主成分分析法及其在SPSS中的操作
一�、主成分分析基本原理
概念:主成分分析是把原來多個變量劃為少數(shù)幾個綜合指標的一種統(tǒng)計分析方法。從數(shù)學角度來看����,這是一種降維處理技術�。
思路:一個研究對象,往往是多要素的復雜系統(tǒng)���。變量太多無疑會增加分析問題的難度和復雜性���,利用原變量之間的相關關系,用較少的新變量代替原來較多的變量�����,并使這些少數(shù)變量盡可能多的保留原來較多的變量所反應的信息�,這樣問題就簡單化了。
原理:假定有n個樣本��,每個樣本共有p個變量����,構成一個n×p階的數(shù)據(jù)矩陣,
?x11?x21?X??????xn1x12x22?xn2???x1p??x2p????xnp??
記原變量指標為x1��,x2���,?����,xp��,設它們降維處理后的綜合指標��,即新變量為 z1���,z2��,z3��,? ��,zm(m≤p)����,則
系數(shù)lij的確定原則:
①zi與zj(i≠j�����;i����,j=1����,2���,?�����,m)相互無關�����;
②z1是x1��,x2��,?���,xP的一切線性組合中方差最大者,z2是與z1不相關的x1���,x2��,?�����,xP的所有線性組合中方差最大者�����; zm是與z1�����,z2��,??�����,zm-1都不相關的x1�,x2��,?xP ���, 的所有線性組合中方差最大者����。
新變量指標z1,z2�,?,zm分別稱為原變量指標x1�����,x2�,?,xP的第1�,第2,?�����,第m主成分���。
從以上的分析可以看出����,主成分分析的實質(zhì)就是確定原來變量xj(j=1�����,2
,?�, p)在諸主成分zi(i=1,2�,?,m)上的荷載 lij( i=1����,2,?�����,m����; j=1��,2 ���,?����,p)��。
?z1?l11x1?l12x2???l1pxp??z2?l21x1?l22x2???l2pxp?............??z?lx?lx???lxm11m22mpp?m
從數(shù)學上可以證明,它們分別是相關矩陣m個較大的特征值所對應的特征向量����。
二、主成分分析的計算步驟 1����、計算相關系數(shù)矩陣
?r11
?r21?R??????rp1
r12r22?rp2
???
r1p?
?r2p
????rpp??
rij(i,j=1���,2���,?,p)為原變量xi與xj的相關系數(shù)���, rij=rji�,其計算公式為
n
rij?
n
?(x
k?1
ki
?i)(xkj?j)
n2
?(x
k?1
ki
?i)
?(x
k?1
kj
?j)
2
2����、計算特征值與特征向量
I? R ?0 ,常用雅可比法(Jacobi)求出特征值�����,并使其按大解特征方程 ?
?1??2????p?0; 小順序排列
p
2
ei(i?1,2,L,p)?i的特征向量 ei
分別求出對應于特征值 �,即? eij?1
j?1
eij表示向量 ei的第j個分量。 其中
3����、計算主成分貢獻率及累計貢獻率
貢獻率:
?i
p
(i?1,2,L,p)
k
i
??
k?1
??
累計貢獻率:
k?1
p
k
(i?1,2,L,p)
k
??
k?1
?1,?2,L,?m所對應的第1、第一般取累計貢獻率達85%-95%的特征值�����,
2���、?、第m(m≤p)個主成分����。 4、計算主成分載荷
lij?p(zi,xj)?
?ieij(i,j?1,2,L,p)
5�����、各主成分得分
?z11?z21?Z?????zn1z12z22?zn2???z1m??z2m????znm?
