1�、問(wèn)題與數(shù)據(jù)
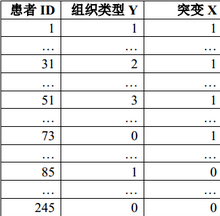
為了探討基因X突變與惡性腫瘤Y不同組織類型發(fā)生風(fēng)險(xiǎn)的關(guān)系�����,某醫(yī)生設(shè)計(jì)了一項(xiàng)病例對(duì)照研究。該醫(yī)生納入所在科室一年收治的145名該惡性腫瘤患者�,并從醫(yī)院體檢數(shù)據(jù)庫(kù)中隨機(jī)選擇了100名未患該腫瘤的體檢者作為對(duì)照���。相關(guān)信息整理成表1:
表1 各病例組織類型與突變情況
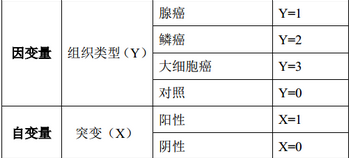
變量賦值情況如表2:
表2 變量及變量賦值情況
2�����、對(duì)數(shù)據(jù)結(jié)構(gòu)的分析
該研究中����,“病例”與“對(duì)照”的關(guān)系不再是簡(jiǎn)單的“患病”與“不患病”�,而是病例分為四類(本例中包含對(duì)照組共四類)���,且各類別無(wú)次序關(guān)系?����;蛘哒f(shuō)����,因變量Y不再是二分類的,而是無(wú)序多分類的���。通過(guò)無(wú)序多分類的Logistic回歸分析可以將三種不同組織類型的病例分別與對(duì)照組進(jìn)行對(duì)比�����,分別得到基因X突變與三種腫瘤組織類型的暴露-風(fēng)險(xiǎn)關(guān)系�����。
3�����、SPSS分析方法
A. 數(shù)據(jù)錄入SPSS
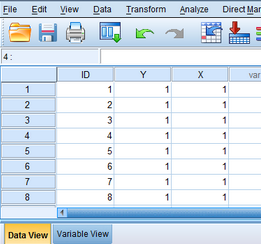
若數(shù)據(jù)格式如表1所示,則首先在SPSS變量視圖(Variable View)中新建三個(gè)變量:ID代表患者編號(hào)�,Y代表組織類型����,X代表是否突變,賦值參考表2.
然后在數(shù)據(jù)視圖(Data View)中錄入數(shù)據(jù)��。
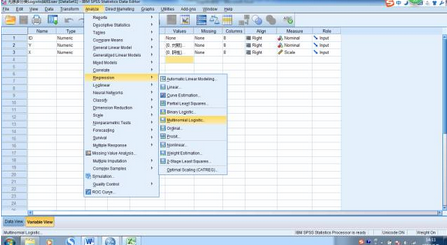
B. 選擇Analyze → Regression → Multinomial Logistic
C. 選項(xiàng)設(shè)置
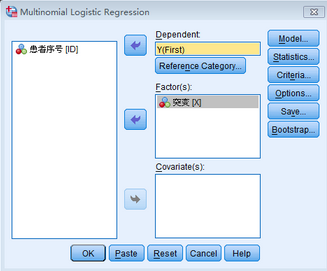
將變量Y選入因變量(Dependent)位置����,變量X選入因子(Factors)位置。如果自變量中還有連續(xù)型變量�,則需要放入?yún)f(xié)變量(Covariate)位置。由于因變量Y有多個(gè)分類����,而無(wú)序多分類Logistic回歸的原理是先指定一個(gè)類別為參考類別�,然后將其他類別分別與參考類別對(duì)比�����。故需點(diǎn)擊Reference
Category設(shè)置參考類別(本例中作為參考類別的為對(duì)照組)��。
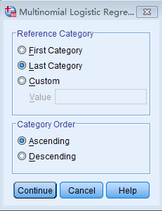
SPSS默認(rèn)選擇因變量賦值中按升序排列后最后類別(即賦值最大者)為參考類別(即對(duì)照組)��,而本研究中參考類別Y賦值為0����,故可以點(diǎn)擊First Category 或直接在Custom中輸入0��,點(diǎn)擊Continue��。
如果要分析的自變量不止一個(gè)��,且要分析不同自變量之間的交互作用�����,則需點(diǎn)擊Model進(jìn)行設(shè)置�����,否則無(wú)需進(jìn)行設(shè)置。
Statistics��、Criteria等維持默認(rèn)設(shè)置即可��。點(diǎn)擊OK�����,SPSS生成分析結(jié)果����。
4、結(jié)果解讀
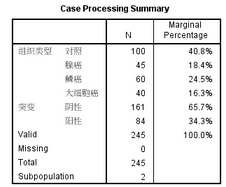
Case Processing Summary 對(duì)數(shù)據(jù)進(jìn)行了總結(jié)��。
