R語言數(shù)據(jù)分組統(tǒng)計函數(shù)族—apply族用法與心得
apply族功能強大,實用,可以代替很多循環(huán)語句�����,R語言中不要輕易使用循環(huán)語句����。
apply
Apply Functions Over Array Margins
對陣列行或者列使用函數(shù)
apply(X, MARGIN, FUN, ...)
lapply
Apply a Function over a List or Vector
對列表或者向量使用函數(shù)
lapply(X, FUN, ...)
sapply
Apply a Function over a List or Vector
對列表或者向量使用函數(shù)
sapply(X, FUN, ..., simplify = TRUE, USE.NAMES = TRUE)
vapply
Apply a Function over a List or Vector
對列表或者向量使用函數(shù)
vapply(X, FUN, FUN.VALUE, ..., USE.NAMES = TRUE)
tapply
Apply a Function Over a Ragged Array
對不規(guī)則陣列使用函數(shù)
tapply(X, INDEX, FUN = NULL, ..., simplify = TRUE)
eapply
Apply a Function Over Values in an Environment
對環(huán)境中的值使用函數(shù)
eapply(env, FUN, ..., all.names = FALSE, USE.NAMES = TRUE)
mapply
Apply a Function to Multiple List or Vector Arguments
對多個列表或者向量參數(shù)使用函數(shù)
mapply(FUN, ..., MoreArgs = NULL, SIMPLIFY = TRUE, USE.NAMES = TRUE)
rapply
Recursively Apply a Function to a List
運用函數(shù)遞歸產(chǎn)生列表
rapply(object, f, classes = "ANY", deflt = NULL,how = c("unlist", "replace", "list"), ...)
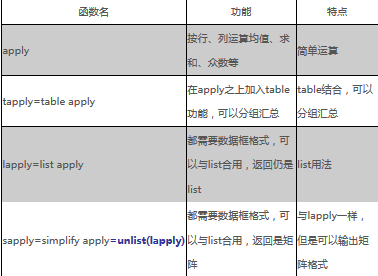
1����、apply函數(shù)
對一個數(shù)組按行或者按列進行計算,矩陣縱�、橫運算(sum,average等)
其中apply中,1等于行�����,2等于列
[plain] view plain copy
print?在CODE上查看代碼片派生到我的代碼片
> ma <- matrix(c(1:4, 1, 6:8), nrow = 2)
> ma
[,1] [,2] [,3] [,4]
[1,] 1 3 1 7
[2,] 2 4 6 8
> apply(ma, c(1,2), sum)
[,1] [,2] [,3] [,4]
[1,] 1 3 1 7
[2,] 2 4 6 8
> apply(ma, 1, sum)
[1] 12 20
> apply(ma, 2, sum)
[1] 3 7 7 15
[plain] view plain copy
print?在CODE上查看代碼片派生到我的代碼片
> tapply(1:17, fac, sum, simplify = FALSE)
$`1`
[1] 51
$`2`
[1] 57
$`3`
[1] 45
$`4`
NULL
$`5`
NULL
> tapply(1:17, fac, range)
$`1`
[1] 1 16
$`2`
[1] 2 17
$`3`
[1] 3 15
$`4`
NULL
$`5`
NULL
2����、tapply
(進行分組統(tǒng)計)
[plain] view plain copy
print?在CODE上查看代碼片派生到我的代碼片
tapply(X, INDEX, FUN = NULL, ..., simplify = TRUE)
#把x在index分類下進行fun
#例:把x在因子分類下�����,進行匯總操作
fac <- factor(rep(1:3, length = 4), levels = 1:5)
fac
[1] 1 2 3 1
Levels: 1 2 3 4 5
tapply(1:4, fac, sum)
1 2 3 4 5
5 2 3 NA NA
#當(dāng)index不是因子時���,可以用as.factor()把參數(shù)強制轉(zhuǎn)換成因子
額外案例,實現(xiàn)excel中數(shù)據(jù)透視表的功能
[plain] view plain copy
print?在CODE上查看代碼片派生到我的代碼片
