數(shù)據(jù)挖掘:手把手教你做文本挖掘
1文本挖掘定義
文本挖掘指的是從文本數(shù)據(jù)中獲取有價值的信息和知識,它是數(shù)據(jù)挖掘中的一種方法��。文本挖掘中最重要最基本的應(yīng)用是實現(xiàn)文本的分類和聚類,前者是有監(jiān)督的挖掘算法���,后者是無監(jiān)督的挖掘算法���。
2文本挖掘步驟
1)讀取數(shù)據(jù)庫或本地外部文本文件
2)文本分詞
2.1)自定義字典
2.2)自定義停止詞
2.3)分詞
2.4)文字云檢索哪些詞切的不準(zhǔn)確�����、哪些詞沒有意義�,需要循環(huán)2.1���、2.2和 2.3步驟
3)構(gòu)建文檔-詞條矩陣并轉(zhuǎn)換為數(shù)據(jù)框
4)對數(shù)據(jù)框建立統(tǒng)計��、挖掘模型
5)結(jié)果反饋
3文本挖掘所需工具
本次文本挖掘將使用R語言實現(xiàn)��,除此還需加載幾個R包����,它們是tm包��、tmcn包����、Rwordseg包和wordcloud包�。
4實戰(zhàn)
本文對該數(shù)據(jù)集做了整合,將各個主題下的新聞匯總到一張csv表格中��,數(shù)據(jù)格式如下圖所示:
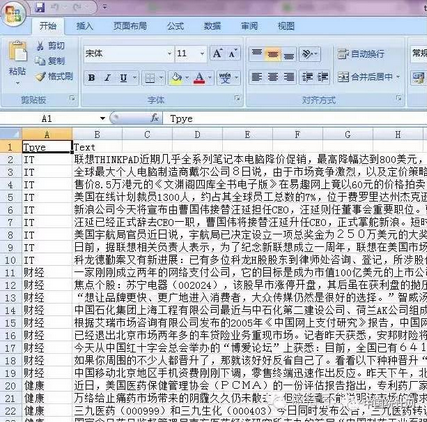
具體數(shù)據(jù)可至文章后面的鏈接�����。
#加載所需R包
library(tm)
library(Rwordseg)
library(wordcloud)
library(tmcn)
#讀取數(shù)據(jù)
mydata <- read.table(file = file.choose(), header = TRUE, sep = ',', stringsAsFactors = FALSE)
str(mydata)
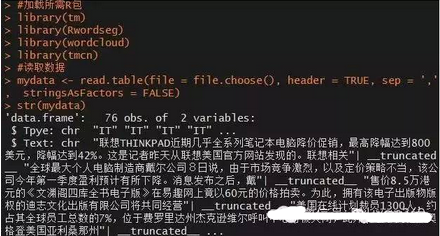
接下來需要對新聞內(nèi)容進行分詞,在分詞之前需要導(dǎo)入一些自定義字典�����,目的是提高切詞的準(zhǔn)確性�。由于文本中涉及到軍事、醫(yī)療��、財經(jīng)�、體育等方面的內(nèi)容,故需要將搜狗字典插入到本次分析的字典集中����。
#添加自定義字典
installDict(dictpath = 'G:\\dict\\財經(jīng)金融詞匯大全【官方推薦】.scel',
dictname = 'Caijing', dicttype = 'scel')
installDict(dictpath = 'G:\\dict\\軍事詞匯大全【官方推薦】.scel',
dictname = 'Junshi', dicttype = 'scel')
installDict(dictpath = 'G:\\dict\\籃球【官方推薦】.scel',
dictname = 'Lanqiu', dicttype = 'scel')
installDict(dictpath = 'G:\\dict\\旅游詞匯大全【官方推薦】.scel',
dictname = 'Lvyou', dicttype = 'scel')
installDict(dictpath = 'G:\\dict\\汽車詞匯大全【官方推薦】.scel',
dictname = 'Qiche1', dicttype = 'scel')
installDict(dictpath = 'G:\\dict\\汽車頻道專用詞庫.scel',
dictname = 'Qiche2', dicttype = 'scel')
installDict(dictpath = 'G:\\dict\\醫(yī)學(xué)詞匯大全【官方推薦】.scel',
dictname = 'Yixue', dicttype = 'scel')
installDict(dictpath = 'G:\\dict\\足球【官方推薦】.scel',
