機(jī)器理解大數(shù)據(jù)的秘密:聚類算法深度詳解
在理解大數(shù)據(jù)方面,聚類是一種很常用的基本方法。近日����,數(shù)據(jù)科學(xué)家兼程序員 Peter Gleeson 在 freeCodeCamp 發(fā)布了一篇深度講解文章����,對(duì)一些聚類算法進(jìn)行了基礎(chǔ)介紹,并通過簡(jiǎn)單而詳細(xì)的例證對(duì)其工作過程進(jìn)行了解釋說明�����。
看看下面這張圖���,有各種各樣的蟲子和蝸牛��,你試試將它們分成不同的組別��?
不是很難吧�����,先從找出其中的蜘蛛開始吧�����!

完成了嗎�����?盡管這里并不一定有所謂的「正確答案」����,但一般來說我們可以將這些蟲子分成四組:蜘蛛、蝸牛�����、蝴蝶/飛蛾����、蜜蜂/黃蜂���。
很簡(jiǎn)單吧?即使蟲子數(shù)量再多一倍你也能把它們分清楚�����,對(duì)嗎���?你只需要一點(diǎn)時(shí)間以及對(duì)昆蟲學(xué)的熱情就夠了——其實(shí)就算有成千上萬(wàn)只蟲子你也能將它們分開����。
但對(duì)于一臺(tái)機(jī)器而言��,將這 10 個(gè)對(duì)象分類成幾個(gè)有意義的分組卻并不簡(jiǎn)單——在一門叫做組合學(xué)(combinatorics)的數(shù)學(xué)分支的幫助下�,我們知道對(duì)于這 10 只蟲子�,我們可以有 115,975 種不同的分組方式。如果蟲子數(shù)量增加到 20��,那它們可能的分組方法將超過 50 萬(wàn)億種�。要是蟲子數(shù)量達(dá)到 100,那可能的方案數(shù)量將超過已知宇宙中的粒子的數(shù)量�����。超過多少呢?據(jù)我計(jì)算���,大約多 500,000,000,000,000,000,000,000,000,000,000,000 倍�����,已是難以想象的超天文數(shù)字����!
但其中大多數(shù)分組方案都是無(wú)意義的,在那些浩如煙海的分組選擇中�,你只能找到少量有用的蟲子分組的方法。
而我們?nèi)祟惪梢宰龅煤芸?����,我們往往?huì)把自己快速分組和理解大量數(shù)據(jù)的能力看作是理所當(dāng)然�。不管那是一段文本���,還是屏幕上圖像����,或是對(duì)象序列���,人類通常都能有效地理解自己所面對(duì)的數(shù)據(jù)�。
鑒于人工智能和機(jī)器學(xué)習(xí)的關(guān)鍵就是快速理解大量輸入數(shù)據(jù),那在開發(fā)這些技術(shù)方面有什么捷徑呢�?在本文中,你將閱讀到三種聚類算法——機(jī)器可以用其來快速理解大型數(shù)據(jù)集�����。當(dāng)然���,除此之外還有其它的算法��,但希望這里的介紹能給你一個(gè)良好的開始��!
在本文中,我將給出每種聚類算法的概述��、工作方式的簡(jiǎn)單介紹和一個(gè)更細(xì)節(jié)的逐步實(shí)現(xiàn)的案例���。我相信這能幫助你理解這些算法��。
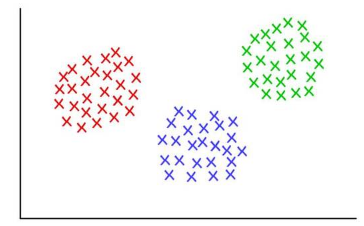
3 個(gè)齊整的聚類����,K=3
K-均值聚類(K-means clustering)
何時(shí)使用?
當(dāng)你事先知道你將找到多少個(gè)分組的時(shí)候�?
