R語(yǔ)言︱文件讀入�、讀出一些方法羅列(批量xlsx文件����、數(shù)據(jù)庫(kù)�����、文本txt�����、文件夾)
小規(guī)模的讀取數(shù)據(jù)的方法較為簡(jiǎn)單并且多樣�,但是,批量讀取目前看到有以下幾種方法:xlsx包��、RODBC包���、批量轉(zhuǎn)化成csv后讀入��。
R語(yǔ)言中還有一些其他較為普遍的讀入����,比如代碼包,R文件�����,工作空間等�����。
source #讀取R代碼
dget #讀取R文件
load #讀取工作空間
————————————————————————————————
SPSS-STATA格式的讀入包——foreign
讀取其他軟件的格式foreign
install.packages("foreign")
#讀取SPSS stata sas
spss<-read.spss("hsb2.sav",to.data.frame=T)
stata<-read.dta("hsb2.dta")
————————————————————————————————
一�����、小規(guī)模數(shù)據(jù)——簡(jiǎn)單讀入方式
read.table����、write.table 、read.csv ���、write.csv��、readLine(字符型格式常用)�。
常見(jiàn)格式:
[plain] view plain copy
print?在CODE上查看代碼片派生到我的代碼片
read.table(file, header = FALSE, sep = "", quote = "\"'",
dec = ".", skip = 0,
strip.white = FALSE, blank.lines.skip = TRUE,
comment.char = "#")
其中:
file表示要讀取的文件,其中有一種神級(jí)讀入法(file.choose()):
[plain] view plain copy
print?在CODE上查看代碼片派生到我的代碼片
read.table(file.choose())
header來(lái)確定數(shù)據(jù)文件中第一行是不是標(biāo)題��;
sep指定分隔符��,默認(rèn)是空格����;
quote是引號(hào),默認(rèn)就是雙引號(hào)��;
dec是小數(shù)點(diǎn)的表示���,默認(rèn)就是一個(gè)點(diǎn);
skip是確定是否跳過(guò)某些行��;
strip.white確定是否消除空白字符�����;
blank.lines.skip確定是否跳過(guò)空白行�����;
comment.char指定用于表示注釋的引導(dǎo)符號(hào)。
在使用read.table�����、read.csv讀取字符數(shù)據(jù)時(shí)�,會(huì)發(fā)生很多問(wèn)題:
1、問(wèn)題一:Warning message:EOF within quoted string����; 需要設(shè)置quote,read.csv("/..csv",quote = "")���;
2���、問(wèn)題二:出現(xiàn)所有的數(shù)據(jù)被加入了雙引號(hào),比如“你好”�,“睡覺(jué)”;
解決方案:先as.character(x[1:5])��,可以發(fā)現(xiàn)比如”\”你好\”“���,這樣的格式��,就可以用sep = "\""來(lái)解決�����。
其中非結(jié)構(gòu)化數(shù)據(jù)����,在讀入的時(shí)候會(huì)出現(xiàn)很多分隔符的問(wèn)題,
——————————————————————————————————————————————————————————————————
二�����、數(shù)據(jù)庫(kù)讀入——RODBC包
RODBC包中能夠基本應(yīng)付數(shù)據(jù)庫(kù)讀入�。一般數(shù)據(jù)數(shù)據(jù)庫(kù)讀入過(guò)程中主要有:
連接數(shù)據(jù)庫(kù)(odbcConnect)、讀入某張表(sqlFetch)�����、讀某表某指標(biāo)(sqlQuery)�、關(guān)閉連接(close)
還有一些功能:
把R數(shù)據(jù)讀入數(shù)據(jù)庫(kù)(sqlSave)�����、刪除數(shù)據(jù)庫(kù)某表(sqlDrop)
[plain] view plain copy
print?在CODE上查看代碼片派生到我的代碼片
#安裝RODBC包
install.packages("RODBC")
library(RODBC)
mycon<-odbcConnect("mydsn",uid="user",pwd="rply")
#通過(guò)一個(gè)數(shù)據(jù)源名稱(chēng)(mydsn)和用戶(hù)名(user)以及密碼(rply�����,如果沒(méi)有設(shè)置,可以直接忽略)打開(kāi)了一個(gè)ODBC數(shù)據(jù)庫(kù)連接