#利用tapply實現(xiàn)類似于excel里的數(shù)據(jù)透視表的功能:
> da
year province sale
1 2007 A 1
2 2007 B 2
3 2007 C 3
4 2007 D 4
5 2008 A 5
6 2008 C 6
7 2008 D 7
8 2009 B 8
9 2009 C 9
10 2009 D 10
> attach(da)
> tapply(sale,list(year,province)) #以sale為基�����,按照year,province的順序�����,排列
[1] 1 4 7 10 2 8 11 6 9 12
> tapply(sale,list(year,province),mean)
A B C D
2007 1 2 3 4
2008 5 NA 6 7
2009 NA 8 9 10
3���、函數(shù)table(求因子出現(xiàn)的頻數(shù))
[plain] view plain copy
print?在CODE上查看代碼片派生到我的代碼片
使用格式為:
table(..., exclude = if (useNA == "no") c(NA, NaN), useNA = c("no",
"ifany", "always"), dnn = list.names(...), deparse.level = 1)
其中參數(shù)exclude表示哪些因子不計算。
示例代碼:
> d <- factor(rep(c("A","B","C"), 10), levels=c("A","B","C","D","E"))
> d
[1] A B C A B C A B C A B C A B C A B C A B C A B C A B C A B C
Levels: A B C D E
> table(d, exclude="B")
d
A C D E
10 10 0 0
4����、函數(shù)lapply與函數(shù)sapply
每一列數(shù)據(jù)采用同一種函數(shù)形式,比如求X變量得分位數(shù)���,比如求X變量的循環(huán)函數(shù)����。
lapply的使用格式為:
lapply(X, FUN, ...)
lapply的返回值是和一個和X有相同的長度的list對象,
這個list對象中的每個元素是將函數(shù)FUN應(yīng)用到X的每一個元素����。
其中X為List對象(該list的每個元素都是一個向量),
其他類型的對象會被R通過函數(shù)as.list()自動轉(zhuǎn)換為list類型��。
函數(shù)sapply是函數(shù)lapply的一個特殊情形��,對一些參數(shù)的值進行了一些限定��,其使用格式為:
sapply(X, FUN,..., simplify = TRUE, USE.NAMES = TRUE)
sapply(*, simplify = FALSE, USE.NAMES = FALSE) 和lapply(*)的返回值是相同的�。
如果參數(shù)simplify=TRUE,則函數(shù)sapply的返回值不是一個list����,而是一個矩陣;
若simplify=FALSE�����,則函數(shù)sapply的返回值仍然是一個list���。
[plain] view plain copy
print?在CODE上查看代碼片派生到我的代碼片
x <- list(a = 1:10, beta = exp(-3:3), logic = c(TRUE,FALSE,FALSE,TRUE))
> lapply(x, quantile)
$a
0% 25% 50% 75% 100%
1.00 3.25 5.50 7.75 10.00
$beta
0% 25% 50% 75% 100%
0.04978707 0.25160736 1.00000000 5.05366896 20.08553692
$logic
0% 25% 50% 75% 100%
0.0 0.0 0.5 1.0 1.0
> sapply(x, quantile,simplify=FALSE,use.names=FALSE)
$a
0% 25% 50% 75% 100%
1.00 3.25 5.50 7.75 10.00
$beta
0% 25% 50% 75% 100%
0.04978707 0.25160736 1.00000000 5.05366896 20.08553692
$logic
0% 25% 50% 75% 100%
0.0 0.0 0.5 1.0 1.0
[plain] view plain copy
print?在CODE上查看代碼片派生到我的代碼片
#參數(shù)simplify=TRUE的情況
> sapply(x, quantile)
a beta logic
0% 1.00 0.04978707 0.0
