Hadoop面試中6個(gè)常見(jiàn)的問(wèn)題及答案
準(zhǔn)備好面試了嗎?呀��,需要Hadoop的知識(shí)?����。��?��?不要慌!這里有一些可能會(huì)問(wèn)到的問(wèn)題以及你應(yīng)該給出的答案���。
Q1.什么是Hadoop���?
Hadoop是一個(gè)開(kāi)源軟件框架�,用于存儲(chǔ)大量數(shù)據(jù)����,并發(fā)處理/查詢?cè)诰哂卸鄠€(gè)商用硬件(即低成本硬件)節(jié)點(diǎn)的集群上的那些數(shù)據(jù)�。總之�,Hadoop包括以下內(nèi)容:
HDFS(Hadoop
Distributed File System,Hadoop分布式文件系統(tǒng)):HDFS允許你以一種分布式和冗余的方式存儲(chǔ)大量數(shù)據(jù)�。例如,1
GB(即1024 MB)文本文件可以拆分為16 *
128MB文件�����,并存儲(chǔ)在Hadoop集群中的8個(gè)不同節(jié)點(diǎn)上���。每個(gè)分裂可以復(fù)制3次��,以實(shí)現(xiàn)容錯(cuò)��,以便如果1個(gè)節(jié)點(diǎn)故障的話�����,也有備份����。HDFS適用于順序的“一次寫入、多次讀取”的類型訪問(wèn)��。
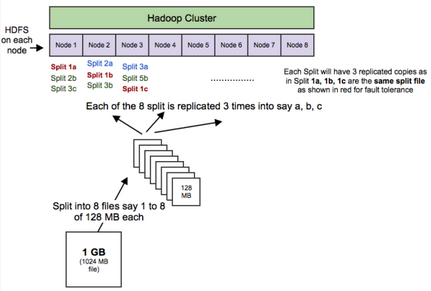
MapReduce:一個(gè)計(jì)算框架����。它以分布式和并行的方式處理大量的數(shù)據(jù)。當(dāng)你對(duì)所有年齡>
18的用戶在上述1 GB文件上執(zhí)行查詢時(shí)���,將會(huì)有“8個(gè)映射”函數(shù)并行運(yùn)行�,以在其128 MB拆分文件中提取年齡>
18的用戶����,然后“reduce”函數(shù)將運(yùn)行以將所有單獨(dú)的輸出組合成單個(gè)最終結(jié)果。
YARN(Yet Another Resource Nagotiator����,又一資源定位器):用于作業(yè)調(diào)度和集群資源管理的框架。
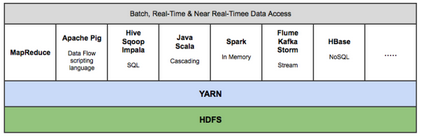
Hadoop生態(tài)系統(tǒng)�,擁有15多種框架和工具���,如Sqoop,F(xiàn)lume�,Kafka,Pig�,Hive,Spark���,Impala等,以便將數(shù)據(jù)攝入HDFS�,在HDFS中轉(zhuǎn)移數(shù)據(jù)(即變換,豐富��,聚合等)����,并查詢來(lái)自HDFS的數(shù)據(jù)用于商業(yè)智能和分析。某些工具(如Pig和Hive)是MapReduce上的抽象層����,而Spark和Impala等其他工具則是來(lái)自MapReduce的改進(jìn)架構(gòu)/設(shè)計(jì),用于顯著提高的延遲以支持近實(shí)時(shí)(即NRT)和實(shí)時(shí)處理�����。
Q2.為什么組織從傳統(tǒng)的數(shù)據(jù)倉(cāng)庫(kù)工具轉(zhuǎn)移到基于Hadoop生態(tài)系統(tǒng)的智能數(shù)據(jù)中心?
