如何在R語言中使用SQL命令
對于有SQL背景的R語言學習者而言,sqldf是一個非常有用的包�����,因為它使我們能在R中使用SQL命令�����。只要掌握了基本的SQL技術��,我們就能利用它們在R中操作數據框��。關于sqldf包的更多信息���,可以參看 cran 。
在這篇文章中,我們將展示如何在R中利用SQL命令來連接��、檢索����、排序和篩選數據。我們也將展示怎么利用R語言的函數來實現這些功能����。最近我在處理一些FDA(譯者注:食品及藥物管理局)的不良事件數據。這些數據非?���;靵y:有缺失值,有重復記錄����,有不同時間建立的數據集的可比性問題,不同數據集中變量名稱和數量也不統一(比如一個數據集里叫sex����,另一個里叫gender),還有疏忽錯誤等問題���。但正因如此�����,這些數據對于數據科學家或者愛好者而言到是理想的練手對象��。
本文使用的FDA不良事件數據可以從公開渠道獲得�����,csv格式的數據表可以從國家經濟研究局下載���。通過R從國家經濟研究局的網站下載數據相對更容易��,我建議你使用相應的R代碼來下載并探索數據���。
不良事件數據集是以季度為發(fā)布周期,每個季度的數據包括了人口信息����、藥物/生物信息、不良事件詳情�,結果和診斷情況等信息。
讓我們下載數據并使用SQL命令來連接�����、排序和篩選該數據集中包含的大量數據框����。
加載R包
require(downloader)
library(dplyr)
library(sqldf)
library(data.table)
library(ggplot2)
library(compare)
library(plotrix)
基本的錯誤處理函數tryCatch()
我們將使用這個函數來處理下載的數據。因為數據以季度頻率發(fā)布�����,每年都會有四個觀測值(每年有四條記錄)�����。運行這個函數能自動下載數據�����,但如果某些季度數據從網上無法獲?����。ㄉ形垂迹?��,該函數會返回一條錯誤信息表示無法找到數據集?����,F在讓我們下載數據的壓縮包并將其解壓�����。
try.error = function(url)
{
try_error = tryCatch(download(url,dest="data.zip"), error=function(e) e)
if (!inherits(try_error, "error")){
download(url,dest="data.zip")
unzip ("data.zip")
}
else if (inherits(try_error, "error")){
cat(url,"not found\n")
}
}
下載不良事件數據
我們可以得到自2004年起的FDA不良事件數據�����。本文將使用2013年以來公布的數據�,我們將檢查截至當前時間的最新數據并下載。
> Sys.time() 函數會返回當前的日期和時間����。數據分析師培訓
> data.table包中的year()函數會從之前返回的當前時間中提取年份信息。
我們將下載人口��、藥物����、診斷/指示,結果和反應(不良事件)數據����。
year_start=2013
year_last=year(Sys.time())
for (i in year_start:year_last){
j=c(1:4)
for (m in j){
url1<-paste0("http://www.nber.org/fda/faers/",i,"/demo",i,"q",m,".csv.zip")
url2<-paste0("http://www.nber.org/fda/faers/",i,"/drug",i,"q",m,".csv.zip")
url3<-paste0("http://www.nber.org/fda/faers/",i,"/reac",i,"q",m,".csv.zip")
url4<-paste0("http://www.nber.org/fda/faers/",i,"/outc",i,"q",m,".csv.zip")
url5<-paste0("http://www.nber.org/fda/faers/",i,"/indi",i,"q",m,".csv.zip")
try.error(url1)
try.error(url2)
try.error(url3)
try.error(url4)
try.error(url5)
}
}
http://www.nber.org/fda/faers/2015/demo2015q4.csv.zip not found
...