工作方式
該算法可以隨機(jī)將每個(gè)觀察(observation)分配到 k 類中的一類,然后計(jì)算每個(gè)類的平均���。接下來�����,它重新將每個(gè)觀察分配到與其最接近的均值的類別�����,然后再重新計(jì)算其均值�。這一步不斷重復(fù)��,直到不再需要新的分配為止���。
有效案例
假設(shè)有一組 9 位足球運(yùn)動(dòng)員�����,他們中每個(gè)人都在這一賽季進(jìn)了一定數(shù)量的球(假設(shè)在 3-30 之間)�。然后我們要將他們分成幾組——比如 3 組�����。
第一步:需要我們將這些運(yùn)動(dòng)員隨機(jī)分成 3 組并計(jì)算每一組的均值。
第 1 組
運(yùn)動(dòng)員 A(5 個(gè)球)����、運(yùn)動(dòng)員 B(20 個(gè)球)、運(yùn)動(dòng)員 C(11 個(gè)球)
該組平均=(5 + 20 + 11) / 3 = 12
第 2 組
運(yùn)動(dòng)員 D(5 個(gè)球)�、運(yùn)動(dòng)員 E(9 個(gè)球)、運(yùn)動(dòng)員 F(19 個(gè)球)
該組平均=11
第 3 組
運(yùn)動(dòng)員 G(30 個(gè)球)��、運(yùn)動(dòng)員 H(3 個(gè)球)���、運(yùn)動(dòng)員 I(15 個(gè)球)
該組平均=16
第二步:對(duì)于每一位運(yùn)動(dòng)員����,將他們重新分配到與他們的分?jǐn)?shù)最接近的均值的那一組��;比如��,運(yùn)動(dòng)員 A(5 個(gè)球)被重新分配到第 2 組(均值=11)���。然后再計(jì)算新的均值。
第 1 組(原來的均值=12)
運(yùn)動(dòng)員 C(11 個(gè)球)�、運(yùn)動(dòng)員 E(9 個(gè)球)
新的平均=(11 + 9) / 2 = 10
第 2 組(原來的均值=11)
運(yùn)動(dòng)員 A(5 個(gè)球)��、運(yùn)動(dòng)員 D(5 個(gè)球)���、運(yùn)動(dòng)員 H(3 個(gè)球)
新的平均=4.33
第 3 組(原來的均值=16)
運(yùn)動(dòng)員 B(20 個(gè)球)、運(yùn)動(dòng)員 F(19 個(gè)球)����、運(yùn)動(dòng)員 G(30 個(gè)球)、運(yùn)動(dòng)員 I(15 個(gè)球)
新的平均=21
不斷重復(fù)第二步�,直到每一組的均值不再變化。對(duì)于這個(gè)簡(jiǎn)單的任務(wù)��,下一次迭代就能達(dá)到我們的目標(biāo)?����,F(xiàn)在就完成了���,你已經(jīng)從原數(shù)據(jù)集得到了 3 個(gè)聚類��!
第 1 組(原來的均值=10)
運(yùn)動(dòng)員 C(11 個(gè)球)�、運(yùn)動(dòng)員 E(9 個(gè)球)��、運(yùn)動(dòng)員 I(15 個(gè)球)
最終平均=11.3
第 2 組(原來的均值=4.33)
運(yùn)動(dòng)員 A(5 個(gè)球)、運(yùn)動(dòng)員 D(5 個(gè)球)�、運(yùn)動(dòng)員 H(3 個(gè)球)
最終平均=4.33
第 3 組(原來的均值=21)
運(yùn)動(dòng)員 B(20 個(gè)球)、運(yùn)動(dòng)員 F(19 個(gè)球)����、運(yùn)動(dòng)員 G(30 個(gè)球)、
最終平均=23
通過這個(gè)例子���,該聚類可能能夠?qū)?yīng)這些運(yùn)動(dòng)員在球場(chǎng)上的位置——比如防守�����、中場(chǎng)和進(jìn)攻�。K-均值在這里有效���,是因?yàn)槲覀兛梢院侠淼仡A(yù)測(cè)這些數(shù)據(jù)會(huì)自然地落到這三個(gè)分組中����。
以這種方式�����,當(dāng)給定一系列表現(xiàn)統(tǒng)計(jì)的數(shù)據(jù)時(shí)��,機(jī)器就能很好地估計(jì)任何足球隊(duì)的隊(duì)員的位置——可用于體育分析�,也能用于任何將數(shù)據(jù)集分類為預(yù)定義分組的其它目的的分類任務(wù)。
更加細(xì)微的細(xì)節(jié):
上面所描述的算法還有一些變體�����。最初的「種子」聚類可以通過多種方式完成�。這里,我們隨機(jī)將每位運(yùn)動(dòng)員分成了一組��,然后計(jì)算該組的均值�����。這會(huì)導(dǎo)致最初的均值可能會(huì)彼此接近����,這會(huì)增加后面的步驟。
另一種選擇種子聚類的方法是每組僅一位運(yùn)動(dòng)員����,然后開始將其他運(yùn)動(dòng)員分配到與其最接近的組。這樣返回的聚類是更敏感的初始種子���,從而減少了高度變化的數(shù)據(jù)集中的重復(fù)性�。但是,這種方法有可能減少完成該算法所需的迭代次數(shù)�����,因?yàn)檫@些分組實(shí)現(xiàn)收斂的時(shí)間會(huì)變得更少��。
K-均值聚類的一個(gè)明顯限制是你必須事先提供預(yù)期聚類數(shù)量的假設(shè)�。目前也存在一些用于評(píng)估特定聚類的擬合的方法。比如說���,聚類內(nèi)平方和(Within-Cluster Sum-of-Squares)可以測(cè)量每個(gè)聚類內(nèi)的方差���。聚類越好,整體 WCSS 就越低���。
層次聚類(Hierarchical clustering)
何時(shí)使用��?
