梯度下降法分析
梯度下降法的基本思想是函數(shù)沿著其梯度方向增加最快���,反之,沿著其梯度反方向減小最快。在前面的線性回歸和邏輯回歸中,都采用了梯度下降法來求解。梯度下降的迭代公式為:
\(\begin{aligned} \theta_j=\theta_j-\alpha\frac{\partial\;J(\theta)}{\partial\theta_j} \end{aligned} \)
在回歸算法的實(shí)驗(yàn)中���,梯度下降的步長\(\alpha\)為0.01,當(dāng)時也指出了該步長是通過多次時間找到的����,且換一組數(shù)據(jù)后,算法可能不收斂�。為什么會出現(xiàn)這樣的問題呢?從梯度下降法的出發(fā)點(diǎn)可以看到�����,算法指出了行進(jìn)的方向���,但沒有明確要行進(jìn)多遠(yuǎn),那么問題就來了����,步子太小,走個一千一萬年都到不了終點(diǎn)���,而步子太大��,扯到蛋不說��,還可能越跑越遠(yuǎn)�。
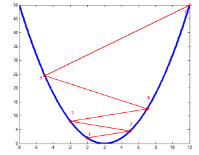
如上圖,藍(lán)色為一個碗形函數(shù)�,其最小值在\(x=2\)那點(diǎn),假如從\(x=0\)開始迭代��,即是圖中點(diǎn)1�����,此時知道應(yīng)該向右走����,但步子太大,直接到點(diǎn)2 了���,同樣點(diǎn)2處知道該往左走��,結(jié)果又跑太遠(yuǎn)到點(diǎn)3了��,…���,這樣越走越偏離我們的終點(diǎn)了����。此情況的驗(yàn)證可以直接把前面回歸算法的步長改大����,比如把線性回歸迭代步長改為10,要不了幾次迭代結(jié)果就是Nan了��。
這樣有一點(diǎn)需要說明下��,同樣的步長\(\alpha\)��,為何從1到2和2到3的長度不一致����?因?yàn)?-6點(diǎn)的梯度是逐步增大的,故雖然步長相同��,但移動的距離卻越來越遠(yuǎn)�����,從而進(jìn)入了一個惡性循環(huán)了�����。
解決方法 對于上面提出的問題�,解決方法有多種,下面就大致來說說���,若有新的方法此處未提及�,歡迎補(bǔ)充���。
1.手動測試法
顧名思義��,此方法需要手動進(jìn)行多次實(shí)驗(yàn)�����,不停調(diào)整參數(shù)��,觀測實(shí)驗(yàn)效果�����,最終來確定出一個最優(yōu)的步長��。那么如何判斷實(shí)驗(yàn)效果的好壞呢����?一種常用的方法是觀察代價函數(shù)(對線性回歸而言)的變化趨勢,如果迭代結(jié)束后���,代價函數(shù)還在不停減少����,則說明步長過?。蝗舸鷥r函數(shù)呈現(xiàn)出振蕩現(xiàn)象���,則說明步長過大�����。如此多次調(diào)整可得到較合理的步長值�。
顯然��,該方法給出的步長對于這組訓(xùn)練樣本而言是相對較優(yōu)的�,但換一組樣本,則需要重新實(shí)驗(yàn)來調(diào)整參數(shù)了�;另外,該方法可能會比較累人~~
2.固定步進(jìn)
這是一個非常保險(xiǎn)的方法����,但需要舍棄較多的時間資源。既然梯度下降法只給出方向���,那么我們就沿著這個方向走固定路程�,即將梯度下降迭代公式修改為:
\(\begin{aligned} \theta_j=\theta_j-\alpha\;sign({\frac{\partial\;J(\theta)}{\partial\theta_j}}) \end{aligned} \)
其中的\(sign\)是符號函數(shù)����。
那么\(\alpha\)取多大呢?就取可容許的最小誤差���,這樣的迭代方式可以保證必然不會跨過最終點(diǎn)��,但需要耗費(fèi)更多次迭代���。
3.步長衰減
步長衰減主要考慮到越接近終點(diǎn),每一步越需要謹(jǐn)慎�,故把步長減小,寧肯多走幾步也絕不踏錯一步���。在吳恩達(dá)公開課中�����,他也提到了可在迭代中逐步減少步長����。那如何減少步長?通?���?梢杂羞@么幾種做法:
A.固定衰減。比如每次迭代后���,步長衰減為前一次的某個比例(如95%)�����。
B.選擇性衰減��。根據(jù)迭代狀態(tài)來確定本次是否衰減���,可以根據(jù)梯度或代價函數(shù)的情況來確定。比如����,若此次迭代后代價函數(shù)增加了,則說明上次迭代步長過大�,需要減小步長�����,否則保持不變,這么做的一個缺點(diǎn)是需要不停計(jì)算代價函數(shù)����,訓(xùn)練樣本過多可能會大大增加耗時;也可以根據(jù)梯度變化情況來判斷���,我們知道我們的終點(diǎn)是梯度為0的地方���,若本次迭代后的梯度與前一次的梯度方向相反,則說明跨過了終點(diǎn)��,需要減小步長����。
顯然,采用步長衰減的方式�����,同樣也依賴于初始步長��,否則可能不收斂。當(dāng)然其相對于固定步長��,則會更具穩(wěn)定性�。
4.自適應(yīng)步長
此方法思想來源與步長衰減。在每次迭代����,按照下面步驟來計(jì)算步長:
A.設(shè)置一個較大的初始步長值
B.計(jì)算若以此步長移動后的梯度
C.判斷移動前后梯度方向是否會改變,若有改變�����,將步長減半���,再進(jìn)行A步���;否則,以此步長為本次迭代的步長���。
還是以上面那個圖像來說明下��。首先�,初始點(diǎn)1在\(x=0\)處�����,按照初始步長則應(yīng)該移動到點(diǎn)2\(x=5\)處,可點(diǎn)1和2處梯度方向改變了,那邊步長減半則應(yīng)該到點(diǎn)A\(x=2.5\)處,點(diǎn)1與A的梯度還是不同��,那再將步長減半�,則移動到點(diǎn)B\(x=1.25\)處�����,由于點(diǎn)1與B的梯度方向相同�����,則此次迭代將從1移動到B����。
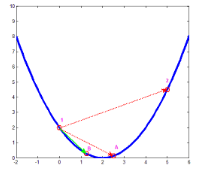
顯然,該方法不會收到初始步長的影響��,每次自動計(jì)算使得不會跨過終點(diǎn)的最大步長值����。另一方面��,從計(jì)算量上講��,有可能會比原來的方式更大����,畢竟有得有失�����,你不用自己去一次次修改參數(shù)->運(yùn)行程序->觀察結(jié)果->…->修改參數(shù)�。具體代碼只需對原回歸算法的代碼略做修改即可。
將原回歸算法迭代中的2行代碼
1 Grad = CalcGrad(TX, TY, Theta, fun);
2 Theta = Theta + Alpha .* Grad;
修改為
1 Alpha = 16 * ones(n, 1);
2 Theta0 = Theta;
3 Grad0 = CalcGrad(TX, TY, Theta0, fun);
4 while(min(Alpha) > eps)
5 Theta1 = Theta0 + Alpha .* Grad0;
6 Grad1 = CalcGrad(TX, TY, Theta1, fun);
7 s = sign(Grad1 .* Grad0);
8 if (min(s)>=0)
9 break;
10 end
11
12 s(s==-1) = 0.5;
13 s(s==0) = 1;
14 Alpha = Alpha .* s;
15 end
16 Grad = Grad0;
17 Theta=Theta1;
View Code
即可實(shí)現(xiàn)����。
補(bǔ)充說明
上面的說明是針對每一維的,對于步長需要每一維計(jì)算��。若需要所有維度使用同一個步長��,請先將訓(xùn)練樣本歸一化��,否則很可能收斂不到你想要的結(jié)果。數(shù)據(jù)分析師培訓(xùn)
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試�,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情;
? 想學(xué)習(xí)CDA考試教材�����,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫���,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330