http://www.nber.org/fda/faers/2016/indi2016q4.csv.zip not found
根據上面的錯誤信息,截至成文時間(2016年3月13日)���,我們最多可以獲得2015年第三季度的不良事件數據����。
> list.files()函數會字符串向量的形式返回當前工作目錄下所有文件的名字���。
> 我會使用正則表達式對各個數據集的類別進行篩選���。比如^demo.*.csv表示所有名字以demo開頭的csv文件。
filenames <- list.files(pattern="^demo.*.csv", full.names=TRUE)
cat('We have downloaded the following quarterly demography datasets')
filenames
我們已經下載了下列季度人口數據
"./demo2012q1.csv" "./demo2012q2.csv" "./demo2012q3.csv" "./demo2012q4.csv" "./demo2013q1.csv" "./demo2013q2.csv" "./demo2013q3.csv" "./demo2013q4.csv" "./demo2014q1.csv" "./demo2014q2.csv" "./demo2014q3.csv" "./demo2014q4.csv" "./demo2015q1.csv" "./demo2015q2.csv" "./demo2015q3.csv"
讓我們用data.table包中的fread()函數來讀入這些數據集����,以人口數據為例:
demo=lapply(filenames,fread)
接著讓我們把它們轉換數據結構并合并成一個數據框:
demo_all=do.call(rbind,lapply(1:length(demo),function(i) select(as.data.frame(demo[i]),primaryid,caseid, age,age_cod,event_dt,sex,reporter_country)))
dim(demo_all)
3554979 7
我們看到人口數據有超過350萬行觀測(記錄)。
譯者注:下面的內容都是重復這個流程�����,可以略過
現在讓我們合并所有的藥品數據
filenames <- list.files(pattern="^drug.*.csv", full.names=TRUE)
cat('We have downloaded the following quarterly drug datasets:\n')
filenames
drug=lapply(filenames,fread)
cat('\n')
cat('Variable names:\n')
names(drug[[1]])
drug_all=do.call(rbind,lapply(1:length(drug), function(i) select(as.data.frame(drug[i]),primaryid,caseid, drug_seq,drugname,route)))
我們已經下載了下列季度藥品數據集
"./drug2012q1.csv" "./drug2012q2.csv" "./drug2012q3.csv" "./drug2012q4.csv" "./drug2013q1.csv" "./drug2013q2.csv" "./drug2013q3.csv" "./drug2013q4.csv" "./drug2014q1.csv" "./drug2014q2.csv" "./drug2014q3.csv" "./drug2014q4.csv" "./drug2015q1.csv" "./drug2015q2.csv" "./drug2015q3.csv"
每張表中的變量名分別為:
"primaryid" "drug_seq" "role_cod" "drugname" "val_vbm" "route" "dose_vbm" "dechal" "rechal" "lot_num" "exp_dt" "exp_dt_num" "nda_num"
合并所有的診斷/指示數據集
filenames <- list.files(pattern="^indi.*.csv", full.names=TRUE)
cat('We have downloaded the following quarterly diagnoses/indications datasets:\n')
filenames
indi=lapply(filenames,fread)
cat('\n')
cat('Variable names:\n')
names(indi[[15]])
indi_all=do.call(rbind,lapply(1:length(indi), function(i) select(as.data.frame(indi[i]),primaryid,caseid, indi_drug_seq,indi_pt)))
已經下載的數據集為:
"./indi2012q1.csv" "./indi2012q2.csv" "./indi2012q3.csv" "./indi2012q4.csv" "./indi2013q1.csv" "./indi2013q2.csv" "./indi2013q3.csv" "./indi2013q4.csv" "./indi2014q1.csv" "./indi2014q2.csv" "./indi2014q3.csv" "./indi2014q4.csv" "./indi2015q1.csv" "./indi2015q2.csv" "./indi2015q3.csv"
變量名為:
"primaryid" "caseid" "indi_drug_seq" "indi_pt"
合并病人的結果數據:
filenames <- list.files(pattern="^outc.*.csv", full.names=TRUE)
