互聯(lián)網(wǎng)運營數(shù)據(jù)分析必須掌握的十個經(jīng)典方法
互聯(lián)網(wǎng)運營數(shù)據(jù)分析必須掌握的10個經(jīng)典方法��!用好這10個方法��,秒做互聯(lián)網(wǎng)運營數(shù)據(jù)分析的大牛����!眼花繚亂的東西很多,真正派上用場的����,卻不見得是那些看起來炫酷的。很多方法樸實無華�����,卻解決大量的問題���。
下面十個方法都是我這么多年做互聯(lián)網(wǎng)運營分析時一定會用到的最經(jīng)典的方法�����。這些方法如果爛熟于心��,其實互聯(lián)網(wǎng)運營分析的最核心部分也就掌握差不多了���。真沒那么復雜。
我們從第十個方法倒著講����,重要性并無優(yōu)劣之分,但壓軸的����,往往是最重要的。
方法十:Link Tag的流量標記

Link tag標記流量源頭 ��,絕對是所有方法中最為基本重要的一種����。這種方法不僅僅適用于網(wǎng)站的流量來源,也同樣適用于app下載來源的監(jiān)測(但后者需要滿足一定的條件)���。
Link tag的意思���,是在流量源頭的鏈出鏈接上(鏈出URL上)加上尾部參數(shù)��。這些參數(shù)不僅不會影響鏈接的跳轉�����,而且能夠標明這個鏈接所屬的流量源是什么(理論上能夠標明流量源的屬性數(shù)是無限的)�。
Link tag不能單獨起作用��,必須要在網(wǎng)站分析工具或者app分析工具的配合下工作����。
Link tag是流量分析的基礎,要嚴肅的分析流量���,不僅僅是常規(guī)分析��,還包括歸因分析(attribution analysis)��,都需要使用link tag的方法�。
方法九:轉化漏斗
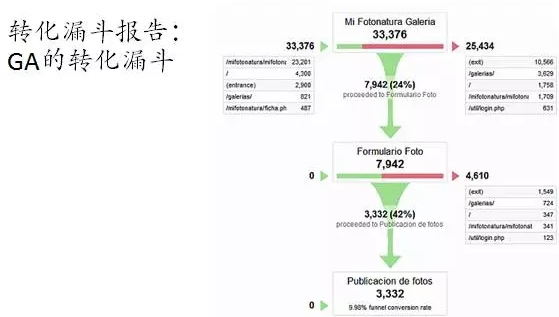
分析轉化的基本模型是轉化漏斗(conversion funnel)����,這個大家都應該很熟悉了。
轉化漏斗最常見的是把最終的轉化設置為某種目的的實現(xiàn)�����,最典型的就是實現(xiàn)銷售�,所以大家很多時候把轉化和銷售是混為一談。但轉化漏斗的最終轉化也可以是其他任何目的的實現(xiàn)����,比如一次使用app的時間超過10分鐘(session duration >10minutes)。對于增長黑客而言���,構建漏斗是最為常見的工作��。
漏斗幫助我們解決兩方面的問題���,第一、在一個過程中是否發(fā)生泄漏�,如果有泄漏,我們能在漏斗中看到����,并且能夠通過進一步的分析堵住這個泄漏點;第二、在一個過程中是否出現(xiàn)了其他不應該出現(xiàn)的過程����,造成轉化主進程受到損害。
漏斗的構建很簡單�����,無論web還是app����,都是最好用的方法之一。但漏斗使用的奧秘則很豐富��。而且漏斗方法還會和其他方法混合使用�,樂趣無窮。我在互聯(lián)網(wǎng)數(shù)據(jù)運營的課程中也會具體講解�。
方法八:微轉化

人人都懂轉化漏斗,但不是所有人都關注微轉化�����。但是你想指望一個轉化漏斗不斷提升轉化率太困難了���,而微轉化卻可以做到��。轉化漏斗解決的是轉化過程中的大問題�����,但大問題總是有限的���,這些問題搞定后,你還是需要對你的轉化進行持續(xù)優(yōu)化�,這個時候必須要用到微轉化。