data(USArrests)
#將R自帶的“USArrests”表寫(xiě)進(jìn)數(shù)據(jù)庫(kù)里
sqlSave(mycon,USArrests,rownames="state",addPK=TRUE)
#將數(shù)據(jù)流保存���,這時(shí)打開(kāi)SQL Server就可以看到新建的USArrests表了
rm(USArrests)
#清除USArrests變量
sqlFetch(mycon, "USArrests" ,rownames="state")
#輸出USArrests表中的內(nèi)容
sqlQuery(mycon,"select * from USArrests")
#對(duì)USArrests表執(zhí)行了SQL語(yǔ)句select�,并將結(jié)果輸出
sqlDrop(channel,"USArrests")
#刪除USArrests表
close(mycon)
#關(guān)閉連接
——————————————————————————————————————————————————————————————————
三��、批量讀取——xlsx包
首先嘗試用R包解決����。即xlsx包。
xlsx包在加載時(shí)容易遇到問(wèn)題�����?��;径际怯捎贘ava環(huán)境未配置好���,或者環(huán)境變量引用失敗。因此要首先配置java環(huán)境��,加載rJava包�����。
百度了一下,網(wǎng)上已有很多解決方案��。我主要是參考這個(gè)帖子���,操作步驟為:
1����、 安裝最新版本的java�����。如果你用的R是64位的�����,請(qǐng)下載64位java���。
下載地址: http://www.java.com/en/download/manual.jsp
要安裝在 C:\Program Files\Java 下面��,win8的尤其小心不要安裝為C:\Program Files(x86)??赡苁荝在讀取路徑時(shí)���,對(duì)x86這樣的文件夾不大好識(shí)別吧,我第一次裝在x86里���,讀取是失敗的���。
2、在R中加載環(huán)境���,即一行代碼�����,路徑要依據(jù)你的java版本做出更改��。
R
Sys.setenv(JAVA_HOME='C:\\Program Files\\Java\\jre1.8.0_45\\')
之后再加載rjava包或者xlsx包就成功了��。
xlsx包加載成功后���,用read.xlsx就可以直接讀取xlsx文件,還可以指定讀取的行和段��,以及第幾個(gè)表��,以及可以保存為xlsx文件,這個(gè)包還是很強(qiáng)大的�。
但是這個(gè)方法存在兩個(gè)問(wèn)題:
1、不是所有的公司電腦都能自由的配置java環(huán)境��。很多人的權(quán)限是受限的�����。而且有些公司內(nèi)部應(yīng)用是在java環(huán)境下配置的�����。就算你找了IT去安裝java�����,但是一些內(nèi)部應(yīng)用可能會(huì)因?yàn)榘姹咎?hào)兼容問(wèn)題而出錯(cuò)����,得小失大。
2�����、用xlsx包讀取數(shù)據(jù),在數(shù)據(jù)量比較小的時(shí)候速度還是比較快的���。但是如果xlsx本身比較大,包含數(shù)據(jù)多�,read.xlsx效率會(huì)很低,不如data.table包的fread讀取快捷以及省內(nèi)存�����。但fread函數(shù)不支持xlsx的讀入�����。��。��。
(參見(jiàn)這篇帖子��,里面對(duì)千萬(wàn)行數(shù)據(jù)�,fread也只用了10秒左右,比常規(guī)的read.table或者read.csv至少省時(shí)一倍)
綜上�����,由于java環(huán)境的復(fù)雜性與兼容度,還有xlsx包本身讀取速度的限制�����,用xlsx包讀取xlsx包的方法�,更適合于:
1、個(gè)人電腦����,自己想怎么玩都無(wú)所謂,或者高大上的Linux, mac環(huán)境
2�����、數(shù)據(jù)量不會(huì)特別大���,而且excel文件很干凈����,需要細(xì)節(jié)的操作
實(shí)際操作案例:
批量寫(xiě)入
[plain] view plain copy
print?在CODE上查看代碼片派生到我的代碼片
#1�、讀取xlsx中所有的sheet表格
#如果像vector一樣定義List?���?——list()函數(shù)來(lái)主動(dòng)定義�,用data.list[[i]]來(lái)賦值
data.list<-list()
for (i in 1:2){
data.list[[i]]=read.xlsx("C1.xlsx",i)
}
批量寫(xiě)出
[plain] view plain copy
print?在CODE上查看代碼片派生到我的代碼片