cat('We have downloaded the following quarterly patient outcome datasets:\n')
filenames
outc_all=lapply(filenames,fread)
cat('\n')
cat('Variable names\n')
names(outc_all[[1]])
names(outc_all[[4]])
colnames(outc_all[[4]])=c("primaryid", "caseid", "outc_cod")
outc_all=do.call(rbind,lapply(1:length(outc_all), function(i) select(as.data.frame(outc_all[i]),primaryid,outc_cod)))
下載的數據集如下:
"./outc2012q1.csv" "./outc2012q2.csv" "./outc2012q3.csv" "./outc2012q4.csv" "./outc2013q1.csv" "./outc2013q2.csv" "./outc2013q3.csv" "./outc2013q4.csv" "./outc2014q1.csv" "./outc2014q2.csv" "./outc2014q3.csv" "./outc2014q4.csv" "./outc2015q1.csv" "./outc2015q2.csv" "./outc2015q3.csv"
變量名:
"primaryid" "outc_cod"
"primaryid" "caseid" "outc_code"
最后來合并反應(不良事件)數據集(譯者注:這部分無聊地我要哭了)
filenames <- list.files(pattern="^reac.*.csv", full.names=TRUE)
cat('We have downloaded the following quarterly reaction (adverse event) datasets:\n')
filenames
reac=lapply(filenames,fread)
cat('\n')
cat('Variable names:\n')
names(reac[[3]])
reac_all=do.call(rbind,lapply(1:length(indi), function(i) select(as.data.frame(reac[i]),primaryid,pt)))
下載的數據集有:
"./reac2012q1.csv" "./reac2012q2.csv" "./reac2012q3.csv" "./reac2012q4.csv" "./reac2013q1.csv" "./reac2013q2.csv" "./reac2013q3.csv" "./reac2013q4.csv" "./reac2014q1.csv" "./reac2014q2.csv" "./reac2014q3.csv" "./reac2014q4.csv" "./reac2015q1.csv" "./reac2015q2.csv" "./reac2015q3.csv"
變量名為:
"primaryid" "pt"
讓我們看看不同的數據類型各有多少行
all=as.data.frame(list(Demography=nrow(demo_all),Drug=nrow(drug_all),
Indications=nrow(indi_all),Outcomes=nrow(outc_all),
Reactions=nrow(reac_all)))
row.names(all)='Number of rows'
all

SQL命令=
記住sqldf包使用SQLite
COUNT
# SQL版本
sqldf("SELECT COUNT(primaryid)as 'Number of rows of Demography data'
FROM demo_all;")

# R版本
nrow(demo_all)
3554979
LIMIT命令(顯示前幾行)
# SQL版本
sqldf("SELECT *
FROM demo_all
LIMIT 6;")
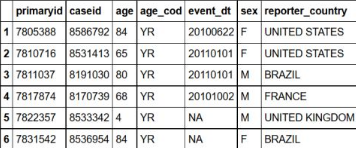
# R版本
head(demo_all,6)
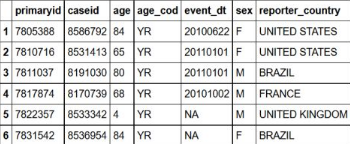
R1=head(demo_all,6)
SQL1 =sqldf("SELECT *
FROM demo_all
LIMIT 6;")
all.equal(R1,SQL1)
TRUE
*譯者注:這部分代碼驗證了SQL命令和R代碼的等價性��,下同���。
WHERE命令
SQL2=sqldf("SELECT * FROM demo_all WHERE sex ='F';")
R2 = filter(demo_all, sex=="F")
identical(SQL2, R2)
TRUE
SQL3=sqldf("SELECT * FROM demo_all WHERE age BETWEEN 20 AND 25;")
R3 = filter(demo_all, age >= 20 & age <= 25)
identical(SQL3, R3)
TRUE
GROUP BY 和 ORDER BY
# SQL版本
sqldf("SELECT sex, COUNT(primaryid) as Total
FROM demo_all
WHERE sex IN ('F','M','NS','UNK')
GROUP BY sex
ORDER BY Total DESC ;")
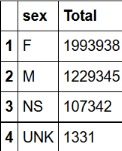
# R版本
demo_all %>% filter(sex %in%c('F','M','NS','UNK')) %>% group_by(sex) %>%
summarise(Total = n()) %>% arrange(desc(Total))
