大數(shù)據(jù)時(shí)代,如何搜集有效數(shù)據(jù)
小編從阿爾茲海默癥成病機(jī)理出發(fā)���,提到了如何對(duì)模型參數(shù)降維的問(wèn)題���。我們先來(lái)復(fù)(Yù)習(xí)(Xí)一下那張圖表:
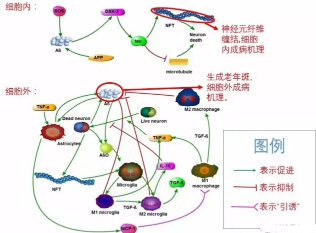
經(jīng)過(guò)復(fù)(Yù)習(xí)(Xí)后,這張圖似乎不再那么催人入眠了���!不僅如此��,而且我們可以使用信息幾何�,這一自?xún)?nèi)而外散發(fā)著高格調(diào)的技術(shù),達(dá)到參數(shù)降維的目的�。正所謂——
一聲驚雷劃冬去,兩鳴鴻雁游春來(lái)����。
三月桃花映山紅,四處玉蘭擬雪白�。
五味醇釀溫心海,六色晨光覆陰霾����。
七刻余暉寓暖陽(yáng),八方云動(dòng)照英才���。
冬去春來(lái)�,良辰美景�,更何況突然有了解決難題的思路,心情大好�����,正該不醉不歸!但回頭仔細(xì)一想�����,讀者們會(huì)發(fā)現(xiàn)還有另一個(gè)大問(wèn)題——數(shù)據(jù)從什么地方得來(lái)呢���?巧婦難為無(wú)米之炊���,就算理論算法再高屋建瓴天花亂墜,若沒(méi)有實(shí)驗(yàn)數(shù)據(jù)的支持���,那也無(wú)異于紙上談兵�。大數(shù)據(jù)時(shí)代��,信息(數(shù)據(jù))的搜集可是極其重要的��。信息(數(shù)據(jù))通常來(lái)源于網(wǎng)絡(luò)����,而如何過(guò)濾掉無(wú)用的數(shù)據(jù)���,提取有效成分�����,這也是公認(rèn)的難題�����。下圖是一個(gè)例子:

提取有效信息的過(guò)程
因此提取有效數(shù)據(jù)的關(guān)鍵在于準(zhǔn)確地抓住信息的特點(diǎn)���,或者關(guān)鍵詞(keywords)����。當(dāng)我們把關(guān)鍵詞輸入到搜索引擎(百度��、谷歌等)后�,這些搜索引擎就會(huì)以一定的優(yōu)先級(jí)返回我們想要的信息。那么搜索引擎是怎么展開(kāi)搜索的呢����?答案:網(wǎng)絡(luò)爬蟲(chóng)或者網(wǎng)絡(luò)蜘蛛(web crawler或web spider,以下簡(jiǎn)稱(chēng)爬蟲(chóng))����。
一、網(wǎng)頁(yè)的本質(zhì)
網(wǎng)是靜態(tài)的���,但爬蟲(chóng)是動(dòng)態(tài)的��,所以爬蟲(chóng)的基本思想就是沿著網(wǎng)頁(yè)(蜘蛛網(wǎng)的節(jié)點(diǎn))上的鏈接的爬取有效信息��。當(dāng)然網(wǎng)頁(yè)也有動(dòng)態(tài)(一般用PHP或ASP等寫(xiě)成��,例如用戶登陸界面就是動(dòng)態(tài)網(wǎng)頁(yè))的��,但如果一張蛛網(wǎng)搖搖欲墜��,蜘蛛會(huì)感到不那么安穩(wěn)��,所以動(dòng)態(tài)網(wǎng)頁(yè)的優(yōu)先級(jí)一般會(huì)被搜索引擎排在靜態(tài)網(wǎng)頁(yè)的后面��。
