SAS DATA步之全解密
SAS DATA步對于SAS入門學(xué)習(xí)者來說是個難以理解的東西��,因?yàn)镾AS封裝了一些過程�����,這種封裝對于有語言基礎(chǔ)的人來說反而是一個障礙�。本文非常詳細(xì)的解釋了SAS 數(shù)據(jù)的編譯、執(zhí)行過程�����,對于了解SAS的基本運(yùn)行有很大幫助���。不管SAS老鳥����,新鳥,相信你都會有收獲��,因?yàn)檫@篇文章是難得的如此系統(tǒng) �!
摘要
每個SAS數(shù)據(jù)步(SAS Data step��,以后寫成簡寫“DATA步”)在整個SAS程序中編譯和執(zhí)行過程中����。大量DATA步的處理過程都是非明示的(即隱藏不可見)。例如��,盡管程序中沒有使用循環(huán)控制語句不包含循環(huán)��,但DATA步都像一個自封裝的小程序以一種非明示的循環(huán)形式執(zhí)行��。
這篇文章探討了一些非明示的DATA處理過程怎么控制你的DATA步實(shí)際運(yùn)行的�����。
需要提前說明的概念:
程序數(shù)據(jù)向量(Logical Program Data Vector簡寫成PDV�����,臺灣地區(qū)翻譯成“程式資料向量”)
SAS自動變量名及其使用
理解data步的內(nèi)部處理過程
代碼編譯期間發(fā)生的事情
程序執(zhí)行期間實(shí)際發(fā)生了什么
如何獲取和存儲變量屬性
你或許在程序中寫過大量的DATA步:一些能運(yùn)行,一些則運(yùn)行不了����。有時候你知道為什么;有時你不知道為什么�,甚至你冥思苦想而百思不得其解。如果碰到過這些問題�����,那么這篇文章很適合你����。
Data步設(shè)計的非常好,但是有些另類����。如果你想寫出很漂亮的代碼,就很有必要知道DATA步的工作原理���。讀完這篇文章以后�����,“哦�����,哦�,… 原來如此!”��,一個即使使用SAS多年的老鳥��,也會發(fā)出這樣的感嘆��。
引言
DATA步是建SAS數(shù)據(jù)集的主要方法之一��。要想成為一個優(yōu)秀的SAS程序員很有必要理解DATA步的各個環(huán)節(jié)����,主要是因?yàn)橐恍┥婕?a href='/map/shujuchuli/' style='color:#000;font-size:inherit;'>數(shù)據(jù)處理和創(chuàng)建數(shù)據(jù)集的任務(wù)可能只能通過DATA步才能解決(這些任務(wù)不能通過SAS過程步(SAS procedures�,以后簡寫成“SAS過程步”)解決、或者使用SAS過程步太過復(fù)雜而難以使用)�。
了解DATA步的生命周期非常重要,它分為編譯和執(zhí)行兩個階段���。同時學(xué)習(xí)PDV也非常重要����。PDV貫穿SAS的編譯和執(zhí)行兩個階段,而且能決定了信息在DATA步中的存儲及變化�。
編譯階段包括:
編譯SAS語句,包括檢查語法
創(chuàng)建一個輸入緩存區(qū)(input buffer)(如果需要讀入原始數(shù)據(jù)文件)���、一個PDV和描述性信息
執(zhí)行階段包括:
計算Data步迭代的次數(shù)(從Data語句開始)
將PDV中的所有變量設(shè)成缺失值并初始化自動變量
讀取輸入觀測(從原始文件或SAS數(shù)據(jù)集)
執(zhí)行附加的處理或計算語句
將一條數(shù)據(jù)記錄寫入輸出數(shù)據(jù)集并返回到DATA步語句
PDV貫穿編譯和執(zhí)行階段:
