數(shù)據(jù)分析技術(shù):事后多重比較的方法介紹;了解各種方法的原理才能做到“準(zhǔn)確分析”
基礎(chǔ)準(zhǔn)備
均值比較的假設(shè)檢驗(yàn)是數(shù)據(jù)分析最重要的分析內(nèi)容之一����,根據(jù)參與比較的樣本數(shù)量不同,使用的假設(shè)檢驗(yàn)方法也不同����,做個(gè)簡(jiǎn)要的總結(jié):
一個(gè)總體均值與一個(gè)常數(shù)進(jìn)行比較(Z檢驗(yàn)和T檢驗(yàn));
兩個(gè)總體均值之間的比較(Z檢驗(yàn)和T檢驗(yàn))��;
三個(gè)及三個(gè)以上總體均值的比較(方差分析)����;
與Z檢驗(yàn)和T檢驗(yàn)不同,方差分析的結(jié)果只能檢驗(yàn)出三個(gè)以上的總體均值是完全相同呢�?還是不完全相同?注意是不完全相同�,至于是哪個(gè)或哪些總體均值與其它總體均值不同則是不能獲知的。因此方差分析結(jié)束以后還需要做事后多重檢驗(yàn),分析出到底是哪個(gè)或哪些總體均值與眾不同����。
今天我們要介紹的是進(jìn)行事后多重檢驗(yàn)的方法介紹。如果對(duì)方差分析還不太熟悉的朋友可以點(diǎn)擊下面的鏈接回顧:
數(shù)據(jù)分析技術(shù):方差分析原理����;
數(shù)據(jù)分析理論:方差分析模型;
很多朋友會(huì)有疑問��,為什么方差分析一定要進(jìn)行事后多重比較呢����?直接用獨(dú)立樣本T檢驗(yàn)進(jìn)行多次兩兩比較不是也可以嗎?我們可以用一個(gè)例子說明這個(gè)原因:以方差分析為例���,假如有5個(gè)樣本�����,如果要進(jìn)行多次均值的兩兩比較��,那么兩兩比較的次數(shù)多達(dá)10次。設(shè)每次比較的顯著性水平等于0.05��,那么10次比較都不犯“棄真”錯(cuò)誤的概率為(1-0.05)的十次方,也就是0.60左右�����,也就是說犯“棄真”錯(cuò)誤的概率高達(dá)0.40�,這遠(yuǎn)遠(yuǎn)大于原先設(shè)定的顯著性水平0.05。不僅如此����,隨著比較組數(shù)的增多,犯“棄真”錯(cuò)誤的概率也會(huì)越來越大����。
SPSS的事后多重檢驗(yàn)方法
應(yīng)用SPSS進(jìn)行方差分析時(shí),給分析者提供了很多事后多重檢驗(yàn)的方法��,如下圖所示�。這些方法根據(jù)多個(gè)總體方差是否相等分成了兩大類。
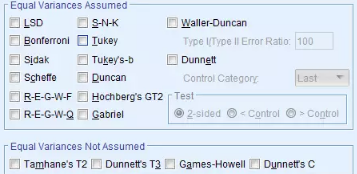
事后多重檢驗(yàn)的方法很多��,但并不是說它們?nèi)绨倩R放般的襯托了統(tǒng)計(jì)學(xué)的欣欣向榮����,而是說明到目前為止仍然沒有統(tǒng)一的解決方法,因此才根據(jù)不同的目的和數(shù)據(jù)情況創(chuàng)造出了很多不同的方法����。
兩兩比較的方法
LSD法:最小顯著性差異法(Least Significance Difference)���,是最簡(jiǎn)單的比較方法之一。它是t檢驗(yàn)的一個(gè)簡(jiǎn)單變形����,并未對(duì)檢驗(yàn)水準(zhǔn)做出任何校正,只是在標(biāo)準(zhǔn)誤(注意不是標(biāo)準(zhǔn)差)的計(jì)算上充分考慮了所有總體水平的樣本信息���,估計(jì)出了一個(gè)更為穩(wěn)健的標(biāo)準(zhǔn)誤���。因?yàn)閱未伪容^的顯著性水平a保持不變,所以LSD法是最靈敏的事后多重比較法��。
Sidak法:Sidak校正在LSD法上的應(yīng)用��。通過Sidak校正降低每次兩兩比較的“棄真”錯(cuò)誤概率�,以使最終整個(gè)比較的“棄真”錯(cuò)誤概率保持為顯著性水平a。這也就是說每次比較的顯著性水平a會(huì)隨著比較次數(shù)的增多而減小���。顯然���,Sidak法比LSD法的靈敏度低����。每次進(jìn)行Sidak比較的顯著性水平為:

Bonferroni法:與Sidak法類似��,它的每一次比較實(shí)際上是Bonferroni校正在LSD法上的應(yīng)用�����。Bonferroni法修正后每次比較的顯著性水平比Sidak法的更小���,也就是說Bonferroni法比Sidak法的靈敏度更低。

Scheffe法:Scheffe法的實(shí)質(zhì)是對(duì)多個(gè)總體均值間的線性組合是否為0進(jìn)行假設(shè)檢驗(yàn)�。多用在兩組樣本含量不同的情況。
Dunnett法:常用于多個(gè)試驗(yàn)組與一個(gè)對(duì)照組間的比較�。因此在指定Dunnett法時(shí),還應(yīng)當(dāng)指定對(duì)照組��。
以上五種方法的排列順序是按照靈敏度從高到低排列的�����,LSD法>Sidak法>Bonferroni法>Scheffe法>Dunnett法���。
形成同質(zhì)亞組的方法
SNK法:全稱為Student-Newman-Keuls法�。它實(shí)質(zhì)上是根據(jù)預(yù)先指定的準(zhǔn)則將各組均值分為多個(gè)亞組,利用Studentized Range分布來進(jìn)行假設(shè)檢驗(yàn)�����,并根據(jù)所要檢驗(yàn)的均值個(gè)數(shù)調(diào)整總的“棄真”錯(cuò)誤概率不超過設(shè)定的顯著性水平a�����。
Tukey法:全稱為Tukey' s Honestly Significant Difference法�����。應(yīng)用這種方法要求各組樣本含量相同����。它也是利用Studentized Range分布來進(jìn)行各組均數(shù)間的比較,與SNK法不同地是�����,它控制所有比較中最大的“棄真”錯(cuò)誤概率不超過設(shè)定的顯著性水平a���。
Duncan法:其思路與SNK法相類似���,只不過檢驗(yàn)統(tǒng)計(jì)量服從的是Duncan' s Multiple Range分布����。
以上8種是常用的事后多重檢驗(yàn)方法(各水平樣本的方差齊性)�,剩下的六種方法并不常用,這里就不在介紹��。除此之外��,在各組樣本方差不齊時(shí)���,SPSS還提供了4種事后多重檢驗(yàn)的方法,但從方法的接受程度和結(jié)果的穩(wěn)健性講�����,希望大家盡量不要在方差不齊時(shí)進(jìn)行方差分析甚至兩兩比較����,采用變量變換或者非參數(shù)檢驗(yàn)往往更可靠。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試�����,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情����;
? 想學(xué)習(xí)CDA考試教材�,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情���;
? 想了解CDA考試含金量���,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330