三���、主成分分析法在SPSS中的操作
1�、指標數(shù)據(jù)選取、收集與錄入(表1)
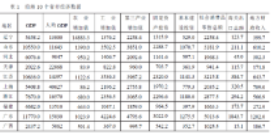
2����、Analyze →Data Reduction →Factor Analysis,彈出Factor Analysis 對話框:
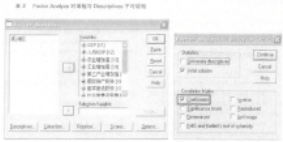
3��、把指標數(shù)據(jù)選入Variables 框��,Descriptives: Correlation Matrix 框組中選中Coefficients,然后點擊Continue, 返回Factor Analysis 對話框���,單擊OK����。
注意:SPSS 在調(diào)用Factor Analyze 過程進行分析時, SPSS 會自動對原始數(shù)據(jù)進行標
準化處理, 所以在得到計算結果后的變量都是指經(jīng)過標準化處理后的變量, 但SPSS 并不直接給出標準化后的數(shù)據(jù), 如需要得到標準化數(shù)據(jù), 則需調(diào)用Descriptives 過程進行計算���。
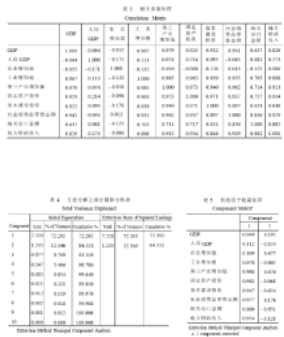
從表3 可知GDP 與工業(yè)增加值, 第三產(chǎn)業(yè)增加值���、固定資產(chǎn)投資、基本建設投資�����、社會消費品零售總額����、地方財政收入這幾個指標存在著極其顯著的關系, 與海關出口總額存在著顯著關系�??梢娫S多變量之間直接的相關性比較強, 證明他們存在信息上的重疊。
主成分個數(shù)提取原則為主成分對應的特征值大于1的前m個主成分�����。特征值在某種程度上可以被看成是表示主成分影響力度大小的指標,
如果特征值小于1, 說明該主成分的解釋力度還不如直接引入一個原變量的平均解釋力度大, 因此一般可以用特征值大于1作為納入標準����。通過表4(
方差分解主成分提取分析) 可知, 提取2個主成分, 即m=2, 從表5( 初始因子載荷矩陣) 可知GDP、工業(yè)增加
值�����、第三產(chǎn)業(yè)增加值��、固定資產(chǎn)投資����、基本建設投資���、社會消費品零售總額��、海關出口總額��、地方財政收入在第一主成分上有較高載荷,
說明第一主成分基本反映了這些指標的信息; 人均GDP 和農(nóng)業(yè)增加值指標在第二主成分上有較高載荷, 說明第二主成分基本反映了人均GDP
和農(nóng)業(yè)增加值兩個指標的信息��。所以提取兩個主成分是可以基本反映全部指標的信息,
所以決定用兩個新變量來代替原來的十個變量�。但這兩個新變量的表達還不能從輸出窗口中直接得到, 因為
“Component Matrix”是指初始因子載荷矩陣, 每一個載荷量表示主成分與對應變量的相關系數(shù)。
用表5(
主成分載荷矩陣) 中的數(shù)據(jù)除以主成分相對應的特征值開平方根便得到兩個主成分中每個指標所對應的系數(shù)����。將初始因子載荷矩陣中的兩列數(shù)據(jù)輸入(
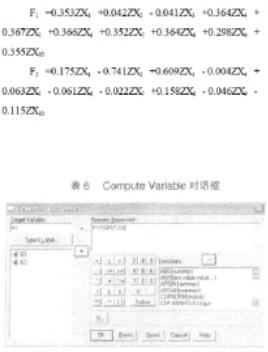
可用復制粘貼的方法) 到數(shù)據(jù)編輯窗口( 為變量B1、B2) , 然后利用“Transform→Compute Variable”,
在Compute Variable對話框中輸入
“A1=B1/SQR(7.22)”[注: 第二主成分SQR后的括號中填1.235,
即可得到特征向量A1(見表6)�。同理, 可得到特征向量A2。將得到的特征向量與標準化后的數(shù)據(jù)相乘, 然后就可以得出主成分表達式[注:
因本例只是為了說明如何在SPSS 進行主成分分析, 故在此不對提取的主成分進行命名, 有興趣的讀者可自行命名��。
標準化:通過Analyze→Descriptive
Statistics→Descriptives 對話框來實現(xiàn): 彈出Descriptives 對話框后, 把X1~X10
選入Variables 框, 在Save standardized values as variables 前的方框打上鉤, 點擊“OK”,
經(jīng)標準化的數(shù)據(jù)會自動填入數(shù)據(jù)窗口中, 并以Z開頭命名��。

以每個主成分所對應的特征值占所提取主成分總的特征值之和的比例作為權重計算主成分綜合模型,
即用第一主成分F1 中每個指標所對應的系數(shù)乘上第一主成分F1 所對應的貢獻率再除以所提取兩個主成分的兩個貢獻率之和, 然后加上第二主成分F2
中每個指標所對應的系數(shù)乘上第二主成分F2 所對應的貢獻率再除以所提取兩個主成分的兩個貢獻率之和, 即可得到綜合得分模型
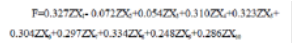
:
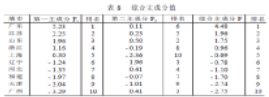
根據(jù)主成分綜合模型即可計算綜合主成分值, 并對其按綜合主成分值進行
排序, 即可對各地區(qū)進行綜合評價比較, 結果見表8�。
CDA數(shù)據(jù)分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試,點擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學習CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫���,點擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量���,點擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330