PDV是內(nèi)存中的一個臨時邏輯區(qū)域�,SAS建立數(shù)據(jù)集時�����,每條觀察值只有一次機(jī)會用到PDV���。
包含所有變量的當(dāng)前值
包含兩個自動變量:_N_和_ERROR_
如果你已經(jīng)了解控制DATA步處理過程的這些重要概念��,那么你就能控制DATA步����,來指揮SAS根據(jù)自己的意愿來工作和初始化自動變量����。
DATA 步
一個DATA步包含SAS語言中的一組語句,這些語句具有以下功能:
從外部文件讀入數(shù)據(jù)
將數(shù)據(jù)寫入外部文件
讀入SAS數(shù)據(jù)集和SAS視圖
創(chuàng)建SAS數(shù)據(jù)集和SAS視圖
一旦數(shù)據(jù)可以以SAS數(shù)據(jù)集的形式訪問�,你就可以通過SAS過程步來分析數(shù)據(jù)和寫報告����。
可以運(yùn)用DATA步:
創(chuàng)建SAS數(shù)據(jù)集(SAS數(shù)據(jù)集或SAS視圖)
根據(jù)包含原始數(shù)據(jù)(外部文件)的文件創(chuàng)建SAS數(shù)據(jù)集
通過提取子集���、合并��、修改和更新已經(jīng)存在數(shù)據(jù)集的方式來創(chuàng)建新的數(shù)據(jù)集
分析��、處理或展現(xiàn)數(shù)據(jù)
為新變量賦值 (譯者注:有公式計算的情況下)
撰寫報告或?qū)⑽募懭氪疟P或磁帶
信息檢索
文件管理
DATA步以“DATA”語句開始(即顯示的表明數(shù)據(jù)步的開始)��,以“RUN”語句結(jié)束����,在結(jié)束時會編譯或執(zhí)行RUN語句��。在數(shù)據(jù)步最后一個觀察值讀取前��,“RUN”的功能都是以非顯示的形式執(zhí)行RETURN功能�����,去繼續(xù)循環(huán)的操作�。
DATA步的生命周期圖
SAS提供了下面的流程圖來描述DATA步的處理過程�。
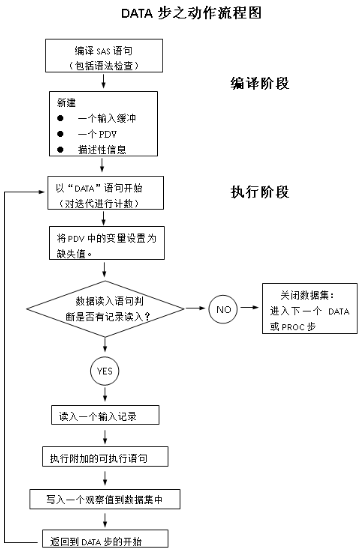
From “The Secret Life of DATA STEP” translated by sxlion
圖1 DATA步的動作流程圖
編譯階段
如上所述,DATA步的第一個階段就為編譯階段。在編譯階段SAS的任務(wù)如下:
自動將SAS語句編譯成將會在后面執(zhí)行的機(jī)器語言
確定每個變量的類型和長度
確定變量是否有必要進(jìn)行類型轉(zhuǎn)換
如果有INPUT語句�,為外部文件新建讀取內(nèi)存緩存區(qū)
創(chuàng)建PDV(Program Data Vector)
創(chuàng)建數(shù)據(jù)集和變量屬性的描述性信息
處理語句,該項(xiàng)任務(wù)僅限于編譯階段����;這為編譯器如何新建變量提供信息;事實(shí)上���,它們決定了如何在PDV內(nèi)建立變量及信息�;這些信息包括:DROP;KEEP;RENAME;RETAIN;WHERE;LABEL;LENGTH;FORMAT;ARRAY;BY;ATTRIB
創(chuàng)建自動變量�����;包括_N_,_ERROR_,END=,IN=,FIRST,LAST,POINT=
例1:語法錯誤檢查
1 data example_1;
2 x = ||Hi= ;
–
386
200
3 y = ||How=;
–
386
200
4 y = ||Your=;
–
386
200
5 y = ||Day=;
–
386
200