微轉化是指在轉化必經(jīng)過程之外��,但同樣會對轉化產(chǎn)生影響的各種元素����。這些元素與用戶的互動,左右了用戶的感受�����,也直接或者間接的影響了用戶的決定��。
比如��,商品的一些圖片展示�,并不是轉化過程中必須要看的�,但是它們的存在��,是否會對用戶的購買決定產(chǎn)生影響�?這些圖片就是微轉化元素。
個人認為���,研究微轉化比研究轉化更好玩���。有一些案例,課堂上跟大家講�����。
方法七:合并同類項
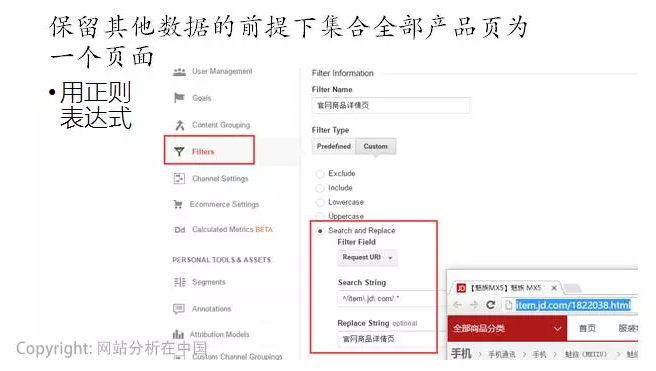
合并同類項是大家容易忽視的常用方法����。我們往往非常重視細分,但有的時候我們卻需要了解更宏觀的表現(xiàn)����。
合并同類項就是這樣的方法。舉一個例子��,我問你����,一個電子商務網(wǎng)站�,所有商品頁的整體表現(xiàn)如何�?它們作為一個整體的bounce rate怎么樣,停留時間怎么樣�,用戶滿意度怎么樣等等,你能夠回答嗎��?
如果我們查看每一個商品頁的表現(xiàn)�����,然后再把所有一個一個頁面的數(shù)據(jù)加總起來作分析��,就太麻煩了(根本無法實現(xiàn)分析)����。這個時候����,我們必須要合并同類項。
如何合并���?利用分析工具的過濾工具或者查找替換功能�。不支持這樣功能的工具你可以考慮扔掉了,因為這根本不應放在增長黑客的專業(yè)裝備箱中���。
合并同類項還有很多用途����,比如你要了解web或者app一個版塊(頻道)的整體表現(xiàn)��,或者你要了解整個導航體系的使用情況�,這都是必須使用的方法。
方法六:AB測試

增長黑客不談AB測試是恥辱���。
通過數(shù)據(jù)優(yōu)化運營和產(chǎn)品的邏輯很簡單——看到問題���,想個主意,做出原型�,測試定型。
比如�����,你發(fā)現(xiàn)轉化漏斗中間有一個漏洞�����,于是你想,一定是商品價格不對頭�,讓大家不想買了。你看到了問題——漏斗�,而且你也想出了主意——改變定價。
但是這個主意靠不靠譜�,可不是你想出來的,必須得讓真實的用戶用����。于是你用AB測試,一部分的用戶還是看到老價格��,另外一部分用戶看到新價格����。若是你的主意真的管用��,新價格就應該有更好的轉化�。若真如此,新的價格就被確定下來(定型)�,開始在新的轉化高度上運行,直到你又發(fā)現(xiàn)一個新的需要改進的問題���。
增長黑客的一個主要思想之一��,是不要做一個大而全的東西��,而是不斷做出能夠快速驗證的小而精的東西����。快速驗證����,如何驗證的?主要方法就是AB測試���。
今天的互聯(lián)網(wǎng)世界����,由于流量紅利時代的結束�,對于快速迭代的要求大大提升了,這也使我們更加在意測試的力量�。
在web上進行AB測試很簡單,在app上難度要高很多���,但解決方法還是很多的��。國外那些經(jīng)典app��,那些賣錢游戲�,幾乎天天都在AB測試。
方法五:熱圖及對比熱圖
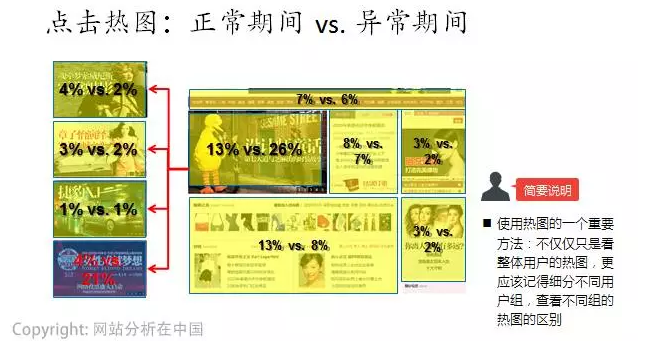
熱圖是一個大家都喜歡的功能����,它是最直觀的記錄用戶與產(chǎn)品界面交互的工具。不過真用起來���,可能大家很少真正去深究吧����!
