Excel數(shù)據(jù)分析:抽樣設(shè)計(jì)
一���、隨機(jī)數(shù)發(fā)生器
1. 隨機(jī)數(shù)發(fā)生器主要功能
“隨機(jī)數(shù)發(fā)生器”分析工具可用幾個分布之一產(chǎn)生的獨(dú)立隨機(jī)數(shù)來填充某個區(qū)域�?���?梢酝ㄟ^概率分布來表示總體中的主體特征。例如�,可以使用正態(tài)分布來表示人體身高的總體特征,或者使用雙值輸出的伯努利分布來表示擲幣實(shí)驗(yàn)結(jié)果的總體特征��。
2. 隨機(jī)數(shù)發(fā)生器對話框簡介
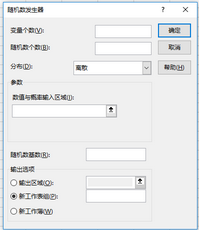
隨機(jī)數(shù)發(fā)生器對話框
該對話框中的參數(shù)隨分布的選擇而有所不同���,其余均相同����。
變量個數(shù):在此輸入輸出表中數(shù)值列的個數(shù)�。
隨機(jī)數(shù)個數(shù):在此輸入要查看的數(shù)據(jù)點(diǎn)個數(shù)。每一個數(shù)據(jù)點(diǎn)出現(xiàn)在輸出表的一行中��。
分布:在此單擊用于創(chuàng)建隨機(jī)數(shù)的分布方法���。包括以下幾種:均勻分布����、正態(tài)分布���、伯努利分布�����、二項(xiàng)式�����、泊松����、模式��、離散���。
隨機(jī)數(shù)基數(shù):在此輸入用來產(chǎn)生隨機(jī)數(shù)的可選數(shù)值���?����?稍谝院笾匦率褂迷摂?shù)值來生成相同的隨機(jī)數(shù)�����。
輸出區(qū)域:在此輸入對輸出表左上角單元格的引用�����。如果輸出表將替換現(xiàn)有數(shù)據(jù)�����,Excel 會自動確定輸出區(qū)域的大小并顯示一條消息����。
新工作表:單擊此選項(xiàng)可在當(dāng)前工作簿中插入新工作表��,并從新工作表的 A1 單元格開始粘貼計(jì)算結(jié)果���。若要為新工作表命名�,請?jiān)诳蛑墟I入名稱。
新工作簿:單擊此選項(xiàng)可創(chuàng)建新工作簿并將結(jié)果添加到其中的新工作表中���。
3. 隨機(jī)數(shù)發(fā)生器應(yīng)用舉例
3.1 均勻隨機(jī)數(shù)的產(chǎn)生
均勻:以下限和上限來表征。其變量是通過對區(qū)域中的所有數(shù)值進(jìn)行等概率抽取而得到的�。普通的應(yīng)用使用范圍
0 到 1 之間的均勻分布。相當(dāng)于工作表函數(shù):“= a+RAND()*(b-a)”�����,與RANDBETWEEN
(a,b)”的區(qū)別是��,RANDBETWEEN產(chǎn)生的是離散型隨機(jī)數(shù)��,而隨機(jī)數(shù)發(fā)生器產(chǎn)生的是連續(xù)型隨機(jī)數(shù)����。
離散型函數(shù)產(chǎn)生可重復(fù)隨機(jī)數(shù),若想產(chǎn)生無重復(fù)隨機(jī)數(shù)����,應(yīng)使用連續(xù)型,再從中利用RANK函數(shù)產(chǎn)生整型�����。通常在進(jìn)行抽樣設(shè)計(jì)時(shí)要產(chǎn)生無重復(fù)的整型均勻隨機(jī)數(shù)。