#3、利用List批量讀出操作
#難點(diǎn):如果構(gòu)造輸出表格的名稱(chēng)——paste來(lái)構(gòu)造名稱(chēng)
flie=list()
xlsxflie=paste(1:2,".xlsx",sep="")
for(i in 1:2){
flie[[i]]=paste("C:/Users/long/Desktop/",xlsxflie[i],sep="")
write.xlsx(data.list2[[i]],file)
}
其中出現(xiàn)了一個(gè)小錯(cuò)誤:Error in file[[i]] : object of type 'closure' is not subsettable
這一錯(cuò)誤是因?yàn)槲覍?xiě)錯(cuò)函數(shù)名字了... file->flie(詳情見(jiàn):http://bbs.pinggu.org/thread-3142627-1-1.html)
主要運(yùn)用了list函數(shù)���,詳情可見(jiàn):R語(yǔ)言︱list用法����、批量讀取���、寫(xiě)出數(shù)據(jù)時(shí)的用法
——————————————————————————————————————————————————————————————————
四、批量讀入XLSX文件——先轉(zhuǎn)換為CSV后讀入
CSV讀入的速度較快��,筆者這邊整理的是一種EXCEL VBA把xlsx先轉(zhuǎn)換為csv���,然后利用read.csv導(dǎo)入的辦法�。
WPS中調(diào)用VBA需要額外下砸一個(gè)插件��,
之后應(yīng)用list.files以L(fǎng)ist方式讀入���。
[plain] view plain copy
print?在CODE上查看代碼片派生到我的代碼片
#lapply讀取法
filenames <- list.files("C:/Users/a.csv", pattern = ".csv",full.names = TRUE) #變成list格式
#沒(méi)有full.names = TRUE�,都會(huì)出現(xiàn)cannot open file: No such file or directory
name=function(x) {
read.csv(x,header=T)
}
datalist <- lapply(filenames,name) #filenames執(zhí)行name函數(shù)
———————————————————————————————————————————————————————————————
五����、批量讀入文件夾中的指定文件(如*.xlsx)
代碼思路:先遍歷文件夾(list.files),然后通過(guò)循環(huán)依次讀寫(xiě)(read.xlsx)。
為什么lsit.files不能直接把完整數(shù)據(jù)讀入文件�?——需要read.xlsx這一步驟
[plain] view plain copy
print?在CODE上查看代碼片派生到我的代碼片
##批量讀入文件夾中的xlsx文件
#如何批量讀取一個(gè)文件夾中的各種txt文件
micepath <- "C:/Users/long/Desktop"
micefiles <- list.files(micepath, pattern = "*.xlsx$", full.names = TRUE)
##文件信息放入list中
files=list()
for (i in 1:2){
files[i]=read.xlsx(micefiles[[i]],header = F,1)
}
——————————————————————————————————————————————————————————————————
五、批量讀入文件夾中的文本文件(*.txt)�����,并生成名稱(chēng)��、文檔數(shù)據(jù)框
——用在情感分析中情感詞的打分?jǐn)?shù)
代碼思路:先遍歷文件夾中所有txt(list.files)���、構(gòu)造文本讀入函數(shù)(read.txt)�����、找文本名字(list.files)�����、然后生成數(shù)據(jù)框(as.data.frame)
[plain] view plain copy
print?在CODE上查看代碼片派生到我的代碼片
##批量讀入txt文件�����,并將文本放入同一個(gè)數(shù)據(jù)框
reviewpath <- "F:/R語(yǔ)言/R語(yǔ)言與文本挖掘/情感分析/數(shù)據(jù)/rawdata/review_sentiment/train2"
completepath <- list.files(reviewpath, pattern = "*.txt$", full.names = TRUE)
######批量讀入文本
read.txt <- function(x) {
des <- readLines(x) #每行讀取
