一個使用R語言做數(shù)據(jù)處理的實(shí)例
最近一個同學(xué)找到我,希望我?guī)兔μ幚硪环?a target="_blank">數(shù)據(jù)。那份數(shù)據(jù)是這樣的:包含了3661行����,第一行為各列的名稱;包含8列���,第一列為專利ID�����,其余7列為企業(yè)ID�����。
這份數(shù)據(jù)截圖如下所示:

一�、問題描述
需要做的數(shù)據(jù)處理是���,求所有專利之間的關(guān)系矩陣��,這里的關(guān)系指的是:當(dāng)同一個企業(yè)同時申請了兩個不同的專利��,那么就認(rèn)為這兩個專利是有關(guān)系的���。也就是說�����,當(dāng)兩個專利對應(yīng)的企業(yè)的集合存在交集�,則認(rèn)為這兩個專利存在關(guān)系�����。需要用矩陣表達(dá)這3660個專利的相互關(guān)系�,有關(guān)系的兩個專利交叉的位置置為1,否則置為0���。
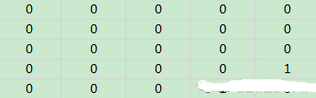
比如���,上圖中的編號4和編號5對應(yīng)的企業(yè)的集合顯然存在交集(交集為94和115),那么最終的關(guān)系矩陣第四行第五列和第五行第四列就應(yīng)當(dāng)用1表示�。如果數(shù)據(jù)就是上邊那樣的,那么最終輸出的關(guān)系矩陣就應(yīng)該為:
二���、問題解決
可能因?yàn)橛卸螘r間沒有使用R了�,加上之前又正好在用awk, grep,
bash這些,所以一直想使用這些工具來解決�。不過,想了很久��,依然進(jìn)展不大(主要是許久不用大多也忘了o(╯□╰)o)���。后來看到壓在桌面上的《R語言實(shí)戰(zhàn)》,想到這里需要的輸出是矩陣�,而且主要的邏輯判定為是否有交集,這些不正是R大展拳腳的地方嗎����?!
于是先用偽代碼將整個邏輯梳理了一遍����,然后照著偽代碼開始寫R腳本。由于邏輯并不復(fù)雜�����,所以很快便寫好了�,代碼如下:
data <- read.csv("C:\\Users\\dell\\Desktop\\data.csv") #讀取數(shù)據(jù)
relation_matrix <- matrix(0, 3660, 3660) #創(chuàng)建一個與源數(shù)據(jù)行數(shù)相等的方陣,所有元素初始化為0
for (i in 1:3660)
for (j in 1:3660) {
company_set1 = data[i, -1][!is.na(data[i, -1])] #讀取第i個專利對應(yīng)的企業(yè)編號集合
company_set2 = data[j, -1][!is.na(data[j, -1])] #讀取第j個專利對應(yīng)的企業(yè)編號集合
#如果第i個專利和第j個專利對應(yīng)的企業(yè)有相同的��,則將對應(yīng)位置置為1
if (i != j && length(intersect(company_set1, company_set2)) > 0)
relation_matrix[i, j] = 1
}
write.csv(relation_matrix_test, "C:\\Users\\dell\\Desktop\\result.csv") #將關(guān)系矩陣寫到文件中
代碼是很快寫好了,不過執(zhí)行速度確慢得難以忍受��。無奈�����,找了個辦法來緩解下焦急等待程序跑完的心情����。到統(tǒng)計(jì)之都找到一個用在循環(huán)里顯示進(jìn)度條的程序改了改,終于好點(diǎn)了�,也大概能算出來程序什么時候能跑完了。
包含顯示進(jìn)度條的程序代碼如下:
data <- read.csv("C:\\Users\\dell\\Desktop\\data.csv") #讀取數(shù)據(jù)
relation_matrix <- matrix(0, 3660, 3660) #創(chuàng)建一個與源數(shù)據(jù)行數(shù)相等的方陣���,所有元素初始化為0
#創(chuàng)建進(jìn)度條pb <- txtProgressBar(min = 0, max = 3660, style = 3)
for (i in 1:3660)
for (j in 1:3660) {
company_set1 = data[i, -1][!is.na(data[i, -1])] #讀取第i個專利對應(yīng)的企業(yè)編號集合
company_set2 = data[j, -1][!is.na(data[j, -1])] #讀取第j個專利對應(yīng)的企業(yè)編號集合