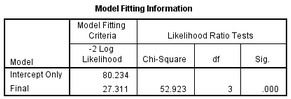
Model
Fitting Information 給出的模型擬合好壞的信息��。其中-2Log
Likelihood值越小越好�,從結(jié)果中可以看出,加入自變量后的模型比只有常數(shù)項(xiàng)的模型擬合要好(27.311<80.234)���,似然比檢驗(yàn)(Likelihood
Ratio Tests)結(jié)果顯示這種模型的改善是有統(tǒng)計(jì)學(xué)意義的(P<0.001)��,說(shuō)明自變量X的加入是有統(tǒng)計(jì)學(xué)意義的���。
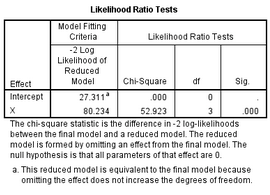
Likelihood Ratio Tests 與Model Fitting Information給出的信息一致��,不再贅述����。
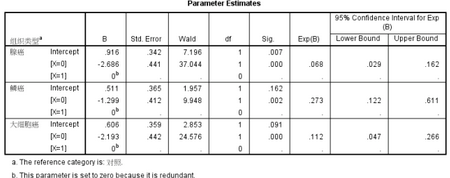
Parameter Estimates表格給出了參數(shù)估計(jì)值�。首先在表格的注釋a說(shuō)明了此次回歸所使用的參考類別為“對(duì)照”,即數(shù)據(jù)中的對(duì)照組�����。表中給出了三種組織類型腫瘤分別與對(duì)照相比的自變量X的回歸系數(shù)�����,且三個(gè)系數(shù)均有統(tǒng)計(jì)學(xué)意義��。
以腺癌組為例���,X=0相比于X=1,系數(shù)值Exp(B)為0.068���,說(shuō)明基因X未突變者患腺癌的風(fēng)險(xiǎn)是突變者患腺癌風(fēng)險(xiǎn)的0.068倍����,將0.068取倒數(shù)即為基因X突變者患腺癌風(fēng)險(xiǎn)是未突變者的1/0.068=14.71倍,P(Sig.)<0.001�,說(shuō)明差異有統(tǒng)計(jì)學(xué)意義。其他兩組系數(shù)解釋同����。如果想直接得到X=1 對(duì)比 X=0的結(jié)果,可以將自變量X當(dāng)作協(xié)變量放入Covariate中�����,而不作為因子進(jìn)行分析�����?�;蛘邔⒆宰兞糠催^(guò)來(lái)�����,如突變陽(yáng)性時(shí)�����,X=0;突變陰性時(shí)�,X=1。
5�、結(jié)果匯總
基因X突變患者相比于未突變患者,其發(fā)生某惡性腫瘤類型為腺癌��、鱗癌和大細(xì)胞癌的風(fēng)險(xiǎn)分別為14.71(1/0.068��,P<0.001)��,3.66(1/0.273��,P=0.002)��,8.93(1/0.112�����,P<0.001)倍�����,均有統(tǒng)計(jì)學(xué)意義�。
6���、總結(jié)與拓展
1)SPSS結(jié)果中會(huì)給出Pseudo R-Square�,即偽R方,或假R方����,與普通線性回歸中衡量模型擬合好壞的R方概念類似。但由于Logistic回歸中因變量為分類變量�,其計(jì)算方法與普通線性回歸中的R方不同,其值一般較小����,可不予關(guān)注。
2)無(wú)序多分類Logistic回歸并非只用于病例對(duì)照研究中�,只要分析時(shí)指定對(duì)照,且與指定的對(duì)照進(jìn)行比較得出的回歸結(jié)果可以說(shuō)明想探究的問(wèn)題即可�。如在本研究中,若研究者關(guān)注的不是基因X突變對(duì)不同類別的腫瘤發(fā)生的風(fēng)險(xiǎn)情況����,而是基因X突變對(duì)三種類別腫瘤的發(fā)生風(fēng)險(xiǎn)是否有差異,以及差異的大小�,那么就不需要納入對(duì)照。