當(dāng)我們希望進(jìn)一步挖掘觀測(cè)數(shù)據(jù)的潛在關(guān)系�,可以使用層次聚類算法���。
工作方式
首先我們會(huì)計(jì)算距離矩陣(distance matrix)����,其中矩陣的元素(i,j)代表觀測(cè)值 i 和 j 之間的距離度量����。然后將最接近的兩個(gè)觀察值組為一對(duì)�����,并計(jì)算它們的平均值�����。通過將成對(duì)觀察值合并成一個(gè)對(duì)象����,我們生成一個(gè)新的距離矩陣。具體合并的過程即計(jì)算每一對(duì)最近觀察值的均值�����,并填入新距離矩陣���,直到所有觀測(cè)值都已合并�。
有效案例:
以下是關(guān)于鯨魚或海豚物種分類的超簡(jiǎn)單數(shù)據(jù)集��。作為受過專業(yè)教育的生物學(xué)家,我可以保證通常我們會(huì)使用更加詳盡的數(shù)據(jù)集構(gòu)建系統(tǒng)?���,F(xiàn)在我們可以看看這六個(gè)物種的典型體長(zhǎng)。本案例中我們將使用 2 次重復(fù)步驟�。
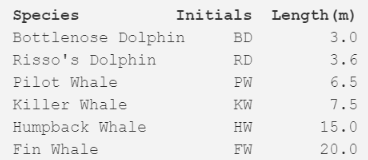
步驟一:計(jì)算每個(gè)物種之間的距離矩陣,在本案例中使用的是歐氏距離(Euclidean distance)�����,即數(shù)據(jù)點(diǎn)(data point)間的距離���。你可以像在道路地圖上查看距離圖一樣計(jì)算出距離�。我們可以通過查看相關(guān)行和列的交叉點(diǎn)值來查閱任一兩物種間的長(zhǎng)度差�。
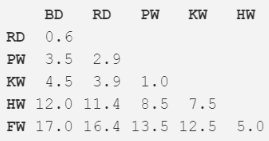
步驟二:將兩個(gè)距離最近的物種挑選出來,在本案例中是寬吻海豚和灰海豚����,他們平均體長(zhǎng)達(dá)到了 3.3m。重復(fù)第一步���,并再一次計(jì)算距離矩陣���,但這一次將寬吻海豚和灰海豚的數(shù)據(jù)使用其均值長(zhǎng)度 3.3m 代替�����。
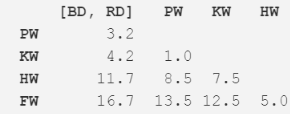
接下來�����,使用新的距離矩陣重復(fù)步驟二。現(xiàn)在�,最近的距離成了領(lǐng)航鯨與逆戟鯨,所以我們計(jì)算其平均長(zhǎng)度(7.0m)���,并合并成新的一項(xiàng)���。
隨后我們?cè)僦貜?fù)步驟一,再一次計(jì)算距離矩陣�����,只不過現(xiàn)在將領(lǐng)航鯨與逆戟鯨合并成一項(xiàng)且設(shè)定長(zhǎng)度為 7.0m����。
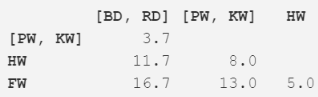
我們?cè)僖淮问褂矛F(xiàn)在的距離矩陣重復(fù)步驟 2。最近的距離(3.7m)出現(xiàn)在兩個(gè)已經(jīng)合并的項(xiàng)�����,現(xiàn)在我們將這兩項(xiàng)合并成為更大的一項(xiàng)(均值為 5.2m)。
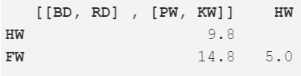
緊接著���,我們?cè)僖淮沃貜?fù)步驟 2���,最小距離(5.0m)出現(xiàn)在座頭鯨與長(zhǎng)須鯨中,所以繼續(xù)合并它們?yōu)橐豁?xiàng)�����,并計(jì)算均值(17.5m)����。
返回到步驟 1,計(jì)算新的距離矩陣�����,其中座頭鯨與長(zhǎng)須鯨已經(jīng)合并為一項(xiàng)�。

最后,重復(fù)步驟 2�����,距離矩陣中只存在一個(gè)值(12.3m),我們將所有的都合成為了一項(xiàng)����,并且現(xiàn)在可以停止這一循環(huán)過程。先讓我們看看最后的合并項(xiàng)�。