Hadoop組織正在從以下幾個(gè)方面提高自己的能力:
現(xiàn)有數(shù)據(jù)基礎(chǔ)設(shè)施:
主要使用存儲(chǔ)在高端和昂貴硬件中的“structured data���,結(jié)構(gòu)化數(shù)據(jù)”
主要處理為ETL批處理作業(yè)�����,用于將數(shù)據(jù)提取到RDBMS和數(shù)據(jù)倉(cāng)庫(kù)系統(tǒng)中進(jìn)行數(shù)據(jù)挖掘���,分析和報(bào)告,以進(jìn)行關(guān)鍵業(yè)務(wù)決策��。
主要處理以千兆字節(jié)到兆字節(jié)為單位的數(shù)據(jù)量
基于Hadoop的更智能的數(shù)據(jù)基礎(chǔ)設(shè)施��,其中
結(jié)構(gòu)化(例如RDBMS)�,非結(jié)構(gòu)化(例如images,PDF�����,docs )和半結(jié)構(gòu)化(例如logs����,XMLs)的數(shù)據(jù)可以以可擴(kuò)展和容錯(cuò)的方式存儲(chǔ)在較便宜的商品機(jī)器中。
可以通過(guò)批處理作業(yè)和近實(shí)時(shí)(即,NRT�����,200毫秒至2秒)流(例如Flume和Kafka)來(lái)攝取數(shù)據(jù)�。
數(shù)據(jù)可以使用諸如Spark和Impala之類的工具以低延遲(即低于100毫秒)的能力查詢。
可以存儲(chǔ)以兆兆字節(jié)到千兆字節(jié)為單位的較大數(shù)據(jù)量���。
這使得組織能夠使用更強(qiáng)大的工具來(lái)做出更好的業(yè)務(wù)決策���,這些更強(qiáng)大的工具用于獲取數(shù)據(jù),轉(zhuǎn)移存儲(chǔ)的數(shù)據(jù)(例如聚合���,豐富,變換等)����,以及使用低延遲的報(bào)告功能和商業(yè)智能。
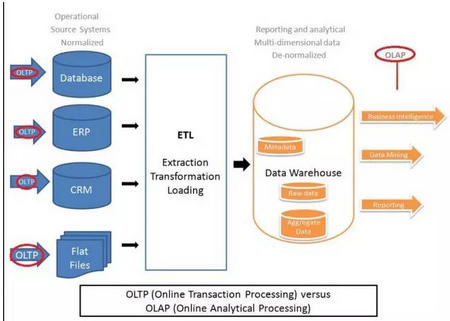
Q3.更智能&更大的數(shù)據(jù)中心架構(gòu)與傳統(tǒng)的數(shù)據(jù)倉(cāng)庫(kù)架構(gòu)有何不同�����?
傳統(tǒng)的企業(yè)數(shù)據(jù)倉(cāng)庫(kù)架構(gòu)
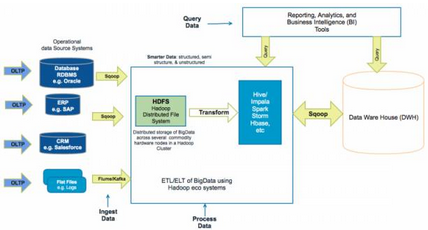
基于Hadoop的數(shù)據(jù)中心架構(gòu)
Q4.基于Hadoop的數(shù)據(jù)中心的好處是什么��?