在本例分析中雖然我們可以在數(shù)值上看出基因X突變對(duì)三種類別腫瘤的發(fā)生風(fēng)險(xiǎn)是不同的�,但無(wú)法從統(tǒng)計(jì)學(xué)上進(jìn)行判斷,因?yàn)檫@種差異并沒(méi)有進(jìn)行統(tǒng)計(jì)學(xué)檢驗(yàn)。要探討這種差異�����,可以將參考類別選為三種類別腫瘤中的一中��,如想比較腺癌和鱗癌的差異���,則可選鱗癌組為對(duì)照����,這樣得出的回歸系數(shù)即為基因X突變引起兩種類別腫瘤發(fā)生風(fēng)險(xiǎn)的比值���。
3)實(shí)際應(yīng)用中可能也需要調(diào)整一些混雜因素變量���,若變量為分類型變量則放入因子位置,若為連續(xù)型變量則放入?yún)f(xié)變量位置��,其分析和解釋與要分析的暴露變量是一致的�����。
4)可以把無(wú)序多分類Logistic回歸看作是多個(gè)二分類Logistic回歸的同時(shí)實(shí)現(xiàn)�����。
7�、無(wú)序多分類Logistic回歸適用條件
1)不限于病例對(duì)照類型;
2)因變量為分類變量����,分類大于兩個(gè),且各分類之間并無(wú)次序關(guān)系���。
來(lái)CDA學(xué)業(yè)務(wù)數(shù)據(jù)分析師�����,SPSS理論結(jié)合實(shí)戰(zhàn)進(jìn)行項(xiàng)目數(shù)據(jù)分析����,助你成為從事數(shù)據(jù)采集�、清洗、處理����、分析并能制作業(yè)務(wù)報(bào)告、提供決策的新型數(shù)據(jù)分析人才����,點(diǎn)擊了解課程詳情����!
數(shù)據(jù)分析師一定要了解的大廠入門券���,CDA數(shù)據(jù)分析師認(rèn)證證書(shū)�!

CDA(數(shù)據(jù)分析師認(rèn)證)���,與CFA相似����,由國(guó)際范圍內(nèi)數(shù)據(jù)科學(xué)領(lǐng)域行業(yè)專家����、學(xué)者及知名企業(yè)共同制定并修訂更新,迅速發(fā)展成行業(yè)內(nèi)長(zhǎng)期而穩(wěn)定的全球大數(shù)據(jù)及數(shù)據(jù)分析人才標(biāo)準(zhǔn)���,具有專業(yè)化����、科學(xué)化�����、國(guó)際化、系統(tǒng)化等特性����。
同時(shí)�����,CDA全?��?荚嚥季趾驼J(rèn)證體系已得到教育部直屬中國(guó)成人教育協(xié)會(huì)及大數(shù)據(jù)專業(yè)委員會(huì)認(rèn)可����,并由為IBM��、華為等提供全球認(rèn)證服務(wù)的Pearson VUE面向全球提供靈活的考試服務(wù)�。
報(bào)名方式
登錄CDA認(rèn)證考試官網(wǎng)注冊(cè)報(bào)名>>點(diǎn)擊報(bào)名
報(bào)名費(fèi)用
Level Ⅰ:1200 RMB
Level Ⅱ:1700 RMB
Level Ⅲ:2000 RMB
考試地點(diǎn)
Level Ⅰ:中國(guó)區(qū)30+省市,70+城市�,250+考場(chǎng),考生可就近考場(chǎng)預(yù)約考試 >看看我所在的地哪里報(bào)名<
Level Ⅱ+Ⅲ:中國(guó)區(qū)30所城市�,北京/上海/天津/重慶/成都/深圳/廣州/濟(jì)南/南京/杭州/蘇州/福州/太原/武漢/長(zhǎng)沙/西安/貴陽(yáng)/鄭州/南寧/昆明/烏魯木齊/沈陽(yáng)/哈爾濱/合肥/石家莊/呼和浩特/南昌/長(zhǎng)春/大連/蘭州>看看我所在的地哪里報(bào)名<
報(bào)考條件
業(yè)務(wù)數(shù)據(jù)分析師 CDA Level I >了解更多<
? 報(bào)考條件:無(wú)要求。
? 考試時(shí)間:隨報(bào)隨考�����。
建模分析師 CDA Level II >了解更多<
? 報(bào)考條件(滿足任一即可):
1、獲得CDA Level Ⅰ認(rèn)證證書(shū)�;
2、本科及以上學(xué)歷�����,需從事數(shù)據(jù)分析相關(guān)工作1年以上����;
