機(jī)器學(xué)習(xí)中使用的神經(jīng)網(wǎng)絡(luò)
這一小節(jié)介紹隨機(jī)梯度下降法(stochastic gradient descent)在神經(jīng)網(wǎng)絡(luò)中的使用,這里首先回顧了第三講中介紹的線性神經(jīng)網(wǎng)絡(luò)的誤差曲面(error surface)�,如下圖所示。線性神經(jīng)網(wǎng)絡(luò)對(duì)應(yīng)的誤差曲面的縱截面如碗裝����,橫截面則如一組同心的橢圓。梯度下降法的作用就是不斷調(diào)整參數(shù)����,使得模型的誤差由“碗沿”降到“碗底”,參數(shù)由橢圓外部移動(dòng)到橢圓的中心附近�。當(dāng)然,這里說的是只有兩個(gè)參數(shù)的情況���,參數(shù)更多的情況則更復(fù)雜���。

下圖給出了梯度方向?qū)μ荻雀淖兇笮〉挠绊憽?

下圖說明了學(xué)習(xí)步長(zhǎng)(learning rate)對(duì)損失函數(shù)改變的影響。過大的學(xué)習(xí)速率會(huì)導(dǎo)致損失函數(shù)越來越大,模型距離最優(yōu)解(或次優(yōu)解)越來越遠(yuǎn)���。

上面是模型在所有的訓(xùn)練數(shù)據(jù)上做完梯度下降法之后再對(duì)參數(shù)進(jìn)行修正的���,這叫做批量梯度下降法(batch gradient descent)。而隨機(jī)梯度下降法則是每一次計(jì)算某一個(gè)訓(xùn)練數(shù)據(jù)上的梯度或者某一組訓(xùn)練數(shù)據(jù)(訓(xùn)練數(shù)據(jù)集的一個(gè)很小的子集)的梯度���,然后更新參數(shù)����。在每一個(gè)訓(xùn)練數(shù)據(jù)上計(jì)算梯度然后更新參數(shù)的稱之為在線學(xué)習(xí)(online learning)���,在一小組訓(xùn)練數(shù)據(jù)上計(jì)算梯度然后更新參數(shù)的稱之為小批量梯度下降法(mini-batch gradient descent)�,后者的效果可能比前者好一些����。

下圖是對(duì)使用mini-batch gradient descent的幾點(diǎn)建議。

A bag of tricks for mini-batch gradient descent
這一小節(jié)介紹使用小批量梯度下降法(mini-batch gradient descent)的一些技巧���。下圖是初始化權(quán)值參數(shù)的技巧����。

下圖介紹的是shifting the inputs,其是指給輸入的每一個(gè)分量加上一個(gè)常數(shù)值��,使不得輸入的平均值為0��。(這里的意思應(yīng)該是給輸入的每一個(gè)分量加上一個(gè)常數(shù)�,不同分量的常數(shù)可能不同,使得訓(xùn)練數(shù)據(jù)集的所有輸入加在一起是個(gè)零向量����。當(dāng)然����,這是我自己的理解,可能有出入����。)下圖給出了一個(gè)二維的線性神經(jīng)網(wǎng)絡(luò),且給出了兩組訓(xùn)練數(shù)據(jù)及其相應(yīng)向量參數(shù)對(duì)應(yīng)的直線�����?���?梢钥吹缴厦娴哪莾蓷l直線夾角很小,二者結(jié)合在一起就會(huì)得到一個(gè)很狹長(zhǎng)的橢圓的error surface,這樣的是我們不喜歡的error surface�,不利于快速找到最優(yōu)解或次優(yōu)解。下面我們給輸入的每一個(gè)分量都加上一個(gè)-100��,然后得到的error surface就有一個(gè)比較接近圓的形狀��,這樣的是我們想要的����,便于快速的找到最優(yōu)解或次優(yōu)解。另外這里還提到了對(duì)隱匿層神經(jīng)單元的調(diào)整�,比較了雙曲正切函數(shù)(hyperbolic tangent function)和邏輯函數(shù)(logistic function),但是這里沒聽明白具體怎么使用����。

下圖介紹的是scaling the inputs,該情況針對(duì)的是輸入向量的分量取值相差懸殊時(shí)��,通過給分量乘上一個(gè)系數(shù)來使得error surface更接近圓形���,從而便于快速找到最優(yōu)解或次優(yōu)解�����。
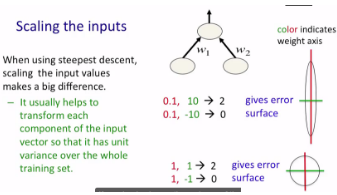
一個(gè)更thorough的方法是去除輸入向量不同分量之間的相關(guān)性(decorrelate the input components)��,相關(guān)的方法很多����,這里給出了主成分分析法(PCA, Principal Components Analysis)。在Andrew Ng的課程中詳細(xì)介紹過PCA�,詳細(xì)內(nèi)容請(qǐng)閱讀Machine Learning第八周筆記:K-means和降維
。對(duì)于線性模型�����,PCA實(shí)現(xiàn)了降維����,從而將橢圓形的error surface轉(zhuǎn)換成了圓形的���。