熱圖��,對于web�����、app的分析��,都非常重要�����!今天的熱圖相對于過去的熱圖���,功能得到了極大的提升�。
在web端��,過去一些解決不好的問題����,比如只能看鏈接的被點擊情況,點擊位置錯位�,對浮層部分點擊的標記,對鏈出鏈接的標記等等���,現(xiàn)在已經(jīng)有好的工具能夠提供很多新的辦法去解決�����。在app端則分為兩種情況��,內(nèi)容類的app�����,對于熱圖的需求較弱��;但工具類的app對于熱圖的需求則很顯著��。前者的screen中以并列內(nèi)容為主�����,且內(nèi)容動態(tài)變換���,熱圖應用價值不高�����;后者則特別需要通過熱圖反映用戶的使用習慣����,并結合app內(nèi)其他的engagement的分析(in-app engagement)來優(yōu)化功能和布局設計��,所以熱圖對它們很重要����。
要想熱圖用的好,一個很重要的點在于你幾乎不能單獨使用一個熱圖就想解決問題�。我常常用集中對比熱圖的方法����。
其一��,多種熱圖的對比分析��,尤其是點擊熱圖(觸摸熱圖)��、閱讀線熱圖�、停屏熱圖的對比分析�����;
其二����,細分人群的熱圖對比分析,例如不同渠道��、新老用戶����、不同時段、AB測試的熱圖對比等等����。
其三��,深度不同的互動���,所反映的熱圖也是不同的。這種情況也值得利用熱圖對比功能�。例如點擊熱圖與轉化熱圖的對比分析等。
總之��,分析很多用戶交互的時候��,熱圖簡直是神器���,只不過�,熱圖真的比你看到的要更強大�����!
方法四:Event Tracking(事件追蹤)
互聯(lián)網(wǎng)運營數(shù)據(jù)分析的一個很重要的基礎是網(wǎng)站分析���。今天的app分析�����、流量分析���、渠道分析,還有后面要講到的歸因分析等等��,都是在網(wǎng)站分析的基礎之上發(fā)展起來的��。
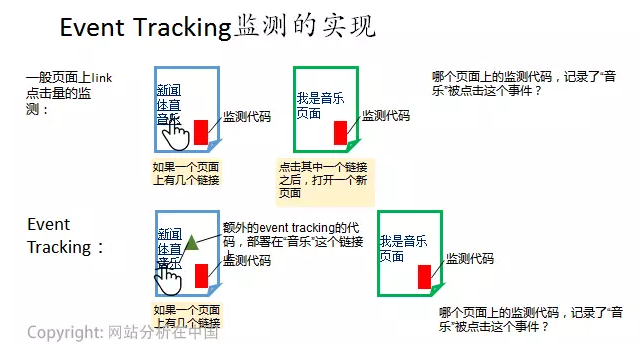
但是�����,早期的網(wǎng)站分析有一個特點����,就是對于用戶在頁面上互動行為的記錄,只能記錄下來一種��,就是點擊http鏈接(點擊URL)����。不過隨著技術的發(fā)展,頁面上不僅僅只有http鏈接����,頁面上還有很多flash(現(xiàn)在flash都要被淘汰了)、Java的互動鏈接�����、視頻播放、鏈接到其他的web或者app的鏈接等等�����,用戶點擊這些東西就都無法被老方法記錄下來了�����。
不過���,有問題就一定有方法����,人們發(fā)明了event tracking來解決上面的問題�����。event tracking本質上是對這些特殊互動的定制化監(jiān)測�,而由于是定制化,所以反而有了更多附加的好處����,即可以額外添加對于這個活動的更多的說明(以event tracking這個方法的附件屬性的方式)�。結果����,這個方法甚至有些反客為主���,即使是一些http鏈接�,很多分析老手也喜歡把它們加上event tracking(技術上完全可行)���,以獲得更多的額外監(jiān)測屬性說明�。
隨著app的出現(xiàn)��,由于app的特殊性(屏幕小���,更強調在一個屏幕中完成互動)���,分析app的page(實際上應該是app的screen)間跳轉的重要性完全不如web上的page之間的跳轉,但分析app上的點擊行為的重要性則十分巨大����,這就使我們分析in-app engagement的時候,必須大量依賴event�,而相對較少使用screen����。這就是說���,在app端����,event反而是主���,page(更準確應該是screen)反而是輔�����!