例:在編號為1至20之間隨機(jī)抽取10個無重復(fù)的均勻隨機(jī)數(shù)��。
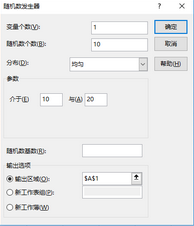
均勻隨機(jī)數(shù)對話框
單擊“確定”生成連續(xù)型隨機(jī)數(shù)(如圖)�。
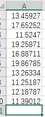
產(chǎn)生隨機(jī)數(shù)
由圖可見,所產(chǎn)生的是連續(xù)型隨機(jī)數(shù)�����,若四舍五入取整�,在B1單元格輸入公式“=ROUND(A1,0)”,并復(fù)制到B1:B10��,得到整型隨機(jī)數(shù)����。
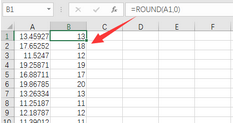
由圖可見,數(shù)字13出現(xiàn)了兩次��,為可重復(fù)隨機(jī)數(shù)�����。在統(tǒng)計(jì)調(diào)查時(shí),不能對同一調(diào)查對象調(diào)查兩次���,應(yīng)產(chǎn)生無重復(fù)隨機(jī)數(shù)�。處理的辦法如下:
在A列對總體進(jìn)行編號�����;在B2輸入公式“=RAND()”��,生產(chǎn)0至1之間的均勻隨機(jī)數(shù)�,并復(fù)制到B3:B21���;C列顯示樣本序號���;選擇D2:D11單元格區(qū)域,在D2單元格輸入公式“=RANK(B2:B21,B2:B21)”��,按住Ctrl+Shift不放再按回車鍵��,生成隨機(jī)數(shù)�。該隨機(jī)數(shù)是無重復(fù)的。當(dāng)然也可由VLOOKUP函數(shù)實(shí)現(xiàn)��,所處從略�。
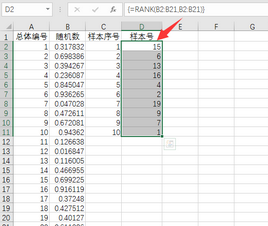
無重復(fù)隨機(jī)數(shù)的產(chǎn)生
3.2 正態(tài)隨機(jī)數(shù)的產(chǎn)生
正態(tài)分布描述:
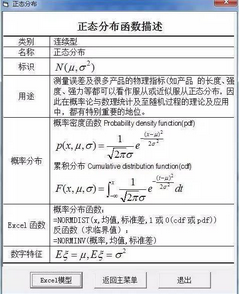
正態(tài)分布描述
正態(tài):以平均值和標(biāo)準(zhǔn)偏差來表征����,相當(dāng)于工作表函數(shù)“=NORMINV(rand(),mu,sigma)”
例:產(chǎn)生10行8列來自均值為100����、標(biāo)準(zhǔn)差為10的總體隨機(jī)數(shù)。
隨機(jī)數(shù)發(fā)生器選擇“分布”為“正態(tài)”�����,設(shè)置對話框如下:
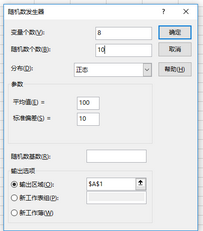
隨機(jī)數(shù)發(fā)生器對話框的正態(tài)分布設(shè)置
單擊“確定”生成隨機(jī)數(shù)如下:
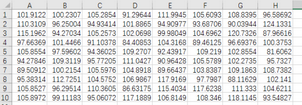
產(chǎn)生的正態(tài)分布隨機(jī)數(shù)
3.3 產(chǎn)生0-1分布隨機(jī)數(shù)
伯努利:以給定的試驗(yàn)中成功的概率(p 值)來表征����。伯努利隨機(jī)變量的值為 0 或 1。等價(jià)于函數(shù):“=IF(RAND())”.