return(paste(des, collapse = "")) #沒(méi)有return則返回最后一個(gè)函數(shù)對(duì)象
}
review <- lapply(completepath, read.txt)
#如果程序警告�,這里可能是部分文件最后一行沒(méi)有換行導(dǎo)致��,不用擔(dān)心。
######list轉(zhuǎn)數(shù)據(jù)框
docname <- list.files(reviewpath, pattern = "*.txt$")
reviewdf <- as.data.frame(cbind(docname, unlist(review)),
stringsAsFactors = F)
其中���,list.files()中���,full.names=T代表讀入文件+信息,full.names=F代表讀入文件名字���。
本代碼來(lái)源于書(shū)《數(shù)據(jù)挖掘之道》情感分析章節(jié)��。
——————————————————————————————————————————————————————————————————
六、excel的xlsx格式讀取——openxlsx包
跟xlsx包可以一拼����,為什么沒(méi)有特別好的excel包,因?yàn)槲④浀能浖婚_(kāi)源�,而且內(nèi)嵌設(shè)置時(shí)長(zhǎng)變化,所以么有一款統(tǒng)一的好函數(shù)包�����,來(lái)進(jìn)行讀取�����。
[html] view plain copy
print?在CODE上查看代碼片派生到我的代碼片
library(openxlsx)
data=read.xlsx("hsb2.xlsx",sheet=1)
——————————————————————————————————————————————————————————————————
七、write.table讀出txt文本
[html] view plain copy
print?在CODE上查看代碼片派生到我的代碼片
write.table(data,"names",
quote = F,row.names = FALSE, col.names = FALSE)
輸出的結(jié)果可能是像excel列表一樣:
[html] view plain copy
print?在CODE上查看代碼片派生到我的代碼片
id names
1 “您好”
2 “格式”
3 “讀取”
所以需要去掉行��、列名���,同時(shí)去掉雙引號(hào)�����。
如果我想得到��,這樣格式的呢:
[html] view plain copy
print?在CODE上查看代碼片派生到我的代碼片
您好 格式 讀取
需要調(diào)整ecol�����,默認(rèn)的ecol="\n"����,就是回車(chē)����,所以會(huì)造成換行,所以需要換成“\r”����,同時(shí)中間需要有空格分開(kāi)��,所以最終ecol="\r\ "用【\+空格】來(lái)表達(dá)空格

———————————————————————————————————————————————————————————————————
八 文件夾讀入
文件夾讀入的方式也挺多的�����。
第一步:獲取文件夾內(nèi)全文件內(nèi)容
兩種函數(shù):dir()以及l(fā)ist.files()
[html] view plain copy
print?在CODE上查看代碼片派生到我的代碼片
dir('C:\\Users\\long\\Desktop\\',pattern = "txt$")
ist.files('C:\\Users\\long\\Desktop\\',pattern = "txt$")
同時(shí)����,可以通過(guò)pattren來(lái)選擇規(guī)定格式的文件內(nèi)容����。
第二步:生成系統(tǒng)路徑
[html] view plain copy
print?在CODE上查看代碼片派生到我的代碼片
> paste("C:\\Users\\long\\Desktop\\","txt")
[1] "C:\\Users\\long\\Desktop\\ txt"
> file.path("C:\\Users\\long\\Desktop","txt")
[1] "C:\\Users\\long\\Desktop/txt"
對(duì)比兩者,一般用paste來(lái)生成系統(tǒng)路徑的時(shí)候�����,在最終結(jié)果�,結(jié)合的地方會(huì)多一個(gè)空格����,當(dāng)然也可以用去空格的方式排除,但是不夠好�����。
所以可以用file.path的方式直接生成,比較方便��,而且絕對(duì)正確�。
————————————————————————————————
應(yīng)用一:R語(yǔ)言中大樣本讀出并生成txt文件
筆者進(jìn)過(guò)分詞處理之后的文本詞量有3億+個(gè)詞,一下子導(dǎo)出成txt馬上電腦就死機(jī)���,報(bào)錯(cuò)內(nèi)存不足的問(wèn)題����。