#如果第i個專利和第j個專利對應(yīng)的企業(yè)有相同的��,則將對應(yīng)位置置為1
if (i != j && length(intersect(company_set1, company_set2)) > 0)
relation_matrix[i, j] = 1
#設(shè)置進(jìn)度條
Sys.sleep(0.00001)
setTxtProgressBar(pb, i)
}
write.csv(relation_matrix_test, "C:\\Users\\dell\\Desktop\\result.csv") #將關(guān)系矩陣寫到文件中
顯示效果如下所示:

三��、解決優(yōu)化
雖然比之前好些了�,但還是沒有解決程序運(yùn)行緩慢等待時間過長的問題�。毫無疑問,這段程序肯定還有很大的優(yōu)化空間��,于是先讀取少量的數(shù)據(jù)�,試著使用Rprof分析了一下耗時情況�,結(jié)果發(fā)現(xiàn)[.data.frame 這個操作的耗時占比較大�����,Google搜索后在 這里 找到了一個優(yōu)化的方法�����,即對源數(shù)據(jù)讀取到到data frame之后再拷貝到一個矩陣中做取行的值的操作����。優(yōu)化后的版本:
data <- read.csv("C:\\Users\\dell\\Desktop\\data.csv") #讀取數(shù)據(jù)
relation_matrix <- matrix(0, 3660, 3660)
#創(chuàng)建一個與源數(shù)據(jù)行數(shù)相等的方陣�,所有元素初始化為0data_matrix <- data.matrix(data_test[, -1])
#將數(shù)據(jù)拷貝到一個矩陣中
#創(chuàng)建進(jìn)度條#pb <- txtProgressBar(min = 0, max = 3660, style = 3)
for (i in 1:3660)
for (j in 1:3660) {
company_set1 = data_matrix[i, ][!is.na(data_matrix[i, ])] #讀取第i個專利對應(yīng)的企業(yè)編號集合
company_set2 = data_matrix[j, ][!is.na(data_matrix[j, ])] #讀取第j個專利對應(yīng)的企業(yè)編號集合
#如果第i個專利和第j個專利對應(yīng)的企業(yè)有相同的,則將對應(yīng)位置置為1
if (i != j && length(intersect(company_set1, company_set2)) > 0)
relation_matrix[i, j] = 1
#設(shè)置進(jìn)度條
#Sys.sleep(0.00001)
#setTxtProgressBar(pb, i)
}
write.csv(relation_matrix_test, "C:\\Users\\dell\\Desktop\\result.csv") #將關(guān)系矩陣寫到文件中
在同樣的機(jī)器環(huán)境下�����,改進(jìn)后的程序只需要10min左右�����,而改進(jìn)前的版本則需要將近7個小時���,執(zhí)行效率提高了40倍����!
四、補(bǔ)充
在做這個數(shù)據(jù)處理過程中����,值得記錄的還包括:
R語言程序多個語句的時候記得帶上{},用縮進(jìn)控制是Python的做法�����;
源數(shù)據(jù)讀取之前要簡單校驗(yàn)下����,防止包含異常值影響數(shù)據(jù)讀取的結(jié)果(這里包含了#REF!,處理很久才發(fā)現(xiàn))�����;
在Excel中比較兩份格式完全一樣的數(shù)據(jù)是否相同���,復(fù)制其中一份選擇性粘貼“減”操作到另一份數(shù)據(jù)��,選擇數(shù)據(jù)區(qū)域看右下角顯示的總和是否為0即可�����。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試��,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情�����;
? 想學(xué)習(xí)CDA考試教材���,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫����,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330