隨著數(shù)據(jù)量和復(fù)雜性的增加����,提高了整體SLA(即服務(wù)水平協(xié)議)�。例如��,“Shared Nothing”架構(gòu),并行處理�����,內(nèi)存密集型處理框架�����,如Spark和Impala�,以及YARN容量調(diào)度程序中的資源搶占�����。
縮放數(shù)據(jù)倉(cāng)庫(kù)可能會(huì)很昂貴���。添加額外的高端硬件容量以及獲取數(shù)據(jù)倉(cāng)庫(kù)工具的許可證可能會(huì)顯著增加成本��?��;?a href='/map/hadoop/' style='color:#000;font-size:inherit;'>Hadoop的解決方案不僅在商品硬件節(jié)點(diǎn)和開(kāi)源工具方面更便宜����,而且還可以通過(guò)將數(shù)據(jù)轉(zhuǎn)換卸載到Hadoop工具(如Spark和Impala)來(lái)補(bǔ)足數(shù)據(jù)倉(cāng)庫(kù)解決方案�����,從而更高效地并行處理大數(shù)據(jù)����。這也將釋放數(shù)據(jù)倉(cāng)庫(kù)資源。
探索新的渠道和線索�。Hadoop可以為數(shù)據(jù)科學(xué)家提供探索性的沙盒,以從社交媒體���,日志文件���,電子郵件等地方發(fā)現(xiàn)潛在的有價(jià)值的數(shù)據(jù)����,這些數(shù)據(jù)通常在數(shù)據(jù)倉(cāng)庫(kù)中不可得。
更好的靈活性�。通常業(yè)務(wù)需求的改變,也需要對(duì)架構(gòu)和報(bào)告進(jìn)行更改?����;?a href='/map/hadoop/' style='color:#000;font-size:inherit;'>Hadoop的解決方案不僅可以靈活地處理不斷發(fā)展的模式�,還可以處理來(lái)自不同來(lái)源,如社交媒體��,應(yīng)用程序日志文件��,image�,PDF和文檔文件的半結(jié)構(gòu)化和非結(jié)構(gòu)化數(shù)據(jù)。
Q5.大數(shù)據(jù)解決方案的關(guān)鍵步驟是什么���?
提取數(shù)據(jù)�����,存儲(chǔ)數(shù)據(jù)(即數(shù)據(jù)建模)和處理數(shù)據(jù)(即數(shù)據(jù)加工��,數(shù)據(jù)轉(zhuǎn)換和查詢數(shù)據(jù))�����。
提取數(shù)據(jù)
從各種來(lái)源提取數(shù)據(jù)����,例如:
RDBM(Relational Database Management Systems)關(guān)系數(shù)據(jù)庫(kù)管理系統(tǒng),如Oracle��,MySQL等����。
ERPs(Enterprise Resource Planning)企業(yè)資源規(guī)劃(即ERP)系統(tǒng),如SAP��。
CRM(Customer Relationships Management)客戶關(guān)系管理系統(tǒng)�,如Siebel,Salesforce等
社交媒體Feed和日志文件���。
平面文件�����,文檔和圖像�。
并將其存儲(chǔ)在基于“Hadoop分布式文件系統(tǒng)”(簡(jiǎn)稱HDFS)的數(shù)據(jù)中心上�����?����?梢酝ㄟ^(guò)批處理作業(yè)(例如每15分鐘運(yùn)行一次��,每晚一次����,等),近實(shí)時(shí)(即100毫秒至2分鐘)流式傳輸和實(shí)時(shí)流式傳輸(即100毫秒以下)去采集數(shù)據(jù)����。
Hadoop中使用的一個(gè)常用術(shù)語(yǔ)是“Schema-On-Read”。這意味著未處理(也稱為原始)的數(shù)據(jù)可以被加載到HDFS����,其具有基于處理應(yīng)用的需求在處理之時(shí)應(yīng)用的結(jié)構(gòu)。這與“Schema-On-Write”不同��,后者用于需要在加載數(shù)據(jù)之前在RDBM中定義模式���。
存儲(chǔ)數(shù)據(jù)
