)��。
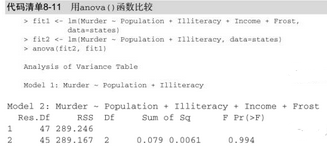
此處����,模型1嵌套在模型2中���。 anova()函數(shù)同時(shí)還對(duì)是否應(yīng)該添加Income和Frost到線性模型中進(jìn)行了檢驗(yàn)�。由于檢驗(yàn)不顯著(p=0.994)����,因此我們可以得出結(jié)論:不需要將這兩個(gè)變量添加到線性模型中,可以將它們從模型中刪除���。
AIC(Akaike
Information Criterion�,赤池信息準(zhǔn)則)也可以用來比較模型�,它考慮了模型的統(tǒng)計(jì)擬合度以及用來擬合的參數(shù)數(shù)目�。
AIC值越小的模型要優(yōu)先選擇���,它說明模型用較少的參數(shù)獲得了足夠的擬合度�����。該準(zhǔn)則可用AIC()函數(shù)實(shí)現(xiàn)(見代碼清單8-12)��。

此處AIC值表明沒有Income和Frost的模型更佳����。注意�, ANOVA需要嵌套模型,而AIC方法不需要���。比較兩模型相對(duì)來說更為直接���,但如果有4個(gè)、 10個(gè)���,或者100個(gè)可能的模型怎么辦呢�����?這便是下節(jié)的主題���。
8.6.2 變量選擇
從大量候選變量中選擇最終的預(yù)測(cè)變量有以下兩種流行的方法:逐步回歸法(stepwise method)和全子集回歸(all-subsets regression)�����。
1. 逐步回歸
逐步回歸中����,模型會(huì)一次添加或者刪除一個(gè)變量�,直到達(dá)到某個(gè)判停準(zhǔn)則為止。例如�����,
向前逐步回歸(forward stepwise)每次添加一個(gè)預(yù)測(cè)變量到模型中���,直到添加變量不會(huì)使模型有所改進(jìn)為止。
向后逐步回歸(backward
stepwise)從模型包含所有預(yù)測(cè)變量開始����,一次刪除一個(gè)變量直到會(huì)降低模型質(zhì)量為止。而向前向后逐步回歸(stepwise
stepwise,通常稱作逐步回歸���,以避免聽起來太冗長(zhǎng))���,結(jié)合了向前逐步回歸和向后逐步回歸的方法,變量每次進(jìn)入一個(gè)��,但是每一步中��,變量都會(huì)被重新評(píng)價(jià)����,對(duì)模型沒有貢獻(xiàn)的變量將會(huì)被刪除,預(yù)測(cè)變量可能會(huì)被添加��、刪除好幾次����,直到獲得最優(yōu)模型為止。
逐步回歸法的實(shí)現(xiàn)依據(jù)增刪變量的準(zhǔn)則不同而不同����。 MASS包中的stepAIC()函數(shù)可以實(shí)現(xiàn)逐步回歸模型(向前、向后和向前向后)�,依據(jù)的是精確AIC準(zhǔn)則。代碼清單8-13中,我們應(yīng)用的是向后回歸�。

開始時(shí)模型包含4個(gè)(全部)預(yù)測(cè)變量,然后每一步中���,
AIC列提供了刪除一個(gè)行中變量后模型的AIC值�, <none>中的AIC值表示沒有變量被刪除時(shí)模型的AIC�。第一步,
Frost被刪除���, AIC從97.75降低到95.75����;第二步���, Income被刪除�����,
AIC繼續(xù)下降,成為93.76�����,然后再刪除變量將會(huì)增加AIC,因此終止選擇過程���。
逐步回歸法其實(shí)存在爭(zhēng)議��,雖然它可能會(huì)找到一個(gè)好的模型����,但是不能保證模型就是最佳模型��,因?yàn)椴皇敲恳粋€(gè)可能的模型都被評(píng)價(jià)了�����。為克服這個(gè)限制�����,便有了全子集回歸法�����。
2. 全子集回歸
全子集回歸�����,顧名思義,即所有可能的模型都會(huì)被檢驗(yàn)���。分析員可以選擇展示所有可能的結(jié)果��,也可以展示n 個(gè)不同子集大?。ㄒ粋€(gè)��、兩個(gè)或多個(gè)預(yù)測(cè)變量)的最佳模型���。 例如�����, 若nbest=2��,先展示兩個(gè)最佳的單預(yù)測(cè)變量模型����,然后展示兩個(gè)最佳的雙預(yù)測(cè)變量模型�,以此類推,直到包含所有的預(yù)測(cè)變量���。全子集回歸可用leaps包中的regsubsets()函數(shù)實(shí)現(xiàn)����。你能通過R平方���、調(diào)整R平方或Mallows Cp統(tǒng)計(jì)量等準(zhǔn)則來選擇“最佳”模型�。