現(xiàn)在其有一個(gè)嵌套結(jié)構(gòu)(參考 JSON),該嵌套結(jié)構(gòu)能繪制成一個(gè)樹狀圖����。其和家族系譜圖的讀取方式相近。在樹型圖中����,兩個(gè)觀察值越近�����,它們就越相似和密切相關(guān)���。
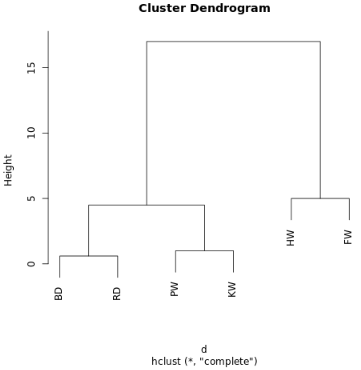
一個(gè)在 R-Fiddle.org 生成的樹狀圖
通過樹型圖的結(jié)構(gòu)�����,我們能更深入了解數(shù)據(jù)集的結(jié)構(gòu)�����。在上面的案例中�����,我們看到了兩個(gè)主要的分支��,一個(gè)分支是 HW 和 FW�����,另一個(gè)是 BD�、RD、PW�����、KW�����。
在生物進(jìn)化學(xué)中����,通常會(huì)使用包含更多物種和測(cè)量的大型數(shù)據(jù)集推斷這些物種之間的分類學(xué)關(guān)系��。在生物學(xué)之外����,層次聚類也在機(jī)器學(xué)習(xí)和數(shù)據(jù)挖掘中使用�����。
重要的是���,使用這種方法并不需要像 K-均值聚類那樣設(shè)定分組的數(shù)量��。你可以通過給定高度「切割」樹型以返回分割成的集群��。高度的選擇可以通過幾種方式進(jìn)行,其取決于我們希望對(duì)數(shù)據(jù)進(jìn)行聚類的分辨率����。
例如上圖,如果我們?cè)诟叨鹊扔?10 的地方畫一條線����,就將兩個(gè)主分支切開分為兩個(gè)子圖。如果我們從高度等于 2 的地方分割,就會(huì)生成三個(gè)聚類�����。
更多細(xì)節(jié):
對(duì)于這里給出的層次聚類算法(hierarchical clustering algorithms)�����,其有三個(gè)不同的方面�。
最根本的方法就是我們所使用的集聚(agglomerative)過程,通過該過程����,我們從單個(gè)數(shù)據(jù)點(diǎn)開始迭代,將數(shù)據(jù)點(diǎn)聚合到一起�,直到成為一個(gè)大型的聚類。另外一種(更高計(jì)算量)的方法從巨型聚類開始����,然后將數(shù)據(jù)分解為更小的聚類,直到獨(dú)立數(shù)據(jù)點(diǎn)��。
還有一些可以計(jì)算距離矩陣的方法�����,對(duì)于很多情況下,歐幾里德距離(參考畢達(dá)哥拉斯定理)就已經(jīng)夠了���,但還有一些可選方案在特殊的情境中更加適用���。
最后,連接標(biāo)準(zhǔn)(linkage criterion)也可以改變���。聚類根據(jù)它們不同的距離而連接�,但是我們定義「近距離」的方式是很靈活的�����。在上面的案例中����,我們通過測(cè)量每一聚類平均值(即形心(centroid))之間的距離,并與最近的聚類進(jìn)行配對(duì)�。但你也許會(huì)想用其他定義。
例如�����,每個(gè)聚類有幾個(gè)離散點(diǎn)組成�����。我們可以將兩個(gè)聚類間的距離定義為任意點(diǎn)間的最?���。ɑ蜃畲螅┚嚯x,就如下圖所示����。還有其他方法定義連接標(biāo)準(zhǔn),它們可能適應(yīng)于不同的情景�����。
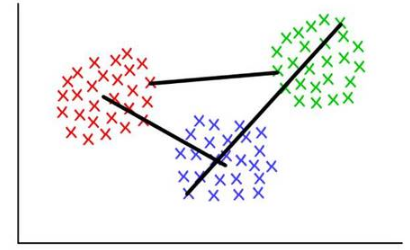
紅/藍(lán):形心連接�;紅/綠:最小連接;綠/藍(lán):最大連接
圖團(tuán)體檢測(cè)(Graph Community Detection)
何時(shí)使用�����?
