如何將連續(xù)變量創(chuàng)建為變量
要創(chuàng)建分類變量inccat:
從數(shù)據(jù)編輯器窗口的菜單中選擇:
轉(zhuǎn)換> 可視離散化...
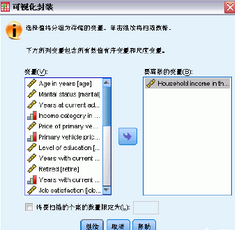
在初始的“可視離散化”對話框中,選擇要為其創(chuàng)建新的離散化變量的刻度變量和/或 有序變量�����。離散化是指取兩個或多個連續(xù)值并將其分組為同一類別���。
由于可視離散化依賴于數(shù)據(jù)文件中的實際值以幫助您做出良好的離散化選擇,因
而其需要先讀取數(shù)據(jù)文件���。如果您的數(shù)據(jù)文件包含大量個案���,則完成此過程將需要一
段時間,因此��,這一初始對話框還允許您限制要讀?�。ā皰呙琛保┑膫€案數(shù)�����。我們 的樣本數(shù)據(jù)文件不需要此限制�����。盡管此數(shù)據(jù)文件包含6,000
多個案,但掃描這些 個案不需要太長時間����。
將Household income in thousands [income] 從“變量”列表中拖放到“要離散的變量”列表中,然后單擊繼續(xù)��。
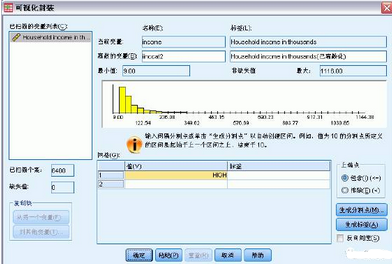
在“可視離散化”主對話框中����,選擇“已掃描的變量列表”中的Household income in
thousands [income]。直方圖顯示了所選變量的分布(在此例中����,分布嚴重偏斜)。
輸入inccat2 作為新的離散化變量名稱����,輸入Income category [in thousands] 作
為變量標簽。
單擊生成分割點���。
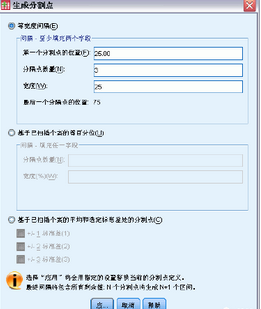
選擇等寬度間隔��。
輸入25 作為第一個分割點的位置�����,輸入3 作為分割點數(shù)量��,并輸入25 作為寬度�。離散化類別的數(shù)量比分割點數(shù)量多一個。因此在本示例中���,新的離散化變量將具有四個類別,其中前三個類別中每個包含的范圍為25(千)�,最后一個類別包含最高割點值75(千)以上的所有值。
單擊應用�����。
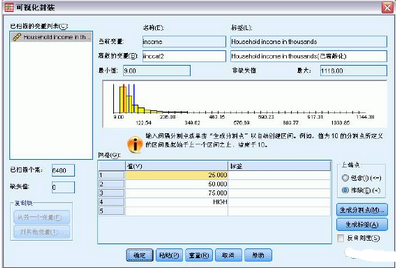
網(wǎng)格中當前顯示的值表示所定義的分割點����,這些分割點是每個類別的上端點。直方圖中的垂直線還指示了各分割點的位置�����。
默認情況下�����,這些分割點值將包含在相應的類別中。例如�����,第一個值25 將包含所有小于或等于25 的值�。但在本示例中,我們希望這些類別對應于小于25���、25–49���、50–74 以及75 或更高。
在上端點組中�,選擇排除(<)。
然后單擊生成標簽���。
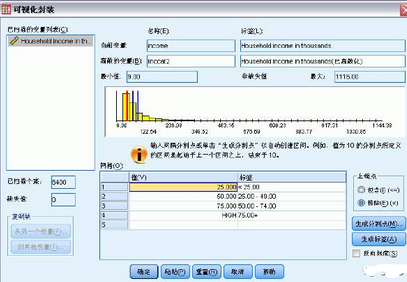
這將自動為每個類別生成描述性值標簽�。由于為新的離散化變量指定的實際值只是從1開始的連續(xù)整數(shù)��,因此這些值標簽可能非常有用��。還可以在網(wǎng)格中手動輸入或更改分割點和標簽����,通過在直方圖中拖放分割點線來更改分割點位置以及通過將分割點線拖出直方圖來刪除分割點����。數(shù)據(jù)分析師培訓
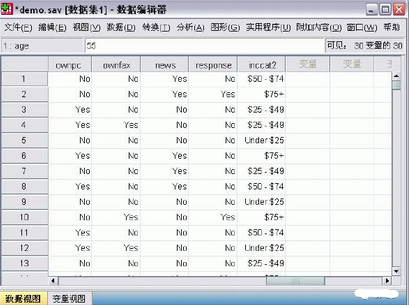
單擊確定以創(chuàng)建新的離散化變量���。
新變量將顯示在數(shù)據(jù)編輯器中���。由于該變量將添加到文件的末尾,因此顯示在數(shù)據(jù)視圖的最右側(cè)一列���,變量視圖的最后一行中。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認證考試��,點擊>>>
“CDA報名”
了解CDA考試詳情��;
? 想學習CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫�,點擊>>> “CDA題庫” 了解CDA考試詳情;
? 想了解CDA考試含金量�����,點擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330