25% 3.25 0.25160736 0.0
50% 5.50 1.00000000 0.5
75% 7.75 5.05366896 1.0
100% 10.00 20.08553692 1.0
5�����、函數(shù)mapply
函數(shù)mapply是函數(shù)sapply的變形版�,mapply 將函數(shù) FUN 依次應(yīng)用每一個參數(shù)的第一個元素、第二個元素��、第三個元素上��。函數(shù)mapply的使用格式如下:
mapply(FUN, ..., MoreArgs = NULL, SIMPLIFY = TRUE,USE.NAMES = TRUE)
其中參數(shù)MoreArgs表示函數(shù)FUN的參數(shù)列表���。
[plain] view plain copy
print?在CODE上查看代碼片派生到我的代碼片
> mapply(rep, times=1:4, x=4:1)
[[1]]
[1] 4
[[2]]
[1] 3 3
[[3]]
[1] 2 2 2
[[4]]
[1] 1 1 1 1
#直接使用函數(shù)rep的結(jié)果:
> rep(1:4,1:4)
[1] 1 2 2 3 3 3 4 4 4 4
6�、vapply {base}——按變量進行函數(shù)操作
vapply類似于sapply函數(shù)��,但是它的返回值有預(yù)定義類型����,所以它使用起來會更加安全,有的時候會更快�。
在vapply函數(shù)中總是會進行簡化�,vapply會檢測FUN的所有值是否與FUN.VALUE兼容,
以使他們具有相同的長度和類型�����。類型順序:邏輯、整型��、實數(shù)����、復(fù)數(shù)
vapply(X, FUN, FUN.VALUE, ..., USE.NAMES = TRUE)
X表示一個向量或者表達式對象,其余對象將被通過as.list強制轉(zhuǎn)換為list
simplify 邏輯值或者字符串�����,如果可以���,結(jié)果應(yīng)該被簡化為向量���、矩陣或者高維數(shù)組。
必須是命名的����,不能是簡寫。默認值是TRUE����,若合適將會返回一個向量或者矩陣���。如果simplify=”array”,結(jié)果將返回一個陣列����。
USE.NAMES 邏輯值,如果為TRUE�����,且x沒有被命名��,則對x進行命名���。
FUN.VALUE 一個通用型向量�����,F(xiàn)UN函數(shù)返回值得模板����。
[plain] view plain copy
print?在CODE上查看代碼片派生到我的代碼片
> x<-data.frame(a=rnorm(4,4,4),b=rnorm(4,5,3),c=rnorm(4,5,3))
> vapply(x,mean,c(c=0))
a b c
1.8329043 6.0442858 -0.1437202
[plain] view plain copy
print?在CODE上查看代碼片派生到我的代碼片
> k<-function(x)
+ {
+ list(mean(x),sd(x))
+ }
> vapply(x,k,c(c=0))
錯誤于vapply(x, k, c(c = 0)) : 值的長度必需為1���,
但FUN(X[[1]])結(jié)果的長度卻是2
[plain] view plain copy
print?在CODE上查看代碼片派生到我的代碼片
> vapply(x,k,c(c=0,b=0))
錯誤于vapply(x, k, c(c = 0, b = 0)) : 值的種類必需是'double'����,
但FUN(X[[1]])結(jié)果的種類卻是'list'
[plain] view plain copy
print?在CODE上查看代碼片派生到我的代碼片
> vapply(x,k,c(list(c=0,b=0)))
a b c
c 1.832904 6.044286 -0.1437202
b 1.257834 1.940433 3.649194
sapply與vapply函數(shù)之間的區(qū)別:
[plain] view plain copy
print?在CODE上查看代碼片派生到我的代碼片
> i39 <- sapply(3:9, seq)
> i39
[[1]]
[1] 1 2 3
[[2]]
[1] 1 2 3 4
[[3]]
[1] 1 2 3 4 5
[[4]]
[1] 1 2 3 4 5 6
[[5]]
[1] 1 2 3 4 5 6 7
[[6]]
[1] 1 2 3 4 5 6 7 8
[[7]]
[1] 1 2 3 4 5 6 7 8 9
> sapply(i39, fivenum)
[,1] [,2] [,3] [,4] [,5] [,6] [,7]
[1,] 1.0 1.0 1 1.0 1.0 1.0 1
