Hadoop集群搭建
目的
本文描述了如何安裝��、配置和管理有實(shí)際意義的Hadoop集群�,其規(guī)??蓮膸讉€節(jié)點(diǎn)的小集群到幾千個節(jié)點(diǎn)的超大集群。
如果你希望在單機(jī)上安裝Hadoop玩玩�,從這里能找到相關(guān)細(xì)節(jié)。
先決條件
確保在你集群中的每個節(jié)點(diǎn)上都安裝了所有必需軟件�����。
獲取Hadoop軟件包。
安裝
安裝Hadoop集群通常要將安裝軟件解壓到集群內(nèi)的所有機(jī)器上�。
通常,集群里的一臺機(jī)器被指定為NameNode�����,另一臺不同的機(jī)器被指定為JobTracker�����。這些機(jī)器是masters��。余下的機(jī)器即作為DataNode也作為TaskTracker�。這些機(jī)器是slaves。
我們用HADOOP_HOME指代安裝的根路徑�����。通常���,集群里的所有機(jī)器的HADOOP_HOME路徑相同��。
配置
接下來的幾節(jié)描述了如何配置Hadoop集群�����。
配置文件
對Hadoop的配置通過conf/目錄下的兩個重要配置文件完成:
hadoop-default.xml - 只讀的默認(rèn)配置��。
hadoop-site.xml- 集群特有的配置�。
要了解更多關(guān)于這些配置文件如何影響Hadoop框架的細(xì)節(jié)����,請看這里。
此外����,通過設(shè)置conf/hadoop-env.sh中的變量為集群特有的值,你可以對bin/目錄下的Hadoop腳本進(jìn)行控制���。
集群配置
要配置Hadoop集群�����,你需要設(shè)置Hadoop守護(hù)進(jìn)程的運(yùn)行環(huán)境和Hadoop守護(hù)進(jìn)程的運(yùn)行參數(shù)����。
Hadoop守護(hù)進(jìn)程指NameNode/DataNode 和JobTracker/TaskTracker����。
配置Hadoop守護(hù)進(jìn)程的運(yùn)行環(huán)境
管理員可在conf/hadoop-env.sh腳本內(nèi)對Hadoop守護(hù)進(jìn)程的運(yùn)行環(huán)境做特別指定��。
至少��,你得設(shè)定JAVA_HOME使之在每一遠(yuǎn)端節(jié)點(diǎn)上都被正確設(shè)置���。
管理員可以通過配置選項(xiàng)HADOOP_*_OPTS來分別配置各個守護(hù)進(jìn)程。
下表是可以配置的選項(xiàng)����。

例如,配置Namenode時,為了使其能夠并行回收垃圾(parallelGC)��,
要把下面的代碼加入到hadoop-env.sh:
export HADOOP_NAMENODE_OPTS="-XX:+UseParallelGC ${HADOOP_NAMENODE_OPTS}"
其它可定制的常用參數(shù)還包括:
HADOOP_LOG_DIR- 守護(hù)進(jìn)程日志文件的存放目錄�。如果不存在會被自動創(chuàng)建�。
HADOOP_HEAPSIZE- 最大可用的堆大小,單位為MB�。比如,1000MB��。
這個參數(shù)用于設(shè)置hadoop守護(hù)進(jìn)程的堆大小�����。缺省大小是1000MB。
配置Hadoop守護(hù)進(jìn)程的運(yùn)行參數(shù)
這部分涉及Hadoop集群的重要參數(shù)����,這些參數(shù)在conf/hadoop-site.xml中指定����。
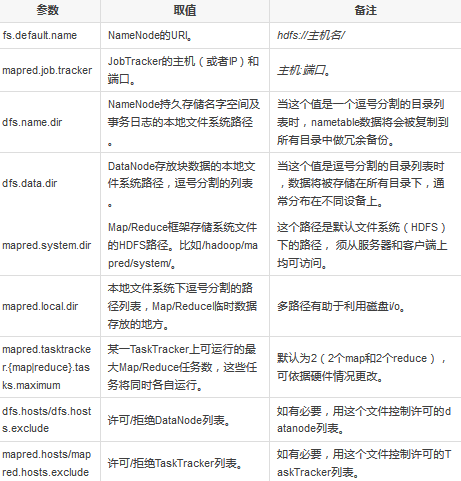
通常,上述參數(shù)被標(biāo)記為
final 以確保它們不被用戶應(yīng)用更改�。
現(xiàn)實(shí)世界的集群配置
這節(jié)羅列在大規(guī)模集群上運(yùn)行sort基準(zhǔn)測試(benchmark)時使用到的一些非缺省配置。
運(yùn)行sort900的一些非缺省配置值�����,sort900即在900個節(jié)點(diǎn)的集群上對9TB的數(shù)據(jù)進(jìn)行排序:
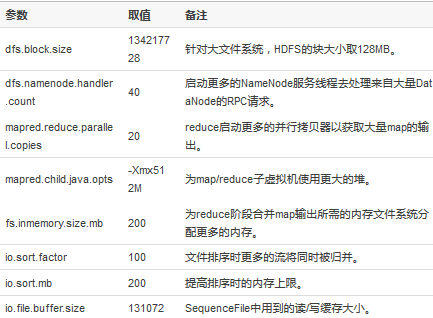
運(yùn)行sort1400和sort2000時需要更新的配置����,即在1400個節(jié)點(diǎn)上對14TB的數(shù)據(jù)進(jìn)行排序和在2000個節(jié)點(diǎn)上對20TB的數(shù)據(jù)進(jìn)行排序:

Slaves
通常,你選擇集群中的一臺機(jī)器作為NameNode��,另外一臺不同的機(jī)器作為JobTracker�����。余下的機(jī)器即作為DataNode又作為TaskTracker,這些被稱之為slaves���。
在conf/slaves文件中列出所有slave的主機(jī)名或者IP地址��,一行一個���。
日志
Hadoop使用Apache log4j來記錄日志,它由Apache Commons Logging框架來實(shí)現(xiàn)�。編輯conf/log4j.properties文件可以改變Hadoop守護(hù)進(jìn)程的日志配置(日志格式等)���。
歷史日志