RROR 386-185: Expecting an arithmetic expression. /*期望一個數(shù)學(xué)公式*/
ERROR 200-322: The symbol is not recognized and will be ignored. /*符號不被識別�,忽略*/
6 run; /*代碼6 運(yùn)行*/
執(zhí)行階段
把SAS代碼編譯成機(jī)器代碼后,輸入緩存區(qū)����,PDV和描述性信息。執(zhí)行階段進(jìn)入重要階段�����,SAS將按照默認(rèn)的順序執(zhí)行以下功能:
從DATA語句開始�,將_N_值設(shè)定為1(隨著DATA語句的每次迭代��,變量_N_自動加1)
把PDV(Program Data Vecctor)中的變量設(shè)為missing
用Input語句把一條數(shù)據(jù)記錄讀入緩存區(qū)(如果讀入的是原始文件)
用SET�����,MERGE��,MODIFY或UPDATE語句��,把SAS數(shù)據(jù)集里的一條觀測值讀入到PDV
執(zhí)行DATA步中存在的程序語句
將一條觀測寫入輸出數(shù)據(jù)集���,碰到語句data _NULL_的情況除外,即無需寫入數(shù)據(jù)
一個迭代結(jié)束�����,返回到DATA語句的開始
每個迭代過程都循環(huán)進(jìn)行直到達(dá)到輸入文件(或輸入數(shù)據(jù)集)結(jié)尾
如果DATA步?jīng)]有讀入任何記錄��,執(zhí)行(默認(rèn)情況)行為只進(jìn)行一次
可以通過條件語句IF-THEN-ELSE��、DO Loops�、LINK,RETURN和GO TO等語句改變執(zhí)行的默認(rèn)順序
例2:默認(rèn)和強(qiáng)制情況下的順序
第一個例子是一個簡單的DATA步��,它遵循語句的標(biāo)準(zhǔn)執(zhí)行過程并輸出數(shù)據(jù)記錄����。這個例子中��,一個迭代過程產(chǎn)生了一個觀測:
data example_2;
x = ‘Minnesota’;
y = ‘Columbus’;
run;
The log presents the following message: /*日志輸出如下信息*/
NOTE: The data set WORK.EXAMPLE_2 has 1 observation and 2 variables.
第二個例子展現(xiàn)了數(shù)據(jù)步的一個迭代過程如何生成5條觀測�����。DO LOOP循環(huán)改變了執(zhí)行的默認(rèn)順序�。
data example_3;
do i = 1 to 5;
x = ‘Minnesota’;
y = ‘Columbus’;
output;
end;
run;
The log presents the following message
NOTE: The data set WORK.EXAMPLE_2 has 5 observations and 3 variables.
PDV(Program Data Vector)
在SAS參考教程中將PDV定義為:“PDV是內(nèi)存中用來創(chuàng)建數(shù)據(jù)集的邏輯區(qū)域����,每次只涉及一條觀測值。當(dāng)程序執(zhí)行時����,SAS從輸入緩存區(qū)中讀入數(shù)值或通過執(zhí)行SAS語句創(chuàng)建數(shù)值。數(shù)據(jù)值賦給PDV中一個合適的變量����。SAS將該數(shù)值作為一條觀測值寫入SAS數(shù)據(jù)集?!?