[2,] 1.5 1.5 2 2.0 2.5 2.5 3
[3,] 2.0 2.5 3 3.5 4.0 4.5 5
[4,] 2.5 3.5 4 5.0 5.5 6.5 7
[5,] 3.0 4.0 5 6.0 7.0 8.0 9
> vapply(i39, fivenum,
+ c(Min. = 0, "1st Qu." = 0, Median = 0, "3rd Qu." = 0, Max. = 0))
[,1] [,2] [,3] [,4] [,5] [,6] [,7]
Min. 1.0 1.0 1 1.0 1.0 1.0 1
1st Qu. 1.5 1.5 2 2.0 2.5 2.5 3
Median 2.0 2.5 3 3.5 4.0 4.5 5
3rd Qu. 2.5 3.5 4 5.0 5.5 6.5 7
Max. 3.0 4.0 5 6.0 7.0 8.0 9
7�����、eapply {base}
eapply函數(shù)通過對environment中命名值進行FUN計算后返回一個列表值�,用戶可以請求所有使用過的命名對象。
eapply(env, FUN, ..., all.names = FALSE, USE.NAMES = TRUE)
env 將被使用的環(huán)境
all.names 邏輯值���,指示是否對所有值使用該函數(shù)
USE.NAMES 邏輯值�,指示返回的列表結(jié)果是否包含命名
[plain] view plain copy
print?在CODE上查看代碼片派生到我的代碼片
> require(stats)
>
> env <- new.env(hash = FALSE) # so the order is fixed
> env$a <- 1:10
> env$beta <- exp(-3:3)
> env$logic <- c(TRUE, FALSE, FALSE, TRUE)
> # what have we there?
> utils::ls.str(env)
a : int [1:10] 1 2 3 4 5 6 7 8 9 10
beta : num [1:7] 0.0498 0.1353 0.3679 1 2.7183 ...
logic : logi [1:4] TRUE FALSE FALSE TRUE
>
> # compute the mean for each list element
> eapply(env, mean)
$logic
[1] 0.5
$beta
[1] 4.535125
$a
[1] 5.5
> unlist(eapply(env, mean, USE.NAMES = FALSE))
[1] 0.500000 4.535125 5.500000
>
> # median and quartiles for each element (making use of "..." passing):
> eapply(env, quantile, probs = 1:3/4)
$logic
25% 50% 75%
0.0 0.5 1.0
$beta
25% 50% 75%
0.2516074 1.0000000 5.0536690
$a
25% 50% 75%
3.25 5.50 7.75
> eapply(env, quantile)
$logic 數(shù)據(jù)分析師培訓(xùn)
0% 25% 50% 75% 100%
0.0 0.0 0.5 1.0 1.0
$beta
0% 25% 50% 75% 100%
0.04978707 0.25160736 1.00000000 5.05366896 20.08553692
$a
0% 25% 50% 75% 100%
1.00 3.25 5.50 7.75 10.00
8�����、rapply {base}
rapply是lapply的遞歸版本
rapply(X, FUN, classes = "ANY", deflt = NULL, how = c("unlist", "replace", "list"), ...)
X 一個列表
classes 關(guān)于類名的字符向量�,或者為any時則匹配任何類
deflt 默認結(jié)果,如果使用了how=”replace”�,則不能使用
how 字符串匹配三種可能結(jié)果
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認證考試,點擊>>>
“CDA報名”
了解CDA考試詳情����;
? 想學(xué)習(xí)CDA考試教材,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫����,點擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量�,點擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330