機(jī)器學(xué)習(xí)中的kNN算法及Matlab實(shí)例
K最近鄰(k-Nearest Neighbor��,KNN)分類算法��,是一個(gè)理論上比較成熟的方法�,也是最簡(jiǎn)單的機(jī)器學(xué)習(xí)算法之一。該方法的思路是:如果一個(gè)樣本在特征空間中的k個(gè)最相似(即特征空間中最鄰近)的樣本中的大多數(shù)屬于某一個(gè)類別�����,則該樣本也屬于這個(gè)類別�。
盡管kNN算法的思想比較簡(jiǎn)單,但它仍然是一種非常重要的機(jī)器學(xué)習(xí)(或數(shù)據(jù)挖掘)算法��。在2006年12月召開的 IEEE
International Conference on Data Mining (ICDM)��,與會(huì)的各位專家選出了當(dāng)時(shí)的十大數(shù)據(jù)挖掘算法( top 10 data mining algorithms )����,可以參加文獻(xiàn)【1】, K最近鄰算法即位列其中�����。
二�����、在Matlab中利用kNN進(jìn)行最近鄰查詢
如果手頭有一些數(shù)據(jù)點(diǎn)(以及它們的特征向量)構(gòu)成的數(shù)據(jù)集,對(duì)于一個(gè)查詢點(diǎn)�����,我們?cè)撊绾胃咝У貜臄?shù)據(jù)集中找到它的最近鄰呢��?最通常的方法是基于k-d-tree進(jìn)行最近鄰搜索�。
KNN算法不僅可以用于分類,還可以用于回歸���,但主要應(yīng)用于回歸�����,所以下面我們就演示在MATLAB中利用KNN算法進(jìn)行數(shù)據(jù)挖掘的基本方法�。
首先在Matlab中載入數(shù)據(jù)�����,代碼如下����,其中meas( : , 3:4)相當(dāng)于取出(之前文章中的)Petal.Length和Petal.Width這兩列數(shù)據(jù)����,一共150行�����,三類鳶尾花每類各50行����。
[plain] view plain copy
load fisheriris
x = meas(:,3:4);
然后我們可以借助下面的代碼來用圖形化的方式展示一下數(shù)據(jù)的分布情況:
[plain] view plain copy
gscatter(x(:,1),x(:,2),species)
legend('Location','best')
執(zhí)行上述代碼���,結(jié)果如下圖所示:
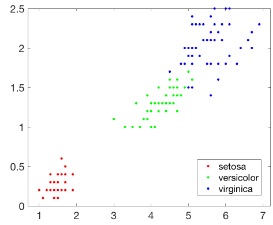
然后我們?cè)谝胍粋€(gè)新的查詢點(diǎn)��,并在圖上把該點(diǎn)用×標(biāo)識(shí)出來:
[plain] view plain copy
newpoint = [5 1.45];
line(newpoint(1),newpoint(2),'marker','x','color','k',...
'markersize',10,'linewidth',2)
結(jié)果如下圖所示:
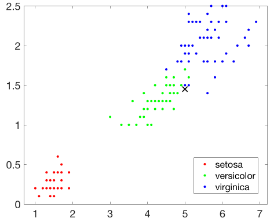
接下來建立一個(gè)基于KD-Tree的最近鄰搜索模型���,查詢目標(biāo)點(diǎn)附近的10個(gè)最近鄰居,并在圖中用圓圈標(biāo)識(shí)出來�����。
[plain] view plain copy
>> Mdl = KDTreeSearcher(x)
Mdl =
KDTreeSearcher with properties:
BucketSize: 50
Distance: 'euclidean'
DistParameter: []
X: [150x2 double]
>> [n,d] = knnsearch(Mdl,newpoint,'k',10);
line(x(n,1),x(n,2),'color',[.5 .5 .5],'marker','o',...