當(dāng)你的數(shù)據(jù)可以被表示為一個(gè)網(wǎng)絡(luò)或圖(graph)時(shí)���。
工作方式
圖團(tuán)體(graph community)通常被定義為一種頂點(diǎn)(vertice)的子集�,其中的頂點(diǎn)相對(duì)于網(wǎng)絡(luò)的其它部分要連接得更加緊密����。存在多種用于識(shí)別圖的算法�����,基于更具體的定義�����,其中包括(但不限于):Edge Betweenness��、Modularity-Maximsation����、Walktrap����、Clique Percolation、Leading Eigenvector……
有效案例
圖論是一個(gè)研究網(wǎng)絡(luò)的數(shù)學(xué)分支���,參考機(jī)器之心文章《想了解概率圖模型��?你要先理解圖論的基本定義與形式》���。使用圖論的方法,我們可以將復(fù)雜系統(tǒng)建模成為「頂點(diǎn)(vertice)」和「邊(edge)」的抽象集合����。
也許最直觀的案例就是社交網(wǎng)絡(luò)。其中的頂點(diǎn)表示人����,連接頂點(diǎn)的邊表示他們是朋友或互粉的用戶。
但是��,要將一個(gè)系統(tǒng)建模成一個(gè)網(wǎng)絡(luò)���,你必須要找到一種有效連接各個(gè)不同組件的方式�����。將圖論用于聚類的一些創(chuàng)新應(yīng)用包括:對(duì)圖像數(shù)據(jù)的特征提取�����、分析基因調(diào)控網(wǎng)絡(luò)(gene regulatory networks)�。
下面給出了一個(gè)入門級(jí)的例子��,這是一個(gè)簡(jiǎn)單直接的圖�����,展示了我最近瀏覽過的 8 個(gè)網(wǎng)站,根據(jù)他們的維基百科頁(yè)面中的鏈接進(jìn)行了連接���。這個(gè)數(shù)據(jù)很簡(jiǎn)單����,你可以人工繪制��,但對(duì)于更大規(guī)模的項(xiàng)目���,更快的方式是編寫 Python 腳本����。
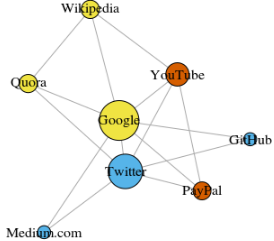
用 R 語(yǔ)言 3.3.3 版中的 igraph 繪制的圖
這些頂點(diǎn)的顏色表示了它們的團(tuán)體關(guān)系��,大小是根據(jù)它們的中心度(centrality)確定的�。可以看到谷歌和 Twitter 是最中心的吧�����?
另外,這些聚類在現(xiàn)實(shí)生活中也很有意義(一直是一個(gè)重要的表現(xiàn)指標(biāo))�。黃色頂點(diǎn)通常是參考/搜索網(wǎng)站,藍(lán)色頂點(diǎn)全部是在線發(fā)布網(wǎng)站(文章��、微博或代碼)�����,而橙色頂點(diǎn)是 YouTube 和 PayPal——因?yàn)?YouTube 是由前 PayPal 員工創(chuàng)立的�。機(jī)器還算總結(jié)得不錯(cuò)��!