R平方含義是預(yù)測(cè)變量解釋響應(yīng)變量的程度��;調(diào)整R平方與之類似����,但考慮了模型的參數(shù)數(shù)目。
R平方總會(huì)隨著變量數(shù)目的增加而增加����。當(dāng)與樣本量相比,預(yù)測(cè)變量數(shù)目很大時(shí)��,容易導(dǎo)致過擬合�。R平方很可能會(huì)丟失數(shù)據(jù)的偶然變異信息,而調(diào)整R平方則提供了更為真實(shí)的R平方估計(jì)�����。另外����,
Mallows Cp統(tǒng)計(jì)量也用來作為逐步回歸的判停規(guī)則��。廣泛研究表明���,對(duì)于一個(gè)好的模型,它的Cp統(tǒng)計(jì)量非常接近于模型的參數(shù)數(shù)目(包括截距項(xiàng))��。
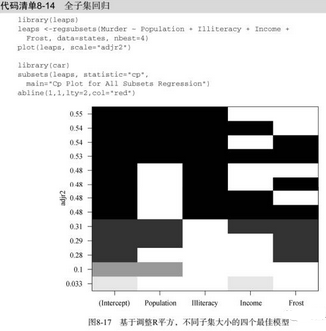
在代碼清單8-14中���,我們對(duì)states數(shù)據(jù)進(jìn)行了全子集回歸���。結(jié)果可用leaps包中的plot()函數(shù)繪制(如圖8-17所示),或者用car包中的subsets()函數(shù)繪制(如圖8-18所示)���。
初看圖8-17可能比較費(fèi)解�����。第一行中(圖底部開始)����,可以看到含intercept(截距項(xiàng))和Income的模型調(diào)整R平方為0.33�,含intercept和Population的模型調(diào)整R平方為0.1�。跳至第12行����,你會(huì)看到含intercept�、
Population、 Illiteracy和Income的模型調(diào)整R平方值為0.54�����,而僅含intercept���、
Population和Illiteracy的模型調(diào)整R平方為0.55����。此處�����,你會(huì)發(fā)現(xiàn)含預(yù)測(cè)變量越少的模型調(diào)整R平方越大(對(duì)于非調(diào)整的R平方����,這是不可能的)。圖形表明��,雙預(yù)測(cè)變量模型(Population和Illiteracy)是最佳模型。
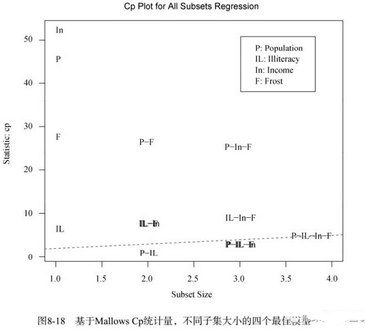
在圖8-18中�,你會(huì)看到對(duì)于不同子集大小,基于Mallows
Cp統(tǒng)計(jì)量的四個(gè)最佳模型�。越好的模型離截距項(xiàng)和斜率均為1的直線越近。圖形表明�����,你可以選擇這幾個(gè)模型���,其余可能的模型都可以不予考慮:含Population和Illiteracy的雙變量模型�;含Population����、
Illiteracy和Frost的三變量模型,或Population����、
Illiteracy和Income的三變量模型(它們?cè)趫D形上重疊了,不易分辨) �;含Population、 Illiteracy��、
Income和Frost的四變量模型。
大部分情況中���,全子集回歸要優(yōu)于逐步回歸���,因?yàn)榭紤]了更多模型。但是���,當(dāng)有大量預(yù)測(cè)變量時(shí),全子集回歸會(huì)很慢��。一般來說�,變量自動(dòng)選擇應(yīng)該被看做是對(duì)模型選擇的一種輔助方法,而不是直接方法����。擬合效果佳而沒有意義的模型對(duì)你毫無幫助,主題背景知識(shí)的理解才能最終指引你獲得理想的模型���。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試���,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情;
? 想學(xué)習(xí)CDA考試教材�,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫(kù),點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情��;
? 想了解CDA考試含金量���,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330