'linestyle','none','markersize',10)
下圖顯示確實(shí)找出了查詢點(diǎn)周圍的若干最近鄰居�����,但是好像只要8個(gè)�,
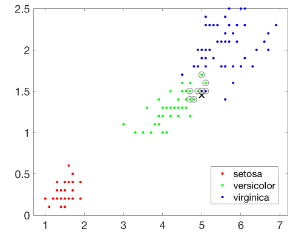
不用著急�,其實(shí)系統(tǒng)確實(shí)找到了10個(gè)最近鄰居���,但是其中有兩對(duì)數(shù)據(jù)點(diǎn)完全重合���,所以在圖上你只能看到8個(gè),不妨把所有數(shù)據(jù)都輸出來看看��,如下所示��,可知確實(shí)是10個(gè)�。
[plain] view plain copy
>> x(n,:)
ans =
5.0000 1.5000
4.9000 1.5000
4.9000 1.5000
5.1000 1.5000
5.1000 1.6000
4.8000 1.4000
5.0000 1.7000
4.7000 1.4000
4.7000 1.4000
4.7000 1.5000
KNN算法中,所選擇的鄰居都是已經(jīng)正確分類的對(duì)象����。該方法在確定分類決策上只依據(jù)最鄰近的一個(gè)或者幾個(gè)樣本的類別來決定待分樣本所屬的類別�。例如下面的代碼告訴我們,待查詢點(diǎn)的鄰接中有80%是versicolor類型的鳶尾花����,所以如果采用KNN來進(jìn)行分類,那么待查詢點(diǎn)的預(yù)測(cè)分類結(jié)果就應(yīng)該是versicolor類型��。
[plain] view plain copy
>> tabulate(species(n))
Value Count Percent
virginica 2 20.00%
versicolor 8 80.00%
在利用 KNN方法進(jìn)行類別決策時(shí),只與極少量的相鄰樣本有關(guān)��。由于KNN方法主要靠周圍有限的鄰近的樣本��,而不是靠判別類域的方法來確定所屬類別的�,因此對(duì)于類域的交叉或重疊較多的待分樣本集來說,KNN方法較其他方法更為適合���。
我們還要說明在Matlab中使用KDTreeSearcher進(jìn)行最近鄰搜索時(shí)�,距離度量的類型可以是歐拉距離('euclidean')、曼哈頓距離('cityblock')����、閔可夫斯基距離('minkowski')、切比雪夫距離('chebychev'),缺省情況下系統(tǒng)使用歐拉距離����。你甚至還可以自定義距離函數(shù)�,然后使用knnsearch()函數(shù)來進(jìn)行最近鄰搜索�����,具體可以查看MATLAB的幫助文檔����,我們不具體展開�����。
三、利用kNN進(jìn)行數(shù)據(jù)挖掘的實(shí)例
下面我們來演示在MATLAB構(gòu)建kNN分類器���,并以此為基礎(chǔ)進(jìn)行數(shù)據(jù)挖掘的具體步驟�����。首先還是載入鳶尾花數(shù)據(jù),不同的是這次我們使用全部四個(gè)特征來訓(xùn)練模型�����。
[plain] view plain copy
load fisheriris
X = meas; % Use all data for fitting
Y = species; % Response data
然后使用fitcknn()函數(shù)來訓(xùn)練分類器模型����。
[plain] view plain copy
>> Mdl = fitcknn(X,Y)
Mdl =
ClassificationKNN
ResponseName: 'Y'
CategoricalPredictors: []
ClassNames: {'setosa' 'versicolor' 'virginica'}
ScoreTransform: 'none'
NumObservations: 150
Distance: 'euclidean'
NumNeighbors: 1
你可以看到默認(rèn)情況下�,最近鄰的數(shù)量為1���,下面我們把它調(diào)整為4����。
[plain] view plain copy
Mdl.NumNeighbors = 4;
或者你可以使用下面的代碼來完成上面同樣的任務(wù):
[plain] view plain copy
Mdl = fitcknn(X,Y,'NumNeighbors',4);
既然有了模型,我們能否利用它來執(zhí)行以下預(yù)測(cè)分類呢�,具體來說此時(shí)我們需要使用predict()函數(shù)�����,例如
[plain] view plain copy
>> flwr = [5.0 3.0 5.0 1.45];
>> flwrClass = predict(Mdl,flwr)