除了用作一種有用的可視化大系統(tǒng)的方式����,網(wǎng)絡(luò)的真正力量是它們的數(shù)學(xué)分析能力。讓我們將上面圖片中的網(wǎng)絡(luò)翻譯成更數(shù)學(xué)的形式吧����。下面是該網(wǎng)絡(luò)的鄰接矩陣(adjacency matrix):
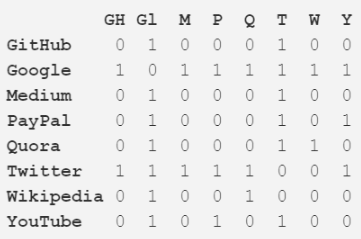
每行和每列的交點(diǎn)處的值表示對(duì)應(yīng)的頂點(diǎn)對(duì)之間是否存在邊。比如說����,在 Medium 和 Twitter 之間有一條邊,所以它們的行列交點(diǎn)是 1��。類似地��,Medium 和 PayPal 之間沒有邊,所以它們的行列交點(diǎn)是 0.
該鄰接矩陣編碼了該網(wǎng)絡(luò)的所有屬性——其給了我們開啟所有有價(jià)值的見解的可能性的鑰匙��。首先����,每一行或每一列的數(shù)字相加都能給你關(guān)于每個(gè)頂點(diǎn)的程度(degree)——即它連接到了多少個(gè)其它頂點(diǎn),這個(gè)數(shù)字通常用字母 k 表示��。類似地��,將每個(gè)頂點(diǎn)的 degree 除以 2��,則能得到邊的數(shù)量��,也稱為鏈接(link)��,用 L 表示���。行/列的數(shù)量即是該網(wǎng)絡(luò)中頂點(diǎn)的數(shù)量��,稱為節(jié)點(diǎn)(node)�����,用 N 表示�。
只需要知道 k、L 和 N 以及該鄰接矩陣 A 中每個(gè)單元的值��,就能讓我們計(jì)算出該網(wǎng)絡(luò)的任何給定聚類的模塊性(modularity)�。
假設(shè)我們已經(jīng)將該網(wǎng)絡(luò)聚類成了一些團(tuán)體。我們就可以使用該模塊性分?jǐn)?shù)來評(píng)估這個(gè)聚類的質(zhì)量����。分?jǐn)?shù)更高表示我們將該網(wǎng)絡(luò)分割成了「準(zhǔn)確的(accurate)」團(tuán)體����,而低分則表示我們的聚類更接近隨機(jī)。如下圖所示:
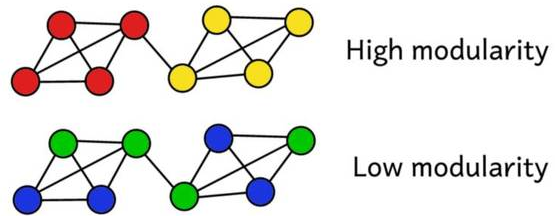
模塊性(modularity)是用于測(cè)量分區(qū)的「質(zhì)量」的一種標(biāo)準(zhǔn)
模塊性可以使用以下公式進(jìn)行計(jì)算:
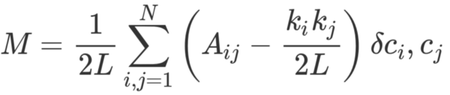
這個(gè)公式有點(diǎn)復(fù)雜�,但我們分解它,讓我們可以更好地理解�����。
M 就是我們要計(jì)算的模塊性���。
1/2L 告訴我們將后面的部分除以 2L���,即網(wǎng)絡(luò)中邊的數(shù)量的兩倍。
Σ 符號(hào)表示求和,并且在該鄰接矩陣 A 中的每一行和列上進(jìn)行迭代��。如果你對(duì)這個(gè)符號(hào)不熟悉�,可以將 i, j = 1 和 N 理解成編程語(yǔ)言中的 for-loop。在Python里面���,可以寫成這樣:

代碼里面的 #stuff with i and j(帶有 i 和 j 的那一坨)是什么�����?