例:產(chǎn)生5列10行的成功概率為0.5的0-1隨機(jī)數(shù)�。驗(yàn)證概率的頻率法定義。
隨機(jī)數(shù)發(fā)生器“分布”選擇柏努利�����,設(shè)置對話框如下:
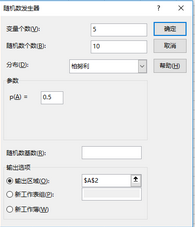
0-1隨機(jī)數(shù)對話框
單擊“確定”生成隨機(jī)數(shù)��。
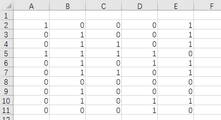
在G列輸入累積的試驗(yàn)次數(shù)�����;H2輸入公式,統(tǒng)計(jì)正態(tài)朝上的次數(shù)(1的個數(shù))�;I2求得頻率(=H2/G2);將H2:I2復(fù)制到H3:I21單元格區(qū)域�����。
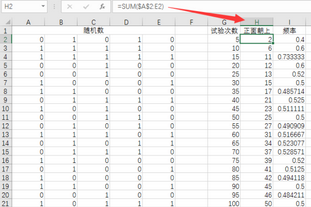
以H列為橫坐標(biāo)�����,I列為縱坐標(biāo)���,繪制不帶標(biāo)志點(diǎn)的折線型散點(diǎn)圖。由圖可見����,隨機(jī)試驗(yàn)次數(shù)的增加,頻率逐步趨于0.5
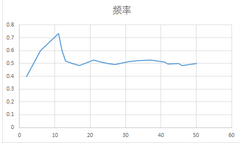
頻率法概率定義的驗(yàn)證
3.4 產(chǎn)生二項(xiàng)分布隨機(jī)數(shù)
二項(xiàng)式:以一系列試驗(yàn)中成功的概率(p 值)來表征���。例如�����,可以按照試驗(yàn)次數(shù)生成一系列伯努利隨機(jī)變量���,這些變量之和為一個二項(xiàng)式隨機(jī)變量�����。
二項(xiàng)分布描述:
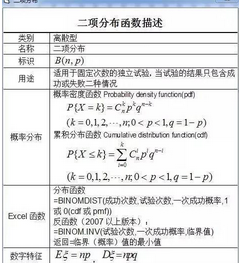
二項(xiàng)分布描述
例:某射手中靶的概率為0.8�,每次射擊10發(fā)子彈�,射擊10次,模擬每次中靶的次數(shù)�。
隨機(jī)數(shù)發(fā)生器選擇“分布”為“二項(xiàng)”,設(shè)置對話框如下:
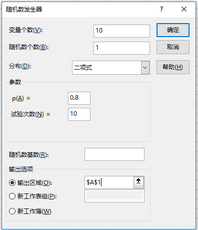
隨機(jī)數(shù)發(fā)生器對話框的二項(xiàng)分布設(shè)置
單擊“確定”生成隨機(jī)數(shù)如下:

產(chǎn)生的二項(xiàng)分布隨機(jī)數(shù)
3.5 產(chǎn)生泊松分布隨機(jī)數(shù)
泊松:以值 λ 來表征��,λ 等于平均值的倒數(shù)�����。泊松分布經(jīng)常用于表示單位時(shí)間內(nèi)事件發(fā)生的次數(shù)�,例如,汽車到達(dá)收費(fèi)停車場的平均速率���。其描述如下:
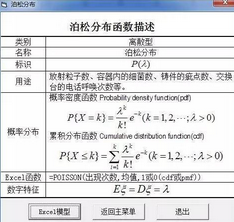
泊松分布描述
例:某加油站�����,平均每小時(shí)前來加油的車輛為10輛��,試進(jìn)行100次模擬�����,并求其分布情況�。
隨機(jī)數(shù)發(fā)生器選擇“分布”為“泊松”,設(shè)置對話框如下:
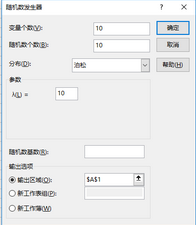
隨機(jī)數(shù)發(fā)生器對話框的泊松分布設(shè)置
單擊“確定”生成隨機(jī)數(shù)如下:
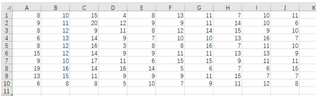
產(chǎn)生的泊松分布隨機(jī)數(shù)
求得最大值����,最小值,確定組限�,利用frequency函數(shù)統(tǒng)計(jì)頻數(shù),并求頻率如下圖�。選擇P2:P10單元格區(qū)域,在P2單元格輸入公式“=FREQUENCY(A1:J10,O2:O10)”,同時(shí)按ctrl+shift+enter:
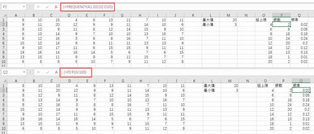
頻數(shù)統(tǒng)計(jì)
3.6 產(chǎn)生重復(fù)序列