數(shù)據(jù)可以存儲(chǔ)在HDFS或NoSQL數(shù)據(jù)庫(kù)����,如HBase����。HDFS針對(duì)順序訪問(wèn)和“一次寫入和多次讀取”的使用模式進(jìn)行了優(yōu)化���。HDFS具有很高的讀寫速率,因?yàn)樗梢詫
/
O并行到多個(gè)驅(qū)動(dòng)器��。HBase在HDFS之上��,并以柱狀方式將數(shù)據(jù)存儲(chǔ)為鍵/值對(duì)���。列作為列家族在一起���。HBase適合隨機(jī)讀/寫訪問(wèn)。在Hadoop中存儲(chǔ)數(shù)據(jù)之前���,你需要考慮以下幾點(diǎn):
數(shù)據(jù)存儲(chǔ)格式:有許多可以應(yīng)用的文件格式(例如CSV��,JSON��,序列�,AVRO��,Parquet等)和數(shù)據(jù)壓縮算法(例如snappy����,LZO,gzip����,bzip2等)。每個(gè)都有特殊的優(yōu)勢(shì)�。像LZO和bzip2的壓縮算法是可拆分的。
數(shù)據(jù)建模:盡管Hadoop的無(wú)模式性質(zhì)���,模式設(shè)計(jì)依然是一個(gè)重要的考慮方面���。這包括存儲(chǔ)在HBase,Hive和Impala中的對(duì)象的目錄結(jié)構(gòu)和模式��。Hadoop通常用作整個(gè)組織的數(shù)據(jù)中心����,并且數(shù)據(jù)旨在共享。因此��,結(jié)構(gòu)化和有組織的數(shù)據(jù)存儲(chǔ)很重要����。
元數(shù)據(jù)管理:與存儲(chǔ)數(shù)據(jù)相關(guān)的元數(shù)據(jù)��。
多用戶:更智能的數(shù)據(jù)中心托管多個(gè)用戶��、組和應(yīng)用程序����。這往往導(dǎo)致與統(tǒng)治�、標(biāo)準(zhǔn)化和管理相關(guān)的挑戰(zhàn)。
處理數(shù)據(jù)
Hadoop的處理框架使用HDFS�。它使用“Shared
Nothing”架構(gòu),在分布式系統(tǒng)中����,每個(gè)節(jié)點(diǎn)完全獨(dú)立于系統(tǒng)中的其他節(jié)點(diǎn)。沒(méi)有共享資源�����,如CPU���,內(nèi)存以及會(huì)成為瓶頸的磁盤存儲(chǔ)���。Hadoop的處理框架(如Spark,Pig,Hive�����,Impala等)處理數(shù)據(jù)的不同子集�����,并且不需要管理對(duì)共享數(shù)據(jù)的訪問(wèn)�。
“Shared
Nothing”架構(gòu)是非?��?蓴U(kuò)展的�����,因?yàn)楦嗟墓?jié)點(diǎn)可以被添加而沒(méi)有更進(jìn)一步的爭(zhēng)用和容錯(cuò)���,因?yàn)槊總€(gè)節(jié)點(diǎn)是獨(dú)立的,并且沒(méi)有單點(diǎn)故障����,系統(tǒng)可以從單個(gè)節(jié)點(diǎn)的故障快速恢復(fù)。
Q6.你會(huì)如何選擇不同的文件格式存儲(chǔ)和處理數(shù)據(jù)����?
設(shè)計(jì)決策的關(guān)鍵之一是基于以下方面關(guān)注文件格式:
使用模式�����,例如訪問(wèn)50列中的5列��,而不是訪問(wèn)大多數(shù)列����。
可并行處理的可分裂性���。
塊壓縮節(jié)省存儲(chǔ)空間vs讀/寫/傳輸性能
模式演化以添加字段��,修改字段和重命名字段�����。
CSV文件
CSV文件通常用于在Hadoop和外部系統(tǒng)之間交換數(shù)據(jù)�����。CSV是可讀和可解析的���。
CSV可以方便地用于從數(shù)據(jù)庫(kù)到Hadoop或到分析數(shù)據(jù)庫(kù)的批量加載。在Hadoop中使用CSV文件時(shí),不包括頁(yè)眉或頁(yè)腳行��。文件的每一行都應(yīng)包含記錄����。CSV文件對(duì)模式評(píng)估的支持是有限的,因?yàn)樾?a href='/map/ziduan/' style='color:#000;font-size:inherit;'>字段只能附加到記錄的結(jié)尾����,并且現(xiàn)有字段不能受到限制。CSV文件不支持塊壓縮���,因此壓縮CSV文件會(huì)有明顯的讀取性能成本。