括號(hào)中的內(nèi)容表示從 A_ij 減去 ( k_i k_j ) / 2L�。
A_ij 就是指該鄰接矩陣中第 i 行��、第 j 列的值�。
k_i 和 k_j 是指每個(gè)頂點(diǎn)的 degree——可以通過將每一行和每一列的項(xiàng)加起來而得到。兩者相乘再除以 2L 表示當(dāng)該網(wǎng)絡(luò)是隨機(jī)分配的時(shí)候頂點(diǎn) i 和 j 之間的預(yù)期邊數(shù)�。
整體而言,括號(hào)中的項(xiàng)表示了該網(wǎng)絡(luò)的真實(shí)結(jié)構(gòu)和隨機(jī)組合時(shí)的預(yù)期結(jié)構(gòu)之間的差��。研究它的值可以發(fā)現(xiàn)�,當(dāng) A_ij = 1 且 ( k_i k_j ) / 2L 很小時(shí),其返回的值最高�����。這意味著,當(dāng)在定點(diǎn) i 和 j 之間存在一個(gè)「非預(yù)期」的邊時(shí)����,得到的值更高。
最后�,我們?cè)賹⒗ㄌ?hào)中的項(xiàng)和 δc_i, c_j 相乘。δc_i, c_j 就是大名鼎鼎但基本無(wú)害的克羅內(nèi)克 δ 函數(shù)(Kronecker-delta function)����。下面是其 Python 解釋:

是的,就是那么簡(jiǎn)單�����?��?肆_內(nèi)克 δ 函數(shù)與兩個(gè)參數(shù),如何這兩個(gè)參數(shù)相等則返回 1���,如何不等���,則返回 0.
也就是說,如果頂點(diǎn) i 和 j 已經(jīng)被放進(jìn)了同一個(gè)聚類���,那么δc_i, c_j = 1��;否則它們不在同一個(gè)聚類�����,函數(shù)返回 0.
當(dāng)我們將括號(hào)中的項(xiàng)與克羅內(nèi)克 δ 函數(shù)相乘時(shí)��,我們發(fā)現(xiàn)對(duì)于嵌套求和 Σ�,當(dāng)有大量「意外的(unexpected)」連接頂點(diǎn)的邊被分配給同一個(gè)聚類時(shí),其結(jié)果是最高的�����。因此����,模塊性是一種用于衡量將圖聚類成不同的團(tuán)體的程度的方法。
除以 2L 將模塊性的上限值設(shè)置成了 1�。模塊性接近或小于 0 表示該網(wǎng)絡(luò)的當(dāng)前聚類沒有用處。模塊性越高�,該網(wǎng)絡(luò)聚類成不同團(tuán)體的程度就越好。通過是模塊性最大化��,我們可以找到聚類該網(wǎng)絡(luò)的最佳方法����。
注意我們必須預(yù)定義圖的聚類方式���,才能找到評(píng)估一個(gè)聚類有多好的方法。不幸的是����,使用暴力計(jì)算的方式來嘗試各種可能以尋找最高模塊性分?jǐn)?shù)的聚類方式需要大量計(jì)算,即使在一個(gè)有限大小的樣本上也是不可能的��。
組合學(xué)(combinatorics)告訴我們對(duì)于一個(gè)僅有 8 個(gè)頂點(diǎn)的網(wǎng)絡(luò)�,就存在 4140 種不同的聚類方式。16 個(gè)頂點(diǎn)的網(wǎng)絡(luò)的聚類方式將超過 100 億種�。32 個(gè)頂點(diǎn)的網(wǎng)絡(luò)的可能聚類方式更是將超過 128 septillion(10^21)種;如果你的網(wǎng)絡(luò)有 80 個(gè)頂點(diǎn)��,那么其可聚類的方式的數(shù)量就已經(jīng)超過了可觀測(cè)宇宙中的原子數(shù)量��。
因此���,我們必須求助于一種啟發(fā)式的方法,該方法在評(píng)估可以產(chǎn)生最高模塊性分?jǐn)?shù)的聚類上效果良好����,而且并不需要嘗試每一種可能性�����。這是一種被稱為 Fast-Greedy Modularity-Maximization(快速貪婪模塊性最大化)的算法��,這種算法在一定程度上類似于上面描述的 agglomerative hierarchical clustering algorithm(集聚層次聚類算法)�����。只是 Mod-Max 并不根據(jù)距離(distance)來融合團(tuán)體�,而是根據(jù)模塊性的改變來對(duì)團(tuán)體進(jìn)行融合�。
下面是其工作方式:
首先初始分配每個(gè)頂點(diǎn)到其自己的團(tuán)體,然后計(jì)算整個(gè)網(wǎng)絡(luò)的模塊性 M����。
第 1 步要求每個(gè)團(tuán)體對(duì)(community pair)至少被一條單邊鏈接,如果有兩個(gè)團(tuán)體融合到了一起���,該算法就計(jì)算由此造成的模塊性改變 ΔM�。