dictname = 'Zuqiu', dicttype = 'scel')
#查看已安裝的詞典
listDict()
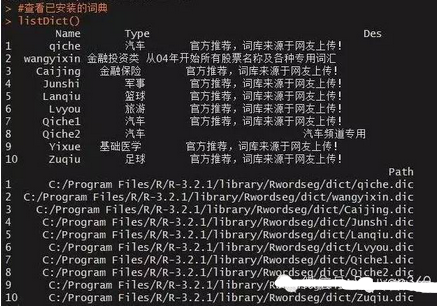
如果需要卸載某些已導(dǎo)入字典的話,可以使用uninstallDict()函數(shù)�����。
分詞前將中文中的英文字母統(tǒng)統(tǒng)去掉�����。
#剔除文本中含有的英文字母
mydata$Text <- gsub('[a-zA-Z]','',mydata$Text)
#分詞
segword <- segmentCN(strwords = mydata$Text)
#查看第一條新聞分詞結(jié)果
segword[[1]]
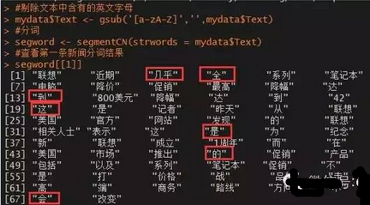
圖中圈出來的詞對后續(xù)的分析并沒有什么實際意義,故需要將其剔除�����,即刪除停止詞�。
#創(chuàng)建停止詞
mystopwords <- read.table(file = file.choose(), stringsAsFactors = FALSE)
head(mystopwords)
class(mystopwords)
#需要將數(shù)據(jù)框格式的數(shù)據(jù)轉(zhuǎn)化為向量格式
mystopwords <- as.vector(mystopwords[,1])
head(mystopwords)
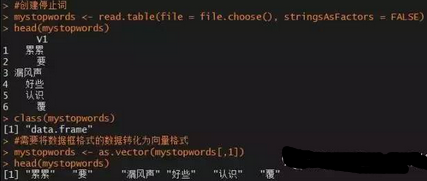
停止詞創(chuàng)建好后,該如何刪除76條新聞中實際意義的詞呢�����?下面通過自定義刪除停止詞的函數(shù)加以實現(xiàn)����。
#自定義刪除停止詞的函數(shù)
removewords <- function(target_words,stop_words){
target_words = target_words[target_words%in%stop_words==FALSE]
return(target_words)
}
segword2 <- sapply(X = segword, FUN = removewords, mystopwords)
#查看已刪除后的分詞結(jié)果
segword2[[1]]
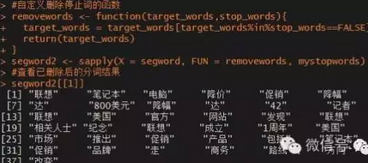
相比與之前的分詞結(jié)果,這里瘦身了很多�����,剔除了諸如“是”�、“的”、“到”�����、“這”等無意義的次����。
判別分詞結(jié)果的好壞,最快捷的方法是繪制文字云��,可以清晰的查看哪些詞不該出現(xiàn)或哪些詞分割的不準(zhǔn)確�。
#繪制文字圖
word_freq <- getWordFreq(string = unlist(segword2))
opar <- par(no.readonly = TRUE)
par(bg = 'black')
#繪制出現(xiàn)頻率最高的前50個詞
wordcloud(words = word_freq$Word, freq = word_freq$Freq, max.words = 50, random.color = TRUE, colors = rainbow(n = 7))
par(opar)

很明顯這里仍然存在一些無意義的詞(如說、日��、個����、去等)和分割不準(zhǔn)確的詞語(如黃金周切割為黃金,醫(yī)藥切割為藥等)���,這里限于篇幅的原因�����,就不進行再次添加自定義詞匯和停止詞���。
#將已分完詞的列表導(dǎo)入為語料庫,并進一步加工處理語料庫
text_corpus <- Corpus(x = VectorSource(segword2))
text_corpus
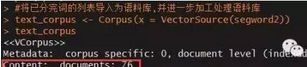