JSON文件
JSON記錄與JSON文件不同���;每一行都是其JSON記錄��。由于JSON將模式和數(shù)據(jù)一起存儲(chǔ)在每個(gè)記錄中���,因此它能夠?qū)崿F(xiàn)完整的模式演進(jìn)和可拆分性。此外�,JSON文件不支持塊級(jí)壓縮。
序列文件
序列文件以與CSV文件類似的結(jié)構(gòu)用二進(jìn)制格式存儲(chǔ)數(shù)據(jù)�。像CSV一樣,序列文件不存儲(chǔ)元數(shù)據(jù),因此只有模式進(jìn)化才將新字段附加到記錄的末尾����。與CSV文件不同,序列文件確實(shí)支持塊壓縮��。序列文件也是可拆分的�。序列文件可以用于解決“小文件問(wèn)題”,方式是通過(guò)組合較小的通過(guò)存儲(chǔ)文件名作為鍵和文件內(nèi)容作為值的XML文件��。由于讀取序列文件的復(fù)雜性�,它們更適合用于在飛行中的(即中間的)數(shù)據(jù)存儲(chǔ)。
注意:序列文件是以Java為中心的�,不能跨平臺(tái)使用。
Avro文件
適合于有模式的長(zhǎng)期存儲(chǔ)���。Avro文件存儲(chǔ)具有數(shù)據(jù)的元數(shù)據(jù)�����,但也允許指定用于讀取文件的獨(dú)立模式���。啟用完全的模式進(jìn)化支持,允許你通過(guò)定義新的獨(dú)立模式重命名����、添加和刪除字段以及更改字段的數(shù)據(jù)類型�。Avro文件以JSON格式定義模式���,數(shù)據(jù)將采用二進(jìn)制JSON格式��。Avro文件也是可拆分的����,并支持塊壓縮���。更適合需要行級(jí)訪問(wèn)的使用模式�����。這意味著查詢?cè)撔兄械乃辛小2贿m用于行有50+列����,但使用模式只需要訪問(wèn)10個(gè)或更少的列。Parquet文件格式更適合這個(gè)列訪問(wèn)使用模式�。
Columnar格式,例如RCFile���,ORC
RDBM以面向行的方式存儲(chǔ)記錄����,因?yàn)檫@對(duì)于需要在獲取許多列的記錄的情況下是高效的。如果在向磁盤寫入記錄時(shí)已知所有列值�,則面向行的寫也是有效的。但是這種方法不能有效地獲取行中的僅10%的列或者在寫入時(shí)所有列值都不知道的情況���。這是Columnar文件更有意義的地方���。所以Columnar格式在以下情況下工作良好
在不屬于查詢的列上跳過(guò)I / O和解壓縮
用于僅訪問(wèn)列的一小部分的查詢。
用于數(shù)據(jù)倉(cāng)庫(kù)型應(yīng)用程序���,其中用戶想要在大量記錄上聚合某些列�。
RC和ORC格式是專門用Hive寫的而不是通用作為Parquet����。
Parquet文件
Parquet文件是一個(gè)columnar文件,如RC和ORC�����。Parquet文件支持塊壓縮并針對(duì)查詢性能進(jìn)行了優(yōu)化���,可以從50多個(gè)列記錄中選擇10個(gè)或更少的列�����。Parquet文件寫入性能比非columnar文件格式慢�。Parquet通過(guò)允許在最后添加新列,還支持有限的模式演變�����。Parquet可以使用Avro
API和Avro架構(gòu)進(jìn)行讀寫�����。
所以����,總而言之,相對(duì)于其他��,你應(yīng)該會(huì)更喜歡序列�����,Avro和Parquet文件格式���;序列文件用于原始和中間存儲(chǔ)����,Avro和Parquet文件用于處理���。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試���,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情;
? 想學(xué)習(xí)CDA考試教材�,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫(kù)�,點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情;
? 想了解CDA考試含金量�,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330