知道了爬蟲(chóng)的基本思想��,那么具體如何操作呢����?這得從網(wǎng)頁(yè)的基本概念說(shuō)起(本文只討論靜態(tài)網(wǎng)頁(yè))。一個(gè)網(wǎng)頁(yè)有三大構(gòu)成要素�����,分別是html文件、css文件和JavaScript文件���。如果把一個(gè)網(wǎng)頁(yè)看做一棟房子,那么html相當(dāng)于房子外殼�����;css相當(dāng)于地磚涂料�����,美化房子外觀內(nèi)飾����;JavaScript則相當(dāng)于家具電器浴池等,增加房子的功能�����。從上述比喻可以看出�����,html才是網(wǎng)頁(yè)的根本���,畢竟地磚顏料在市場(chǎng)上也有�����,家具電器都可以露天擺設(shè)�,而房子外殼才是獨(dú)一無(wú)二的。
下面就是一個(gè)簡(jiǎn)單網(wǎng)頁(yè)的例子:
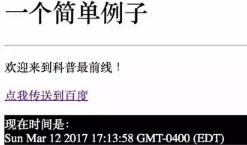
而在爬蟲(chóng)眼里����,這個(gè)網(wǎng)頁(yè)是這樣的:
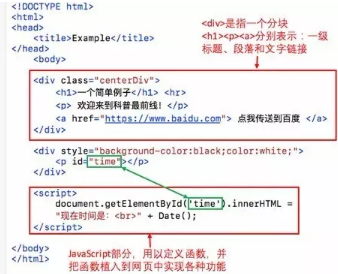
因此網(wǎng)頁(yè)實(shí)質(zhì)上就是超文本(hypertext),網(wǎng)頁(yè)上的所有內(nèi)容都是在形如“<>...</>”這樣的標(biāo)簽之內(nèi)的�����。如果我們要搜集網(wǎng)頁(yè)上的所有超鏈接�,只需尋找所有標(biāo)簽中前面是"href="的字符串,并查看提取出來(lái)的字符串是否以"http"(超文本轉(zhuǎn)換協(xié)議���,https表示安全的http協(xié)議)開(kāi)頭即可�。如果超鏈接不以"http"開(kāi)頭����,那么該鏈接很可能是網(wǎng)頁(yè)所在的本地文件或者ftp或smtp(文件或郵件轉(zhuǎn)換協(xié)議),應(yīng)該過(guò)濾掉����。
二���、爬蟲(chóng)實(shí)例
既然知道了網(wǎng)頁(yè)的本質(zhì),相信讀者們已經(jīng)躍躍欲試了�。為了使讀者更好地理解爬蟲(chóng)的工作原理��,小編將用兩種方式編寫(xiě)一個(gè)最簡(jiǎn)單的爬蟲(chóng)���,用以獲取谷歌首頁(yè)上的所有超鏈接(以http://或https://開(kāi)頭���,過(guò)濾掉本地文件),并把它們存到電子表格(Excel)中�。
從第一節(jié)的分析可以看出,超鏈接出現(xiàn)在標(biāo)簽"<a href="...">... </a>"中�,所以我們只需要匹配關(guān)鍵詞"href="即可?�?紤]到python是最簡(jiǎn)單且使用最廣泛的多用途語(yǔ)言�����,小編以python 3.6版本為例寫(xiě)了如下爬蟲(chóng)�,詳細(xì)注解都在圖片中,有興趣的讀者可以親自嘗試,看看會(huì)出來(lái)什么結(jié)果:

如果采用過(guò)程式編寫(xiě)思路�,代碼還會(huì)更短一些。為圖簡(jiǎn)單���,小編沒(méi)有使用異常處理手段(Exceptional Handling�����,一般指try-exception語(yǔ)句�����,或者條件語(yǔ)句加flag值)�,這種語(yǔ)句可以用于檢查網(wǎng)絡(luò)鏈接是否異常���、搜集文件的過(guò)程是否成功甚至本地文件讀寫(xiě)是否正常等����。這種手段常常被經(jīng)常做計(jì)算機(jī)模擬的科研工作者忽視����,以至于當(dāng)小編把自己寫(xiě)的程序和一些教授討論時(shí),常常被評(píng)論說(shuō)我的程序“很花哨�����,沒(méi)必要寫(xiě)得像商業(yè)程序”。