于是在找各種辦法解決如何生成一整個(gè)TXT文件�。于是就有以下比較簡(jiǎn)單的辦法,可以直接實(shí)現(xiàn)���。
步驟一:先把分詞內(nèi)容拆分成幾個(gè)部分�,輸出成多個(gè)txt文件�����;
步驟二:用windows自帶的CMD里面的指令�����,來(lái)生成特定的TXT文件�。
1���、使用組合鍵“Win + R”打開(kāi)運(yùn)行窗口,輸入“cmd”命令��,進(jìn)入命令行窗口�。
2、在命令行窗口����,進(jìn)入需要合并的Txt文件的目錄,如下圖所示已進(jìn)行“F:\stock”目錄���。
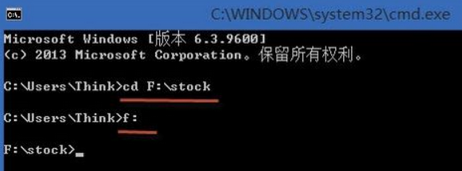
3�、確認(rèn)目錄正確后��,輸入“type *.txt >>f:\111.txt”����,該命令將把當(dāng)前目錄下的所有txt文件的內(nèi)容輸出到f:\111.txt����。
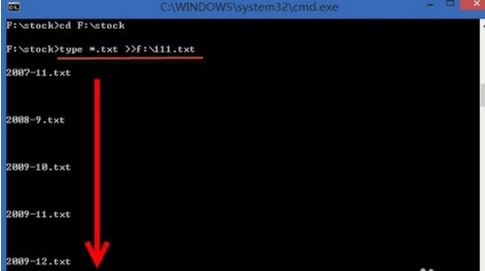
4、到此���,打開(kāi)合并后的f:\111.txt�����,即可看到多個(gè)Txt文件都已按順序合并到F盤(pán)的111.txt文件中�。
————————————————————————————————————————————
應(yīng)用二:R語(yǔ)言中,用write.csv時(shí)候���,用office打開(kāi)��,多出了很多行�����?
如果文本字符長(zhǎng)度很大��,那么就會(huì)出現(xiàn)內(nèi)容串到下面一行的情況��,譬如10行的內(nèi)容�����,可能變成了15行���。好像office默認(rèn)單個(gè)單元格的字符一般不超過(guò)2500字符�,超過(guò)就會(huì)給到下一行�。
所以筆者在導(dǎo)入5W條數(shù)據(jù)時(shí)候,多出了很多行����,于是只能手動(dòng)刪除。
如果用txt格式導(dǎo)出�����,用Notepad++打開(kāi)是好的�,但是用excel打開(kāi)又多出來(lái)不少行,所以用excel打開(kāi)是用代價(jià)的����。
但是由于excel是最好的導(dǎo)入SQL的格式,于是不得不手工刪除���,同時(shí)犧牲一部分的內(nèi)容���。
————————————————————————————————————————————
應(yīng)用三:R語(yǔ)言中,用tcltk讀入時(shí)候��,報(bào)錯(cuò)��?
[html] view plain copy
print?在CODE上查看代碼片派生到我的代碼片
Error: OutOfMemoryError (Java): Java heap space
因?yàn)閺腻e(cuò)誤信息來(lái)看�����,是因?yàn)槟闶褂玫膱?bào)表占用太多內(nèi)存(不夠或者沒(méi)有釋放)��,而導(dǎo)致堆內(nèi)存溢出��。
解決方案從兩個(gè)方面著手�����,1��、加大內(nèi)存如-Xmx1024m���;2����、檢查優(yōu)化代碼及時(shí)釋放內(nèi)存
————————————————————————————————————————————
應(yīng)用四:用R語(yǔ)言來(lái)移動(dòng)圖片文件——file.copy
[html] view plain copy
print?在CODE上查看代碼片派生到我的代碼片
for (i in 1:length(selectname)){
originpath = paste(origin_source,selectname[i],sep = '')
savepath = paste(save_path,selectname[i],sep = '')
file.copy(originpath, save_path)
}
可以看到file.copy是主要用來(lái)做移動(dòng)的函數(shù)����,originpath是路徑名(細(xì)致到文件名稱(chēng)以及后綴)���,savepath可以是文件夾名稱(chēng)。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試���,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情�����;
? 想學(xué)習(xí)CDA考試教材����,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫(kù)��,點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情���;
? 想了解CDA考試含金量�����,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330