此時語料庫中存放了76條新聞的分詞結(jié)果。
#去除語料庫中的數(shù)字
text_corpus <- tm_map(text_corpus, removeNumbers)
#去除語料庫中的多余空格
text_corpus <- tm_map(text_corpus, stripWhitespace)
#創(chuàng)建文檔-詞條矩陣
dtm <- DocumentTermMatrix(x = text_corpus, control = list(wordLengths = c(2,Inf)))
dtm
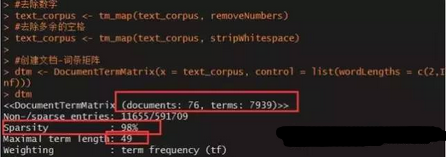
從圖中可知��,文檔-詞條矩陣包含了76行和7939列�����,行代表76條新聞,列代表7939個詞��;該矩陣實際上為稀疏矩陣���,其中矩陣中非0元素有11655個���,而0元素有591709,稀疏率達(dá)到98%����;最后,這7939個詞中��,最頻繁的一個詞出現(xiàn)在了49條新聞中�����。
由于稀疏矩陣的稀疏率過高��,這里將剔除一些出現(xiàn)頻次極地的詞語��。
#去除稀疏矩陣中的詞條
dtm <- removeSparseTerms(x = dtm, sparse = 0.9)
dtm
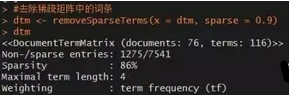
這樣一來��,矩陣中列大幅減少,當(dāng)前矩陣只包含了116列�����,即116個詞語�。
為了便于進一步的統(tǒng)計建模�����,需要將矩陣轉(zhuǎn)換為數(shù)據(jù)框格式�。
#將矩陣轉(zhuǎn)換為數(shù)據(jù)框格式
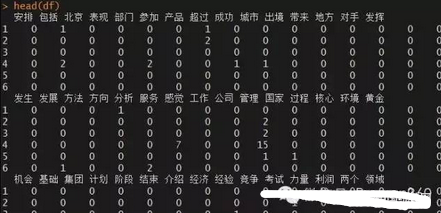
df <- as.data.frame(inspect(dtm))
#查看數(shù)據(jù)框的前6行(部分)
head(df)
統(tǒng)計建模:聚類分析
聚類分析是文本挖掘的基本應(yīng)用,常用的聚類算法包括層次聚類法�����、劃分聚類法�、EM聚類法和密度聚類法。
這里使用層次聚類中的McQuitty相似分析法實現(xiàn)新聞的聚類�����。
#計算距離
d <- dist(df)
#層次聚類法之McQuitty相似分析法
fit1 <- hclust(d = d, method = 'mcquitty')
plot(fit1)
rect.hclust(tree = fit1, k = 7, border = 'red')
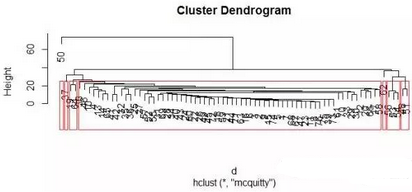
這里的McQuitty層次聚類法效果不理想���,類與類之間分布相當(dāng)不平衡,我想可能存在三種原因:
1)文章的主干關(guān)鍵詞出現(xiàn)頻次不夠���,使得文章沒能反映某種主題�����;
2)分詞過程中沒有剔除對建模不利的干擾詞����,如中國�����、美國���、公司����、市場��、記者等詞語����;
3)沒能夠準(zhǔn)確分割某些常用詞,如黃金周����。
5總結(jié)
所以在實際的文本挖掘過程中��,最為困難和耗費時間的就是分詞部分�,既要準(zhǔn)確分詞�����,又要剔除無意義的詞語����,這對文本挖掘者是一種挑戰(zhàn)����。數(shù)據(jù)分析師培訓(xùn)
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認(rèn)證考試,點擊>>>
“CDA報名”
了解CDA考試詳情�����;
? 想學(xué)習(xí)CDA考試教材�,點擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量�,點擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330