盡管這種手段并非必須�,但經(jīng)小編大量實(shí)踐后發(fā)現(xiàn),當(dāng)編寫(xiě)的代碼過(guò)長(zhǎng)時(shí)����,這種手段實(shí)則可以有效提高程序查錯(cuò)(debug)的效率。尤其是在計(jì)算機(jī)模擬中��,程序中的bug經(jīng)常來(lái)自于內(nèi)存錯(cuò)誤(數(shù)組長(zhǎng)度溢出�、指針錯(cuò)誤等)����,若不采用異常處理手段,這種bug會(huì)非常棘手�。就像戀愛(ài)中的少女一樣,因內(nèi)存錯(cuò)誤造成的程序崩潰可以發(fā)生在任意時(shí)刻任意地點(diǎn)�����,全由計(jì)算機(jī)的心情而定�。
或許不了解編程讀者會(huì)表示異議:“這代碼有足足32行,哪里簡(jiǎn)單了�!”其實(shí)去掉空行和評(píng)論后也就21行�����,也不算太多�����。什么��,還嫌多���?好吧,為了造福更多讀者���,也為了讓大家感受一下21世紀(jì)之前的程序員前輩們是如何碼代碼的����,小編又用Unix的外殼腳本(shell script)把這個(gè)爬蟲(chóng)重新寫(xiě)了一遍��,并命名為"crawler.sh"����。同樣,詳細(xì)注釋盡在圖中(這是所有Unix系統(tǒng)都有的emacs文檔編輯器):
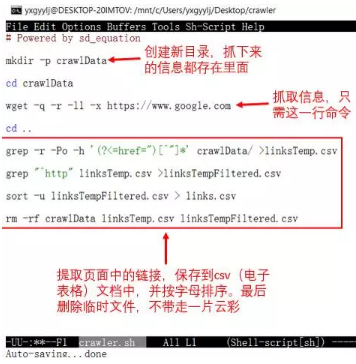
從21行簡(jiǎn)化到只有8行���!執(zhí)行后����,得到的電子表格內(nèi)容是這樣的:
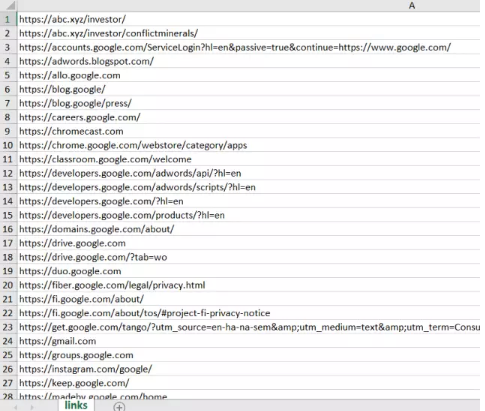
如果經(jīng)過(guò)了嘗試和對(duì)比,讀者可以發(fā)現(xiàn)使用外殼腳本比python多搜集了很多網(wǎng)址���,而且還去掉了重復(fù)的鏈接����。這是因?yàn)椤皐get”命令不僅搜集了谷歌主頁(yè)面上的所有鏈接�����,而且直接把谷歌根目錄里能訪問(wèn)到的文件全都爬了個(gè)遍���。有了這一項(xiàng)技術(shù),我們可以大大豐富電腦E盤(pán)中“三個(gè)代表重要思想”��、“黨章黨規(guī)全集”和“日本現(xiàn)代史研究”等文檔的內(nèi)容�,從而精神境界得到極大提高。
有經(jīng)驗(yàn)的讀者可能注意到了��,小編明明用的是Windows系統(tǒng)的命令指示符(cmd)���,又沒(méi)有安裝虛擬機(jī)��,怎么變成了Unix的外殼腳本呢���?從歷史角度來(lái)講���,Unix和Windows完全是兩個(gè)不同派系,兩者理應(yīng)是互不兼容的���。但事實(shí)上2015年自Win10發(fā)布以后����,微軟官方就宣布Win10可以很簡(jiǎn)易地安裝蘋(píng)果的終端(蘋(píng)果OS系統(tǒng)是Unix系統(tǒng)的一個(gè)分支����,具體方式見(jiàn)文獻(xiàn)[2]),并通過(guò)“bash”命令實(shí)現(xiàn)從cmd到蘋(píng)果終端的轉(zhuǎn)變���,從此告別了Unix虛擬機(jī)的時(shí)代��!值得一提的是��,vim文檔編譯器可以在Windows下直接使用�����;emacs由于功能較多����,需要輸入“sudo apt-get install emacs”命令來(lái)安裝�����。
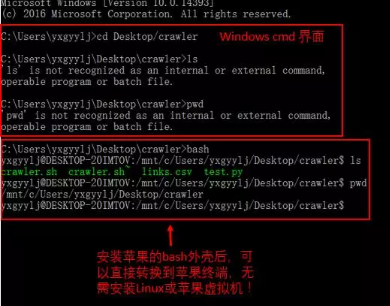