第 2 步是取 ΔM 出現(xiàn)了最大增長(zhǎng)的團(tuán)體對(duì)�����,然后融合���。然后為這個(gè)聚類計(jì)算新的模塊性 M���,并記錄下來�。
重復(fù)第 1 步和 第 2 步——每一次都融合團(tuán)體對(duì)�,這樣最后得到 ΔM 的最大增益,然后記錄新的聚類模式及其相應(yīng)的模塊性分?jǐn)?shù) M�����。
當(dāng)所有的頂點(diǎn)都被分組成了一個(gè)巨型聚類時(shí)�,就可以停止了。然后該算法會(huì)檢查這個(gè)過程中的記錄����,然后找到其中返回了最高 M 值的聚類模式。這就是返回的團(tuán)體結(jié)構(gòu)��。
更多細(xì)節(jié):
哇�!這個(gè)過程真是有太多計(jì)算了,至少對(duì)我們?nèi)祟惗允沁@樣���。圖論中存在很多計(jì)算難題,常常是 NP-hard 問題——但其也在為復(fù)雜系統(tǒng)和數(shù)據(jù)集提供有價(jià)值的見解上具有出色的潛力����。Larry Page 就知道這一點(diǎn)����,其著名的 PageRank 算法就是完全基于圖論的——該算法在幫助谷歌在不到十年之內(nèi)從創(chuàng)業(yè)公司成長(zhǎng)為近乎世界主宰的過程中立下了汗馬功勞�。
團(tuán)體檢測(cè)(community detection)是現(xiàn)在圖論中一個(gè)熱門的研究領(lǐng)域,也存在很多可替代 Modularity-Maximization(盡管很有用���,但也有缺點(diǎn))的方法��。
首先�,它的聚集方式從指定尺寸的小團(tuán)體開始����,逐漸轉(zhuǎn)向越來越大的。這被稱為分辨率極限(resolution limit)——該算法不會(huì)搜索特定尺寸以下的團(tuán)體��。另一個(gè)挑戰(zhàn)則是超越一個(gè)顯著波峰的表現(xiàn)�,Mod-Max 方法趨向于制造一個(gè)由很多高模塊化分?jǐn)?shù)組成的「高原」,這有時(shí)會(huì)導(dǎo)致難以確定最大分?jǐn)?shù)�。
其他算法使用不同的方式來確定團(tuán)體。Edge-Betweenness 是一個(gè)分裂算法�����,把所有頂點(diǎn)聚合到一個(gè)大集群中。它會(huì)持續(xù)迭代去除網(wǎng)絡(luò)中「最不重要」的邊緣數(shù)據(jù)�,直到所有頂點(diǎn)都被分開為止。這一過程產(chǎn)生了層級(jí)結(jié)構(gòu)�,其中類似的頂點(diǎn)在結(jié)構(gòu)中互相靠近。
另一種算法是 Clique Percolation����,它考慮了圖團(tuán)體之間可能的重疊。而另外一些算法基于圖中的隨機(jī)游動(dòng)����,還有譜聚類(spectral clustering)算法:從鄰接矩陣及派生矩陣的特征分解開始。這些方法被應(yīng)用于特征提取任務(wù)���,如計(jì)算機(jī)視覺�。
給出每個(gè)算法的深入應(yīng)用實(shí)例超出了本介紹的探究范圍��。從數(shù)據(jù)中提取可用信息的有效方法在數(shù)十年前還是難以觸及的事物��,但現(xiàn)在已經(jīng)成為了非?;钴S的研究領(lǐng)域。
結(jié)論
希望本文能對(duì)你有所啟發(fā)��,讓你更好地理解機(jī)器如何了解大數(shù)據(jù)。未來是高速變革的����,其中的許多變化將會(huì)由下一代或兩代中有能力的技術(shù)所驅(qū)動(dòng)��。
就像導(dǎo)語(yǔ)提到的���,機(jī)器學(xué)習(xí)是一個(gè)非常有前景的研究領(lǐng)域���,其中有大量復(fù)雜的問題需要以準(zhǔn)確、有效的方式解決�����。對(duì)人類來說輕而易舉的任務(wù)在由機(jī)器完成的時(shí)候就需要?jiǎng)?chuàng)新性的解決方案�。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情�����;
? 想學(xué)習(xí)CDA考試教材�����,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫(kù)�,點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情;
? 想了解CDA考試含金量�,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330