模式:以下界和上界�、步幅�、數(shù)值的重復(fù)率和序列的重復(fù)率來表征。在生物遺傳學(xué)中常用到重復(fù)序列��。EXCEL的“模式”所產(chǎn)生的重復(fù)序列是按相同步長產(chǎn)生的重復(fù)序列���。
如:下列對話框設(shè)置:
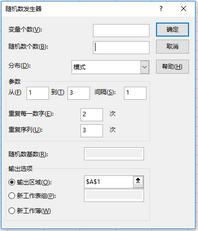
重復(fù)序列對話框
可產(chǎn)生的重復(fù)序列為:112233112233112233
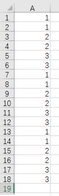
3.7 產(chǎn)生離散隨機(jī)數(shù)
離散:以數(shù)值及相應(yīng)的概率區(qū)域來表征����。該區(qū)域必須包含兩列,左邊一列包含數(shù)值���,右邊一列為與該行中的數(shù)值相對應(yīng)的發(fā)生概率�。所有概率的和必須為 1�����。
例如:某商品銷售情況根據(jù)某段時(shí)期統(tǒng)計(jì)如下(經(jīng)驗(yàn)分布):

試進(jìn)行80次模擬��。
(1)在A列和B列輸入?yún)?shù)(經(jīng)驗(yàn)分布)
(2)隨機(jī)數(shù)發(fā)生器選擇“離散”���,設(shè)置如下:
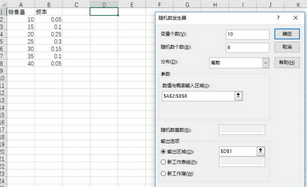
離散分布對話框
(3)單擊確定����,在C1:M8產(chǎn)生80個隨機(jī)數(shù)����。
(4)對產(chǎn)生的隨機(jī)數(shù)利用frequency函數(shù)統(tǒng)計(jì)頻數(shù),并求頻率(略)�。
二、抽樣
“抽樣”分析工具以數(shù)據(jù)源區(qū)域?yàn)榭傮w�,從而為其創(chuàng)建一個樣本���。當(dāng)總體太大而不能進(jìn)行處理或繪制時(shí),可以選用具有代表性的樣本����。如果確認(rèn)數(shù)據(jù)源區(qū)域中的數(shù)據(jù)是周期性的,還可以僅對一個周期中特定時(shí)間段中的數(shù)值進(jìn)行采樣���。例如����,如果數(shù)據(jù)源區(qū)域包含季度銷售量數(shù)據(jù)�,則以四為周期進(jìn)行采樣,將在輸出區(qū)域中生成與數(shù)據(jù)源區(qū)域中相同季度的數(shù)值���。
1.隨機(jī)抽樣
(1)打開一張工作表��,輸入總體編號或總體標(biāo)志值(本例A2:J11單元格區(qū)域���,使用“填充”-“序列”可以快速生成該區(qū)域)�。
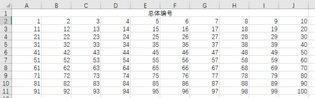
隨機(jī)抽樣
(2)抽樣對話框設(shè)置:
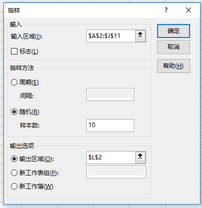
隨機(jī)抽樣對話框設(shè)置
單擊“確定”生成隨機(jī)樣本。注意��,該樣本是可重復(fù)抽樣,重復(fù)率與總體單位數(shù)成反比����,與樣本量成正比。
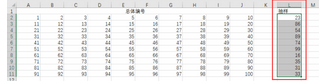
2.周期抽樣
例:從1至10編號按固定周期間隔分別為2�、3、4����、5抽樣。
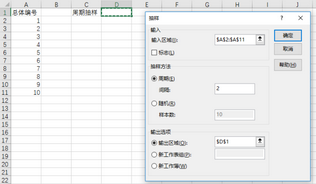
周期抽樣對話框設(shè)置
單擊“確定”抽得樣本(D列)����,取間隔依次取3、4�、5,輸出區(qū)域依次改為E2�、F2、G2�,得隨機(jī)數(shù)如圖。

周期抽取的樣本
該種抽樣類似等距抽樣����,但不同的是統(tǒng)計(jì)學(xué)中的等距抽樣是在第1組進(jìn)行簡單隨機(jī)抽樣,以后的樣本等于首樣本位置依次加組距的k倍����。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試����,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情��;
? 想學(xué)習(xí)CDA考試教材�����,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330