值得一提的是,因?yàn)榱?xí)慣原因���,很多人根深蒂固地認(rèn)為Windows系統(tǒng)更適合家用,Unix系統(tǒng)才適合程序員。其實(shí)時(shí)代一直在變化��,微軟集團(tuán)也在不斷地對(duì)Windows系統(tǒng)進(jìn)行改進(jìn)���,一方面更好地兼容Unix體系,另一方面則開(kāi)發(fā)更為先進(jìn)的外殼平臺(tái)。例如Powershell就是一個(gè)很好的例子��。小編試著用過(guò)Powershell,它的一些語(yǔ)句和Unix外殼腳本頗為類(lèi)似��,同時(shí)也支持對(duì)象的定義,而且還有和編程語(yǔ)言一樣的高度可讀性�。只是對(duì)于習(xí)慣了Unix外殼的程序員而言,Powershell可能顯得不那么熟悉�����。
回到爬蟲(chóng)的話題。經(jīng)過(guò)兩種方式的對(duì)比���,我們可以發(fā)現(xiàn)外殼腳本的巨大優(yōu)勢(shì)——可以與計(jì)算機(jī)硬件直接交流����,這就是為什么程序調(diào)試員往往對(duì)外殼腳本(或匯編語(yǔ)言)滾瓜爛熟的原因��。當(dāng)然作為多用途式的編程語(yǔ)言��,python的其他優(yōu)勢(shì)也不是外殼腳本所具有的�����。在什么場(chǎng)合使用何種語(yǔ)言���,這個(gè)判斷十分重要�����。
三���、守規(guī)矩的爬蟲(chóng)才是好爬蟲(chóng)
當(dāng)一個(gè)爬蟲(chóng)活動(dòng)過(guò)于頻繁時(shí),會(huì)造成網(wǎng)絡(luò)交通堵塞��,因此一些網(wǎng)站很反感陌生的爬蟲(chóng)��。怎么樣限制陌生爬蟲(chóng)的行為呢����?答案就在目標(biāo)網(wǎng)站根目錄的"robot.txt"文件里面,這個(gè)文件規(guī)定了爬蟲(chóng)應(yīng)該遵守的條款���。當(dāng)正常的爬蟲(chóng)開(kāi)始爬取網(wǎng)頁(yè)信息時(shí)���,會(huì)首先檢查robot.txt的規(guī)定并且遵守它�����。例如百度的robot.txt是這樣的:

可見(jiàn)百度只允許少數(shù)幾個(gè)搜索引擎訪問(wèn)�����,所以直接用第二節(jié)的方法爬取百度首頁(yè)是會(huì)被拒絕的。如果確實(shí)有批量作業(yè)的必要����,則應(yīng)該把爬蟲(chóng)的“User-agent”改為上述任一瀏覽器的字符串�,以模仿瀏覽器訪問(wèn)的過(guò)程�����,并且限定爬蟲(chóng)的活動(dòng)頻率。
有的壞爬蟲(chóng)(Bad bots)直接無(wú)視掉robot.txt里的約束�,肆無(wú)忌憚地爬取網(wǎng)頁(yè)信息,不僅可能造成網(wǎng)絡(luò)癱瘓�,還會(huì)出現(xiàn)安全隱患�。如何過(guò)濾掉這些爬蟲(chóng),是網(wǎng)絡(luò)安全領(lǐng)域的一大課題���,尤其是高級(jí)的爬蟲(chóng)會(huì)使用分布式技術(shù)(多個(gè)客戶端分別爬取網(wǎng)頁(yè)�����,用以防止IP被查封)和抓取AJAX(用以模仿JavaScript以爬取動(dòng)態(tài)網(wǎng)頁(yè))等��,這就使得反爬蟲(chóng)的工作變得十分具有挑戰(zhàn)性���。