下圖列出了在多層神經(jīng)網(wǎng)絡(luò)中經(jīng)常遇到的兩個(gè)問題�����。一個(gè)是�,當(dāng)我們以很大的學(xué)習(xí)步長(zhǎng)(learning rate)開始訓(xùn)練網(wǎng)絡(luò)時(shí)���,隱匿單元的權(quán)重往往會(huì)取到很大的正數(shù)或很小的負(fù)數(shù)�����,而此時(shí)這些權(quán)重對(duì)應(yīng)的梯度又很小�����,給我們?cè)斐梢环N模型好像取得了一個(gè)局部最小值��。另一個(gè)是,在分類網(wǎng)絡(luò)中,我們經(jīng)常使用平方誤差或者交叉熵誤差���,一個(gè)好的策略是讓每一個(gè)輸出單元的輸出情況和實(shí)際上的輸出比例相當(dāng)(實(shí)際上輸出1的比例是多少,那么輸出單元的輸出情況一個(gè)就是這樣)。神經(jīng)網(wǎng)絡(luò)很快就會(huì)發(fā)現(xiàn)這一策略��,但需要很長(zhǎng)的時(shí)間才能一點(diǎn)點(diǎn)的優(yōu)化網(wǎng)絡(luò)�,看起來就好像模型處于一個(gè)局部最小值附近����。

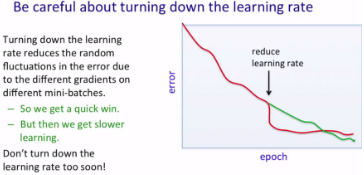
下圖提示我們不要太快得減小學(xué)習(xí)步長(zhǎng)(learning rate)。
下面給出四種加快mini-batch learning的方法�����,前三種我們會(huì)在下面一一介紹���,最后一種本課程不涉及���,感興趣的話請(qǐng)自行搜索���。這些方法具有很強(qiáng)的技巧性,需要我們?cè)趹?yīng)用中不斷摸索�����。

The momentum method
這一小節(jié)詳細(xì)介紹動(dòng)量方法(the momentum method)��,其應(yīng)用很廣泛�����,在full-batch learning和mini-batch learning中都可以使用��。下面給出了動(dòng)量方法的intuition和計(jì)算公式��。

Using momentum speeds up gradient descent learning because
Directions of consistent change get amplified.
Directions of fluctuations get damped.
Allows using much larger learning rates.
Momentum accumulates consistent components of the gradient and attenuates the fluctuating ones. It also allows us to use bigger learning rate because the learning is now more stable.
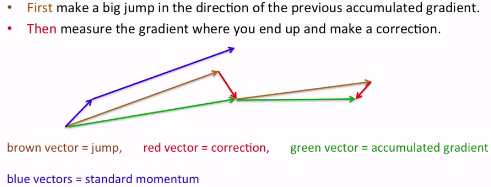
標(biāo)準(zhǔn)的動(dòng)量方法(由Nesterov在1983年提出)是在當(dāng)前位置計(jì)算梯度���,然后在累積的更新梯度方向上做一個(gè)大的跳躍。下面給出了一種更好地動(dòng)量方法(由IIya Sutskever在2012年提出)�,其先在先前累積的梯度方向上做一個(gè)大的跳躍���,再計(jì)算新的梯度并修正錯(cuò)誤。
下面對(duì)兩種方法做了比較�����,圖中藍(lán)色箭頭是做兩次標(biāo)準(zhǔn)動(dòng)量方法得到的�����;而圖中棕色箭頭是改進(jìn)動(dòng)量方法先做的一次大跳躍得到的�����,紅色箭頭是修正���,綠色箭頭是進(jìn)行一次改進(jìn)動(dòng)量方法得到的����?����?梢钥吹?��,改進(jìn)的比標(biāo)準(zhǔn)的要快很多��。
Adaptive learning rates for each connection
這一小節(jié)介紹the separate, adaptive learning rate for each connection(針對(duì)網(wǎng)絡(luò)中每個(gè)連接的自適應(yīng)學(xué)習(xí)步長(zhǎng))����。其思想是在神經(jīng)網(wǎng)絡(luò)的每一個(gè)連接處都應(yīng)該有該連接自己的自適應(yīng)學(xué)習(xí)步長(zhǎng),并在我們調(diào)整該連接對(duì)應(yīng)的參數(shù)時(shí)調(diào)整自己的學(xué)習(xí)步長(zhǎng):如果權(quán)值參數(shù)修正梯度����,那就應(yīng)該減小步長(zhǎng);反之�,應(yīng)該增大步長(zhǎng)。
下圖給出了intuition���。我的理解是在多層神經(jīng)網(wǎng)絡(luò)中����,不同層的梯度通常相差懸殊��,最開始的幾層對(duì)應(yīng)的梯度可能比最后幾層權(quán)值對(duì)應(yīng)的梯度小幾個(gè)數(shù)量級(jí)�����。另外一方面����,網(wǎng)絡(luò)中每一單元又受其扇入單元的影響,為了修正一個(gè)同樣的錯(cuò)誤����,各個(gè)單元的“學(xué)習(xí)步長(zhǎng)”應(yīng)該是不同的。