3、本科以下學(xué)歷���,需從事數(shù)據(jù)分析相關(guān)工作2年以上�����。
? 考試時(shí)間:
一年四屆 3月�、6月�、9月、12月的最后一個(gè)周六��。
大數(shù)據(jù)分析師 CDA Level II >了解更多<
? 報(bào)考條件(滿足任一即可):
1�����、獲得CDA Level Ⅰ認(rèn)證證書(shū);
2���、本科及以上學(xué)歷����,需從事數(shù)據(jù)分析相關(guān)工作1年以上���;
3、本科以下學(xué)歷���,需從事數(shù)據(jù)分析相關(guān)工作2年以上�����。
? 考試時(shí)間:
一年四屆 3月�����、6月��、9月�、12月的最后一個(gè)周六。
數(shù)據(jù)科學(xué)家 CDA Level III >了解更多<
? 報(bào)考條件(滿足任一即可):
1��、獲得CDA Level Ⅱ認(rèn)證證書(shū)��;
2�、本科及以上學(xué)歷,需從事數(shù)據(jù)分析相關(guān)工作3年以上�;
3、本科以下學(xué)歷���,需從事數(shù)據(jù)分析相關(guān)工作4年以上��。
? 考試時(shí)間:
一年四屆 3月���、6月、9月��、12月的最后一個(gè)周六�����。
(備注:數(shù)據(jù)分析相關(guān)工作不限行業(yè)�,可涉及統(tǒng)計(jì),數(shù)據(jù)分析���,數(shù)據(jù)挖掘��,數(shù)據(jù)庫(kù)����,數(shù)據(jù)管理,大數(shù)據(jù)架構(gòu)等內(nèi)容�。)
——熱門課程推薦:
想學(xué)習(xí)PYTHON數(shù)據(jù)分析與金融數(shù)字化轉(zhuǎn)型精英訓(xùn)練營(yíng),您可以點(diǎn)擊>>>“人才轉(zhuǎn)型”了解課程詳情��;
想從事業(yè)務(wù)型數(shù)據(jù)分析師�,您可以點(diǎn)擊>>>“數(shù)據(jù)分析師”了解課程詳情;
想從事大數(shù)據(jù)分析師��,您可以點(diǎn)擊>>>“大數(shù)據(jù)就業(yè)”了解課程詳情��;
想成為人工智能工程師��,您可以點(diǎn)擊>>>“人工智能就業(yè)”了解課程詳情�����;
想了解Python數(shù)據(jù)分析�����,您可以點(diǎn)擊>>>“Python數(shù)據(jù)分析師”了解課程詳情��;
想咨詢互聯(lián)網(wǎng)運(yùn)營(yíng)�����,你可以點(diǎn)擊>>>“互聯(lián)網(wǎng)運(yùn)營(yíng)就業(yè)班”了解課程詳情�;
想了解更多優(yōu)質(zhì)課程,請(qǐng)點(diǎn)擊>>>
推薦學(xué)習(xí)書(shū)籍
《CDA一級(jí)教材》適合CDA一級(jí)考生備考�����,也適合業(yè)務(wù)及數(shù)據(jù)分析崗位的從業(yè)者提升自我��。完整電子版已上線CDA網(wǎng)校�,累計(jì)已有10萬(wàn)+在讀~

免費(fèi)加入閱讀:https://edu.cda.cn/goods/show/3151?targetId=5147&preview=0
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情���;
? 想學(xué)習(xí)CDA考試教材����,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫(kù)���,點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情;
? 想了解CDA考試含金量���,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330