有趣的是,幾乎每個(gè)大型網(wǎng)站都會(huì)有對(duì)應(yīng)的robot.txt���,而這些文件能在一定程度上反映出不同網(wǎng)站開(kāi)發(fā)者的偏好����。有興趣的讀者可以自行分析。
四�、完整的搜索引擎
搜索引擎要做的當(dāng)然不止普通爬蟲(chóng)那么簡(jiǎn)單。讀者可以思考一下�,當(dāng)你在百度上輸入關(guān)鍵詞“謝雕英雄傳”時(shí),搜索出的結(jié)果會(huì)是“射雕英雄傳”�����,怎么做到的呢�����?顯然還需要文字和網(wǎng)頁(yè)的預(yù)處理(Preporcessing)��。另一方面�,能匹配關(guān)鍵詞的網(wǎng)頁(yè)太多了,總得有個(gè)先后次序吧���。這就是網(wǎng)頁(yè)的排序(Ranking)問(wèn)題[3]����。
預(yù)處理通常有三個(gè)步驟�����,第一是把網(wǎng)頁(yè)中的文字編號(hào)(indexing),這樣匹配關(guān)鍵詞就變成了尋找編號(hào)的的問(wèn)題�����;第二是關(guān)鍵詞溯源(stemming)����,例如去掉“的”、“我”和標(biāo)點(diǎn)符號(hào)等不重要符號(hào)限制�����;第三是提取網(wǎng)頁(yè)中的關(guān)鍵信息���。要記住,瀏覽器眼中的網(wǎng)頁(yè)永遠(yuǎn)都是一堆代碼�,所以需要過(guò)濾掉標(biāo)簽符號(hào)、超鏈接和網(wǎng)頁(yè)排版布局等冗雜信息�����。
網(wǎng)頁(yè)排序的算法有很多�����,不同瀏覽器使用的算法也有不同,但核心都是一樣的——把網(wǎng)絡(luò)看作有向圖(小編在《愛(ài)因斯坦vs阿爾法狗》[4]中提到過(guò)���,這里又出現(xiàn)了)���。網(wǎng)頁(yè)是有向圖的節(jié)點(diǎn),如果網(wǎng)頁(yè)A上有指向網(wǎng)頁(yè)B的鏈接���,那么就形成了一條節(jié)點(diǎn)A到節(jié)點(diǎn)B的箭頭�,有向圖就這么被產(chǎn)生了�。
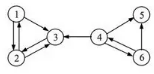
可以看出��,[4]中的神經(jīng)網(wǎng)絡(luò)其實(shí)只是網(wǎng)絡(luò)的一個(gè)特例����。如果一個(gè)網(wǎng)頁(yè)(節(jié)點(diǎn))的鏈接出現(xiàn)在其他很多網(wǎng)頁(yè)上,說(shuō)明這個(gè)網(wǎng)頁(yè)很受歡迎����,理應(yīng)得到較高的排名。事實(shí)上我們可以把這一過(guò)程用馬爾可夫鏈(Markov Chain)表示出來(lái)�����。以谷歌的PageRank算法為例[5]:

由馬爾科夫鏈的遍歷性定理可知,當(dāng)矩陣A滿足不可約和漸進(jìn)無(wú)周期條件時(shí)(irreducible和aperiodic����,也就是網(wǎng)絡(luò)連通,且當(dāng)經(jīng)歷的鏈接夠多時(shí)兩個(gè)網(wǎng)頁(yè)的深度只相差1)�����,以上關(guān)于向量P(把P看作向量����,分量加起來(lái)為1)的方程一定存在穩(wěn)定解。穩(wěn)定解(或者收斂性)是計(jì)算工作者們的最?lèi)?ài)��,因?yàn)橛辛朔€(wěn)定解以后���,就可以通過(guò)迭代算法把這個(gè)穩(wěn)定解找出來(lái),從而得到網(wǎng)頁(yè)排序�����!