換句話說:PDV(Program Data Vector)是內(nèi)存中的一個存儲空間,包含了DATA步涉及的所有變量�。變量出現(xiàn)的順序決定了在他們在PDV中的順序。每個變量可能會有一個標(biāo)記�����,用于指示他們是被保留(Keep)、舍棄(Drop)或是改名(Rename)����。當(dāng)程序運(yùn)行時,PDV包含的觀測值被處理��。在結(jié)束時����,數(shù)據(jù)根據(jù)程序中的DROP、KEEP或RENAME標(biāo)識被輸出�����。
輸入緩存區(qū)創(chuàng)建完成后����,PDV也隨即創(chuàng)建完成。PDV是內(nèi)存中創(chuàng)建數(shù)據(jù)集的地方�,一次僅創(chuàng)建一個觀測�����。像術(shù)語輸入緩存區(qū)(Input buffer)一樣,PDV也只是一個邏輯概念���。
PDV(Program Data Vector)中包含兩個自動變量供數(shù)據(jù)步使用����,但是這兩個自動變量并不會作為觀測的一部分輸出到數(shù)據(jù)集���。
_N_對DATA步開始執(zhí)行后的迭代次數(shù)進(jìn)行計數(shù)
_ERROR_表示在數(shù)據(jù)步執(zhí)行期間有錯誤發(fā)生�����。_ERROR_的默認(rèn)值為0�,表示程序沒有錯誤�����。當(dāng)程序中出現(xiàn)一個或多個錯誤時���,_ERROR_的值變?yōu)?�。
變量First.By-variance和變量Last.By-variance:這兩個臨時變量總是成對出現(xiàn)�,By語句中的每一個By變量都對應(yīng)著一對臨時變量。當(dāng)他們的條件為真或假時分別相應(yīng)的賦值為1或0��。
PDV

臨時變量(Temporary variables)可以通過SAS選項(xiàng)和語句來創(chuàng)建,和自動變量一樣���,臨時變量也不會輸出到數(shù)據(jù)集��。一些臨時變量包括:
選項(xiàng)IN=變量:IN=是數(shù)據(jù)集的一個選項(xiàng)����,表示一個特定數(shù)據(jù)集是否貢獻(xiàn)了當(dāng)前觀察值���。程序員可以用該選項(xiàng)指定一個變量名�����,當(dāng)觀測在數(shù)據(jù)集中時變量值為1否則為0��。
END=變量名:END=是SET語句的一個選項(xiàng)表示已經(jīng)達(dá)到輸入數(shù)據(jù)集的結(jié)尾�����。如果達(dá)到文件的結(jié)尾����,程序員通過指定一個變量名,當(dāng)數(shù)據(jù)達(dá)到最后一個時���,該變量被賦值1,否則為0�。一個SET語句只能設(shè)一個END=選項(xiàng)。如果SET語句后有多個數(shù)據(jù)集���,只有達(dá)到最后一個數(shù)據(jù)集的最后一條觀測值時����,該變量的值才為1�����。
如果需要把臨時變量和自動變量的值輸出到數(shù)據(jù)集����,則需要把臨時變量或自動變量的值賦給用戶定義的變量。
PDV存儲數(shù)據(jù)集中的��、input 涉及的或data步執(zhí)行過程中創(chuàng)建的所有變量�����,包括用戶自定義、自動和臨時的變量���。PDV被用來填充輸出數(shù)據(jù)集�。輸出數(shù)據(jù)集中的所有變量都在PDV(Program Data Vector)中��,但并不是PDV(Program Data Vector)中的所有變量都輸出到最終數(shù)據(jù)集���。
SAS執(zhí)行過程中����,在DATA步迭代之初都會把PDV(Program Data Vector)中非保留和非輸入變量設(shè)為缺失值��。SAS從輸入文件或一個SAS數(shù)據(jù)集讀入數(shù)據(jù)到PDV(Program Data Vector)中�����,同時會替掉以前存在的值�����。
DATA步處理過程:系統(tǒng)介紹
Example 4 – simple default – no reading of input data /*簡單默認(rèn)-沒有讀入input數(shù)據(jù)*/
data example_4;
put “after compile before execution: ” _all_;
x = “GOOD”;
y = “MORNING”;
z = “COLUMBUS”;
n = 4;
k = n*2;