一個(gè)可行的方法是有一個(gè)全局的學(xué)習(xí)步長(zhǎng)����,然后對(duì)每一個(gè)權(quán)值參數(shù)有一個(gè)local gain,用gij表示�。初始時(shí)gij均取值為1,后每次迭代根據(jù)權(quán)值梯度的變化情況作出調(diào)整���,具體調(diào)整公式如下圖所示����。

下圖列出了幾種提高自適應(yīng)學(xué)習(xí)步長(zhǎng)性能的幾個(gè)技巧����。

Rmsprop: Divide the gradient by a running average of its recent magnitude
這一小節(jié)介紹rmsprop算法。在網(wǎng)上找到一個(gè)python模塊——climin��,一個(gè)做優(yōu)化的機(jī)器學(xué)習(xí)包,里面包含了很多優(yōu)化算法����。
首先介紹rprop算法。前面我們說過�,不同權(quán)值參數(shù)的梯度的數(shù)量級(jí)可能相差很大,因此很難找到一個(gè)全局的學(xué)習(xí)步長(zhǎng)�����。這時(shí)���,我們想到了在full-batch learning中僅靠權(quán)值梯度的符號(hào)來選擇學(xué)習(xí)步長(zhǎng)���。rprop算法正是采用這樣的思想:對(duì)于網(wǎng)絡(luò)中的每一個(gè)權(quán)值參數(shù),當(dāng)其對(duì)應(yīng)的前面兩個(gè)梯度符號(hào)相同時(shí)���,則增大該權(quán)值參數(shù)對(duì)應(yīng)的學(xué)習(xí)步長(zhǎng)���;反之,則減小對(duì)應(yīng)的學(xué)習(xí)步長(zhǎng)����。并且�,rprop算法將每一個(gè)權(quán)值對(duì)應(yīng)的學(xué)習(xí)步長(zhǎng)限制在百萬分之一到50之間�。

下圖解釋了prop算法為什么不能應(yīng)用于mini-batch learning中��。因?yàn)閜rop算法違背了隨機(jī)梯度下降的原理:假設(shè)有一個(gè)在線學(xué)習(xí)系統(tǒng)�����,初始的學(xué)習(xí)步長(zhǎng)較小��,在其上應(yīng)用prop算法�。這里有十組訓(xùn)練數(shù)據(jù),前九組都使得梯度符號(hào)與之前的梯度符號(hào)相同�,那么學(xué)習(xí)步長(zhǎng)就會(huì)增加九次;而第十次得來的梯度符號(hào)與之前的相反���,那么學(xué)習(xí)步長(zhǎng)就會(huì)減小一次���。這樣一個(gè)過程下來,學(xué)習(xí)步長(zhǎng)會(huì)增長(zhǎng)很多�,如果系統(tǒng)的訓(xùn)練數(shù)據(jù)集非常之大,那學(xué)習(xí)步長(zhǎng)可能頻繁的來回波動(dòng)��,這樣肯定是不利于學(xué)習(xí)的��。

設(shè)想是否存在這樣一種算法,其既能保持rprop算法的健壯性����,又能應(yīng)用在mini-batch learning上呢,rmsprop算法應(yīng)運(yùn)而生���。rmsprop算法不再孤立地更新學(xué)習(xí)步長(zhǎng)�,而是聯(lián)系之前的每一次梯度變化情況�����,具體如下�。rmsprop算法給每一個(gè)權(quán)值一個(gè)變量MeanSquare(w,t)用來記錄第t次更新步長(zhǎng)時(shí)前t次的梯度平方的平均值,具體計(jì)算方法如下圖所示(注意��,其中的系數(shù)0.9和0.1只是個(gè)例子�����,具體取值還要看具體情況)�����。然后再用第t次的梯度除上MeanSquare(w,t)??????????????√得到學(xué)習(xí)步長(zhǎng)的更新比例���,根據(jù)此比例去得到新的學(xué)習(xí)步長(zhǎng)���。按我的理解�����,如果當(dāng)前得到的梯度為負(fù),那學(xué)習(xí)步長(zhǎng)就會(huì)減小一點(diǎn)點(diǎn)���;如果當(dāng)前得到的梯度為正�����,那學(xué)習(xí)步長(zhǎng)就會(huì)增大一點(diǎn)點(diǎn)���。這里的MeanSquare(w,t)??????????????√是名稱中RMS的由來。數(shù)據(jù)分析師培訓(xùn)

下圖列出了關(guān)于rmsprop算法的一些研究�����,想了解詳情的話請(qǐng)自行搜索�����。

最后一張圖是對(duì)神經(jīng)網(wǎng)絡(luò)學(xué)習(xí)方法的一個(gè)小總結(jié)。

這幾個(gè)算法都比較燒腦啊�,全是憑大腦推理思考,回頭要好好做實(shí)驗(yàn)��。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試���,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情�;
? 想學(xué)習(xí)CDA考試教材�,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫���,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情���;
? 想了解CDA考試含金量,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營許可證編號(hào):京B2-20210330