flwrClass =
'versicolor'
最后�����,我們還可以來評(píng)估一下建立的kNN分類模型的情況�。例如你可以從已經(jīng)建好的模型中建立一個(gè)cross-validated 分類器:
[plain] view plain copy
CVMdl = crossval(Mdl);
然后再來看看cross-validation loss,它給出了在對(duì)那些沒有用來訓(xùn)練的數(shù)據(jù)進(jìn)行預(yù)測(cè)時(shí)每一個(gè)交叉檢驗(yàn)?zāi)P偷钠骄鶕p失
[plain] view plain copy
>> kloss = kfoldLoss(CVMdl)
kloss =
0.0333
再來檢驗(yàn)一下resubstitution loss, which�,默認(rèn)情況下,它給出的是模型Mdl預(yù)測(cè)結(jié)果中被錯(cuò)誤分類的數(shù)據(jù)占比�。
[plain] view plain copy
>> rloss = resubLoss(Mdl)
rloss =
0.0400
如你所見,cross-validated 分類準(zhǔn)確度與 resubstitution 準(zhǔn)確度大致相近�����。所以你可以認(rèn)為你的模型在面對(duì)新數(shù)據(jù)時(shí)(假設(shè)新數(shù)據(jù)同訓(xùn)練數(shù)據(jù)具有相同分布的話)����,分類錯(cuò)誤的可能性大約是 4% 。
四�、關(guān)于k值的選擇
kNN算法在分類時(shí)的主要不足在于��,當(dāng)樣本不平衡時(shí)��,如一個(gè)類的樣本容量很大�����,而其他類樣本容量很小時(shí),有可能導(dǎo)致當(dāng)輸入一個(gè)新樣本時(shí)���,該樣本的K個(gè)鄰居中大容量類的樣本占多數(shù)����。因此可以采用權(quán)值的方法(和該樣本距離小的鄰居權(quán)值大)來改進(jìn)����。
從另外一個(gè)角度來說,算法中k值的選擇對(duì)模型本身及其對(duì)數(shù)據(jù)分類的判定結(jié)果都會(huì)產(chǎn)生重要影響���。如果選擇較小的k值����,就相當(dāng)于用較小的領(lǐng)域中的訓(xùn)練實(shí)例來進(jìn)行預(yù)測(cè)����,學(xué)習(xí)的近似誤差會(huì)減小�����,只有與輸入實(shí)例較為接近(相似的)訓(xùn)練實(shí)例才會(huì)對(duì)預(yù)測(cè)結(jié)果起作用���。但缺點(diǎn)是“學(xué)習(xí)”的估計(jì)誤差會(huì)增大。預(yù)測(cè)結(jié)果會(huì)對(duì)近鄰的實(shí)例點(diǎn)非常敏感���。如果臨近的實(shí)例點(diǎn)恰巧是噪聲���,預(yù)測(cè)就會(huì)出現(xiàn)錯(cuò)誤。換言之����,k值的減小意味著整體模型變得復(fù)雜,容易發(fā)成過擬合�。數(shù)據(jù)分析師培訓(xùn)
如果選擇較大的k值,就相當(dāng)于用較大的鄰域中的訓(xùn)練實(shí)例進(jìn)行預(yù)測(cè)���,其優(yōu)點(diǎn)是可以減少學(xué)習(xí)的估計(jì)誤差����,但缺點(diǎn)是學(xué)習(xí)的近似誤差會(huì)增大。這時(shí)與輸入實(shí)例較遠(yuǎn)的(不相似的)訓(xùn)練實(shí)例也會(huì)對(duì)預(yù)測(cè)起作用���,使預(yù)測(cè)發(fā)生錯(cuò)誤�����。k值的增大就意味著整體的模型變得簡(jiǎn)單�。
在應(yīng)用中�����,k值一般推薦取一個(gè)相對(duì)比較小的數(shù)值����。并可以通過交叉驗(yàn)證法來幫助選取最優(yōu)k值��。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試���,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情��;
? 想學(xué)習(xí)CDA考試教材����,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫(kù)��,點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情���;
? 想了解CDA考試含金量�����,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330