put “at end of execution: ” _all_;
run;
編譯階段PDV的設(shè)置如下:

在DATA步結(jié)尾���,PDV執(zhí)行結(jié)果如下:
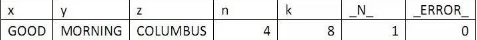
例1中有一條觀測輸出�����。DATA步只進(jìn)行了一次迭代�。除了_N_和_ERROR_兩個變量,數(shù)據(jù)集中包括剩下的所有變量��。
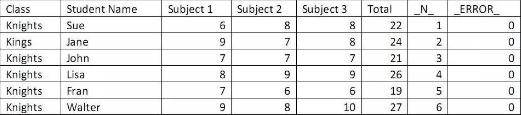
Example 5 – reading of raw input data /*讀取原始input數(shù)據(jù)*/
data total_points (drop=Class);
input class $ StudentName $ Subject1 Subject2 Subject3;
Total = (Subject1 + Subject2 + Subject3);
datalines;
Knights Sue 6 8 8
Kings Jane 9 7 8
Knights John 7 7 7
Knights Lisa 8 9 9
Knights Fran 7 6 6
Knights Walter 9 8 10
;
Run;
由于這個例子包含了原數(shù)據(jù)input文件���。SAS在把這些數(shù)據(jù)發(fā)送到PDV之前先創(chuàng)建內(nèi)存緩沖區(qū)來存儲數(shù)據(jù)。
注意:如果輸入文件是一個SAS數(shù)據(jù)集��,SAS就不會在創(chuàng)建內(nèi)存緩沖區(qū)��。SAS會把數(shù)據(jù)直接傳送到PDV�����。
內(nèi)存緩沖區(qū)input buffer

PDV

注意�,在上面表格中,數(shù)值變量和字符變量分別被初始化為點(diǎn)和空格����。自動變量_N_的初始為1;自動變量_ERROR_的初值為0.
讀入第一條觀測后�����,PDV如下所示:

當(dāng)SAS執(zhí)行DATA步最后一條語句時,除了被標(biāo)記為drop的變量��,PDV中剩余的所有值將作為一個觀測輸出到數(shù)據(jù)集TOTAL_POINTS�����。
接著SAS會回到DATA步開頭進(jìn)行下一輪迭代��。SAS按照下面的方式重設(shè)PDV中的值�。
INPUT語句創(chuàng)建的變量值被設(shè)為缺失值。
累加語句創(chuàng)建的值自動保留�。
Retain語句中的變量值自動保留 /* 原文無,sxlion補(bǔ)充*/
自動變量_N_的值自動加1����,_ERROR_的值重設(shè)為0。
下表展示了每條記錄被寫入例2數(shù)據(jù)集之前在PDV中的存在形式�����。應(yīng)該牢記:PDV每次只存一條觀測�����,而且在新數(shù)據(jù)存入之前把原數(shù)據(jù)寫入到輸出數(shù)據(jù)集中。
總結(jié)
可視化PDV對理解DATA步的執(zhí)行過程非常有幫助���。對于簡單的DATA步來說似乎沒有必要����,但是這樣做對理解DATA步很有益�。如果你在某種程度上理解了一個數(shù)據(jù)集的讀入和輸出,那么你不至于寫出類似下面這個的多個DATA步�。數(shù)據(jù)分析師培訓(xùn)
data a;
set perm.a ;
data b;
set a ;
x = y + 2;
既然數(shù)據(jù)集PERM.A中的每個觀測都被復(fù)制到PDV中�,那么為什么不同時創(chuàng)建X變量呢?
當(dāng)你想做復(fù)雜的事情時����,你需要非常具體而不是模糊地知道關(guān)于PDV中存儲的信息和SAS處理這些信息的規(guī)則。當(dāng)你的程序沒有按照你的意愿執(zhí)行��,通過PUT語句或DATA步將PDV中的部分信息輸出到日志查看��。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認(rèn)證考試����,點(diǎn)擊>>>
“CDA報名”
了解CDA考試詳情;
? 想學(xué)習(xí)CDA考試教材��,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫�,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情;
? 想了解CDA考試含金量��,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330