批量梯度下降與隨機梯度下降
下面的h(x)是要擬合的函數(shù)��,J(theta)損失函數(shù)��,theta是參數(shù)���,要迭代求解的值���,theta求解出來了那最終要擬合的函數(shù)h(theta)就出來了�。其中m是訓練集的記錄條數(shù),j是參數(shù)的個數(shù)����。
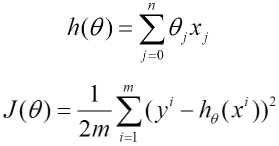
1�、批量梯度下降(BGD)的求解思路如下:
(1)將J(theta)對theta求偏導,得到每個theta對應的的梯度
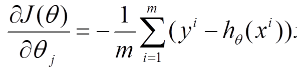
(2)由于是要最小化風險函數(shù)���,所以按每個參數(shù)theta的梯度負方向���,來更新每個theta
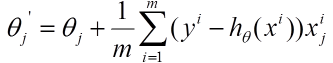
(3)從上面公式可以注意到����,它得到的是一個全局最優(yōu)解�,但是每迭代一步,都要用到訓練集所有的數(shù)據��,如果m很大�,那么可想而知這種方法的迭代速度?�?!所以���,這就引入了另外一種方法��,隨機梯度下降���。
2����、隨機梯度下降(SGD)的求解思路如下:
(1)上面的風險函數(shù)可以寫成如下這種形式,損失函數(shù)對應的是訓練集中每個樣本的粒度,而上面批量梯度下降對應的是所有的訓練樣本:
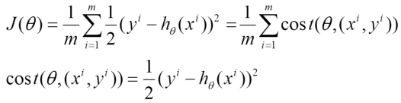
注意:cost不是cosine t 是costfunction的簡寫
(2)每個樣本的損失函數(shù),對theta求偏導得到對應梯度,來更新theta
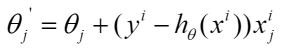
(3)隨機梯度下降是通過每個樣本來迭代更新一次,如果樣本量很大的情況(例如幾十萬)���,那么可能只用其中幾萬條或者幾千條的樣本(每次迭代隨機選取一個樣本點��,只是迭代次數(shù)比BGD要多)���,就已經將theta迭代到最優(yōu)解了,對比上面的批量梯度下降�����,迭代一次需要用到十幾萬訓練樣本����,一次迭代不可能最優(yōu)��,如果迭代10次的話就需要遍歷訓練樣本10次��。但是,SGD伴隨的一個問題是噪音較BGD要多,使得SGD并不是每次迭代都向著整體最優(yōu)化方向����。對步長選擇敏感����,可能會出現(xiàn)overshoot the minimum。
3、方法比較:
梯度下降法是批量更新算法,隨機梯度是在線算法
梯度法優(yōu)化的是經驗風險���,隨機梯度法優(yōu)化的是泛化風險
梯度法可能陷入局部最優(yōu),隨機梯度可能找到全局最優(yōu)
梯度法對步長不敏感��,隨機梯度對步長選擇敏感
梯度法對初始點(參數(shù))選擇敏感
4���、對于上面的linear regression問題���,與批量梯度下降對比,隨機梯度下降求解的會是最優(yōu)解嗎?
(1)批量梯度下降---最小化所有訓練樣本的損失函數(shù),使得最終求解的是全局的最優(yōu)解,即求解的參數(shù)是使得風險函數(shù)最小��。
(2)隨機梯度下降---最小化每條樣本的損失函數(shù)��,雖然不是每次迭代得到的損失函數(shù)都向著全局最優(yōu)方向�����, 但是大的整體的方向是向全局最優(yōu)解的�����,最終的結果往往是在全局最優(yōu)解附近。(數(shù)學證明過程)
5、梯度下降用來求最優(yōu)解,哪些問題可以求得全局最優(yōu)?哪些問題可能局部最優(yōu)解?
最優(yōu)化問題對theta的分布是unimodal��,即從圖形上面看只有一個peak�,所以梯度下降最終求得的是全局最優(yōu)解��。然而對于multimodal的問題�,因為存在多個peak值,很有可能梯度下降的最終結果是局部最優(yōu)���。數(shù)據分析師培訓
CDA數(shù)據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�����,點擊>>>
“CDA報名”
了解CDA考試詳情�����;
? 想學習CDA考試教材�����,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫,點擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量���,點擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330