作業(yè)的歷史文件集中存放在hadoop.job.history.location�,這個也可以是在分布式文件系統(tǒng)下的路徑��,其默認(rèn)值為${HADOOP_LOG_DIR}/history��。jobtracker的web UI上有歷史日志的web UI鏈接����。
歷史文件在用戶指定的目錄hadoop.job.history.user.location也會記錄一份,這個配置的缺省值為作業(yè)的輸出目錄�。這些文件被存放在指定路徑下的“_logs/history/”目錄中。因此�����,默認(rèn)情況下日志文件會在“mapred.output.dir/_logs/history/”下。如果將hadoop.job.history.user.location指定為值none���,系統(tǒng)將不再記錄此日志���。
用戶可使用以下命令在指定路徑下查看歷史日志匯總
$ bin/hadoop job -history output-dir
這條命令會顯示作業(yè)的細(xì)節(jié)信息,失敗和終止的任務(wù)細(xì)節(jié)����。
關(guān)于作業(yè)的更多細(xì)節(jié)�,比如成功的任務(wù),以及對每個任務(wù)的所做的嘗試次數(shù)等可以用下面的命令查看
$ bin/hadoop job -history all output-dir
一但全部必要的配置完成����,將這些文件分發(fā)到所有機(jī)器的HADOOP_CONF_DIR路徑下,通常是${HADOOP_HOME}/conf��。
Hadoop的機(jī)架感知
HDFS和Map/Reduce的組件是能夠感知機(jī)架的�。
NameNode和JobTracker通過調(diào)用管理員配置模塊中的APIresolve來獲取集群里每個slave的機(jī)架id。該API將slave的DNS名稱(或者IP地址)轉(zhuǎn)換成機(jī)架id�。使用哪個模塊是通過配置項(xiàng)topology.node.switch.mapping.impl來指定的。模塊的默認(rèn)實(shí)現(xiàn)會調(diào)用topology.script.file.name配置項(xiàng)指定的一個的腳本/命令���。 如果topology.script.file.name未被設(shè)置��,對于所有傳入的IP地址�����,模塊會返回/default-rack作為機(jī)架id���。在Map/Reduce部分還有一個額外的配置項(xiàng)mapred.cache.task.levels��,該參數(shù)決定cache的級數(shù)(在網(wǎng)絡(luò)拓?fù)渲校?�。例如��,如果默認(rèn)值是2���,會建立兩級的cache- 一級針對主機(jī)(主機(jī) -> 任務(wù)的映射)另一級針對機(jī)架(機(jī)架 -> 任務(wù)的映射)。
啟動Hadoop
啟動Hadoop集群需要啟動HDFS集群和Map/Reduce集群���。
格式化一個新的分布式文件系統(tǒng):
$ bin/hadoop namenode -format
在分配的NameNode上�,運(yùn)行下面的命令啟動HDFS:
$ bin/start-dfs.sh
bin/start-dfs.sh腳本會參照NameNode上${HADOOP_CONF_DIR}/slaves文件的內(nèi)容�����,在所有列出的slave上啟動DataNode守護(hù)進(jìn)程。
在分配的JobTracker上�����,運(yùn)行下面的命令啟動Map/Reduce:
$ bin/start-mapred.sh
bin/start-mapred.sh腳本會參照J(rèn)obTracker上${HADOOP_CONF_DIR}/slaves文件的內(nèi)容���,在所有列出的slave上啟動TaskTracker守護(hù)進(jìn)程���。
停止Hadoop
在分配的NameNode上,執(zhí)行下面的命令停止HDFS:
$ bin/stop-dfs.sh
bin/stop-dfs.sh腳本會參照NameNode上${HADOOP_CONF_DIR}/slaves文件的內(nèi)容��,在所有列出的slave上停止DataNode守護(hù)進(jìn)程���。
在分配的JobTracker上,運(yùn)行下面的命令停止Map/Reduce:
$ bin/stop-mapred.sh
bin/stop-mapred.sh腳本會參照J(rèn)obTracker上${HADOOP_CONF_DIR}/slaves文件的內(nèi)容�����,在所有列出的slave上停止TaskTracker守護(hù)進(jìn)程�����。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試����,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情�����;
? 想學(xué)習(xí)CDA考試教材�����,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫�,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量�����,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330