這也是為什么����,這個方法你必須要掌握的原因��。
方法三:Cohort分析

Cohort分析還沒有一個所有人都統(tǒng)一使用的翻譯���。有的說是隊列分析��,有的說是世代分析����,有的說是隊列時間序列分析。大家可以參考維基百科:https://zh.wikipedia.org/wiki/%E9%98%9F%E5%88%97%E7%A0%94%E7%A9%B6����,找找自己覺得合適的譯名。
無論哪種叫法��,cohort分析在有數(shù)據(jù)運營領域都變得十分重要�。原因在于����,隨著流量經(jīng)濟的退卻,精耕細作的互聯(lián)網(wǎng)運營特別需要仔細洞察留存情況��。Cohort分析最大的價值也正在于此�����。Cohort分析通過對性質完全一樣的可對比群體的留存情況的比較�,來發(fā)現(xiàn)哪些因素影響短、中����、長期的留存��。
Cohort分析受到歡迎的另一個原因是它用起來十分簡單����,但卻十分直觀���。相較于比較繁瑣的流失(churn)分析����,RFM或者用戶聚類等�����,Cohort只用簡單的一個圖表�,甚至連四則運算都不用,就直接描述了用戶在一段時間周期(甚至是整個LTV)的留存(或流失)變化情況��。甚至�����,Cohort還能幫你做預測����。
我總覺得cohort分析是最能體現(xiàn)簡單即美的一個典型方法�。
方法二:Attribution(歸因)

歸因不是人人都聽說過�,用好的更是寥寥無幾。 不過�����,考慮到人們購買某一樣東西的決策�,可能受到多種因素(數(shù)字營銷媒體)的影響,比如看到廣告了解到這個商品的存在����,利用搜索,進一步了解這個商品����,然后在social渠道上看到這個商品的公眾號等等���。這些因素的綜合�����,讓一個人下定了決心購買��。
因此�,很多時候,單一的廣告渠道并不是你打開客戶閘門的閥門����,而是多種渠道共同作用的結果。
如何了解數(shù)字營銷渠道之間的這種先后關系或者相互作用��?如何設置合理的數(shù)字營銷渠道的策略以促進這種關系��?在評價一個渠道的時候�,如何將歸因考慮在內(nèi)從而能夠更客觀的衡量?這些都需要用到歸因�。
如果你是互聯(lián)網(wǎng)營銷的負責人,歸因分析是必不可少的分析方法�����。在我的課堂上����,會特別多的篇幅講解這個方法。
方法一:細分

嚴格說��,細分不是一種方法��,它是一切分析的本源。所以它當之無愧要排名第一����。
我經(jīng)常的口頭禪是,無細分��、毋寧死�����。沒有細分你做什么分析呀��。
細分有兩類���,一類是一定條件下的區(qū)隔�。如:在頁面中停留30秒以上的visit(session)��;或者只要北京地區(qū)的訪客等����。其實就是過濾。另一類是維度(dimension)之間的交叉��。如:北京地區(qū)的新訪問者�。即分群(segmentation)�����。
細分幾乎幫助我們解決所有問題�����。比如����,我們前面講的構建轉化漏斗����,實際上就是把轉化過程按照步驟進行細分。流量渠道的分析和評估也需要大量用到細分的方法��。
維度之間的交叉是比較體現(xiàn)一個人分析水平的細分方法��。比如�����,我的朋友孫維(卡車之家的數(shù)據(jù)負責人)�,他將用戶的反饋作為event tracking的屬性(放在了event action屬性中),提交給GA�����,然后在自定義的報告中,將用戶反饋和用戶的其他行為交叉起來�����,從而看到有某一類反饋的用戶��,他們的行為軌跡是什么�,從而推測發(fā)生了什么問題。
分析跳出率時�,我們也會把landing page和它的traffic source(流量源)進行交叉,以檢查高跳出率的表現(xiàn)是由著陸頁造成�,還是由流量造成。這也是典型的維度交叉細分的應用��。
CDA數(shù)據(jù)分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試����,點擊>>>
“CDA報名”
了解CDA考試詳情;
? 想學習CDA考試教材�,點擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫���,點擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量�,點擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330