一帆風(fēng)順的事并沒(méi)有那么多����,因?yàn)橛蒙厦孢@一方法定義出來(lái)的A未必不可約�����。這就是為什么要額外加一項(xiàng)d���,把右邊這個(gè)矩陣活生生地變得不可約。這就是PageRank算法的精妙之處——看起來(lái)很簡(jiǎn)單���,但簡(jiǎn)單的智慧往往可以創(chuàng)造出巨大的功效����。這也是小編所希望追求的數(shù)學(xué)——簡(jiǎn)單�����,但普適性很高�����。
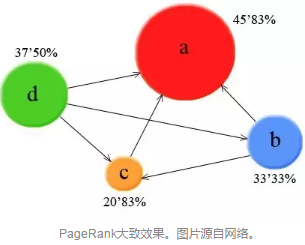
當(dāng)然����,這只是最原始的PageRank算法���。由于不少網(wǎng)站利用這一算法的特點(diǎn),來(lái)千方百計(jì)增加自己的排名(例如把字體和網(wǎng)頁(yè)背景色設(shè)置為一樣的顏色以欺騙搜索引擎)�����,谷歌也不斷在更新自己的算法�����,以達(dá)到精準(zhǔn)和快速兩大目的��。兩者之間的相互較量也構(gòu)成了網(wǎng)絡(luò)領(lǐng)域的另一個(gè)課題����,即垃圾鏈接和垃圾郵件的清理。其中又有很多手段�����,在此不一一介紹了�。
五���、總結(jié)和其他
如果讀者能夠讀懂整篇文章���,那么恭喜�,你已經(jīng)大體掌握了網(wǎng)頁(yè)的本質(zhì)�、簡(jiǎn)單爬蟲(chóng)的實(shí)現(xiàn)和搜索引擎的工作原理這三大互聯(lián)網(wǎng)基礎(chǔ)知識(shí),可以準(zhǔn)確地搜集自己想要的數(shù)據(jù)了�����。比起滿目琳瑯的數(shù)據(jù)處理和分析手段����,數(shù)據(jù)的搜集方式簡(jiǎn)單粗暴,一學(xué)就會(huì)����!
大數(shù)據(jù)時(shí)代,程序員可謂是十分吃香的行業(yè)��,入門(mén)快且收入高����,再多繁忙也可一筆勾銷(xiāo)。但不同于傳統(tǒng)學(xué)科��,計(jì)算機(jī)語(yǔ)言的發(fā)展更新速度十分迅猛�,同一種語(yǔ)言的不同版本都可能發(fā)生巨大的變化���。例如小編在學(xué)習(xí)計(jì)算機(jī)系統(tǒng)的經(jīng)典教材Computer Systems A programmer's Perspective(《深入理解計(jì)算機(jī)系統(tǒng)》)時(shí),在線程控制(Thread Control)那一章花了不少時(shí)間����,因?yàn)樯圆蛔⒁饩蜁?huì)發(fā)生內(nèi)存崩潰。
相信通過(guò)這幅圖能找到不少同道中人
后來(lái)發(fā)現(xiàn)了mpi和openmp這兩個(gè)神奇的工具后����,就再也沒(méi)用過(guò)"Ptheread_join"(加入線程)和"Ptheread_exit"(退出線程)這些老掉牙的命令。和細(xì)胞生物學(xué)類(lèi)似(在小編另一篇文章《護(hù)膚與保養(yǎng)》[6]中提到過(guò))�,計(jì)算機(jī)語(yǔ)言也具有高度可變性,我們需要與時(shí)俱進(jìn)��,做好學(xué)習(xí)新知識(shí)的準(zhǔn)備�。
作為新時(shí)代的弄潮兒,生物和計(jì)算機(jī)領(lǐng)域的人才需求量是巨大的����,這兩個(gè)學(xué)科之間交相輝映相輔相成,頗有幾分上個(gè)世紀(jì)數(shù)學(xué)和物理相互促進(jìn)共同進(jìn)步的味道����。它們能給21世紀(jì)帶來(lái)怎樣的變革?我們?cè)谑媚恳源耐瑫r(shí)��,也應(yīng)當(dāng)做好應(yīng)對(duì)各種變化的準(zhǔn)備�����。古詩(shī)云:
李杜詩(shī)篇萬(wàn)口傳�,至今已覺(jué)不新鮮。
江山代有才人出�����,各領(lǐng)風(fēng)騷數(shù)百年�����。
古人尚有此等遠(yuǎn)見(jiàn)�����,更何況這個(gè)沐浴在大數(shù)據(jù)海洋中���,充滿了機(jī)遇與挑戰(zhàn)的時(shí)代��?
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試�,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情���;
? 想學(xué)習(xí)CDA考試教材�,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫(kù)���,點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情��;
? 想了解CDA考試含金量���,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330