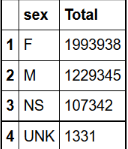
SQL3 = sqldf("SELECT sex, COUNT(primaryid) as Total
FROM demo_all
GROUP BY sex
ORDER BY Total DESC ;")
R3 = demo_all%>%group_by(sex) %>%
summarise(Total = n())%>%arrange(desc(Total))
compare(SQL3,R3, allowAll=TRUE)
TRUE
dropped attributes
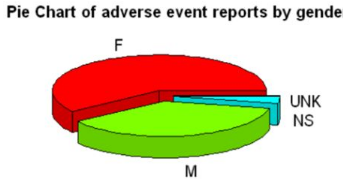
利用SQL命令進行數據清洗并繪制3D餅圖
SQL=sqldf("SELECT sex, COUNT(primaryid) as Total
FROM demo_all
WHERE sex IN ('F','M','NS','UNK')
GROUP BY sex
ORDER BY Total DESC ;")
SQL$Total=as.numeric(SQL$Total
pie3D(SQL$Total, labels = SQL$sex,explode=0.1,col=rainbow(4),
main="Pie Chart of adverse event reports by gender",cex.lab=0.5, cex.axis=0.5, cex.main=1,labelcex=1)
輸出的圖如下:
Inner Join
讓我們把藥品數據和指數數據基于主id和藥品序列內連���。
首先����,我們要檢查下變量名�����,看看如何合并兩個數據集��。
names(indi_all)
names(drug_all)
"primaryid" "indi_drug_seq" "indi_pt"
"primaryid" "drug_seq" "drugname" "route"
names(indi_all)=c("primaryid", "drug_seq", "indi_pt" ) # 使兩個數據集變量名一致
R4= merge(drug_all,indi_all, by = intersect(names(drug_all), names(indi_all))) # R版本合并
R4=arrange(R3, primaryid,drug_seq,drugname,indi_pt) # R版本排序
SQL4= sqldf("SELECT d.primaryid as primaryid, d.drug_seq as drug_seq, d.drugname as drugname,
d.route as route,i.indi_pt as indi_pt
FROM drug_all d
INNER JOIN indi_all i
ON d.primaryid= i.primaryid AND d.drug_seq=i.drug_seq
ORDER BY primaryid,drug_seq,drugname, i.indi_pt") # SQL版本
compare(R4,SQL4,allowAll=TRUE)
TRUE # 兩種方法等價
R5 = merge(reac_all,outc_all,by=intersect(names(reac_all), names(outc_all)))
SQL5 =reac_outc_new4=sqldf("SELECT r.*, o.outc_cod as outc_cod
FROM reac_all r
INNER JOIN outc_all o
ON r.primaryid=o.primaryid
ORDER BY r.primaryid,r.pt,o.outc_cod")
compare(R5,SQL5,allowAll = TRUE)
TRUE
# 繪制不同性別的年齡概率分布密度圖
ggplot(sqldf('SELECT age, sex
FROM demo_all
WHERE age between 0 AND 100 AND sex IN ("F","M")
LIMIT 10000;'), aes(x=age, fill = sex))+ geom_density(alpha = 0.6)
繪制出的圖如下:
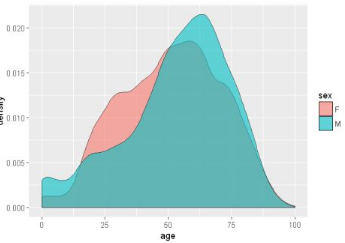
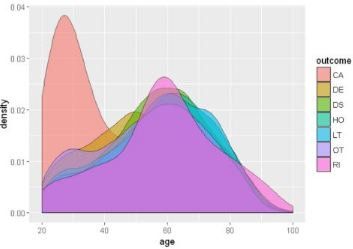
繪制不同結果的年齡年齡概率分布密度圖(譯者注:后面都是結果的可視化�����,可略過����。原作者的耐心真好。��。��。)
ggplot(sqldf("SELECT d.age as age, o.outc_cod as outcome
FROM demo_all d
INNER JOIN outc_all o
ON d.primaryid=o.primaryid
WHERE d.age BETWEEN 20 AND 100
LIMIT 20000;"),aes(x=age, fill = outcome))+ geom_density(alpha = 0.6)
輸出如下:
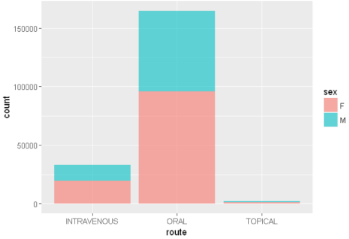
ggplot(sqldf("SELECT de.sex as sex, dr.route as route
FROM demo_all de
INNER JOIN drug_all dr
ON de.primaryid=dr.primaryid
WHERE de.sex IN ('M','F') AND dr.route IN ('ORAL','INTRAVENOUS','TOPICAL')
LIMIT 200000;"),aes(x=route, fill = sex))+ geom_bar(alpha=0.6)
輸出如下:
ggplot(sqldf("SELECT d.sex as sex, o.outc_cod as outcome
FROM demo_all d
INNER JOIN outc_all o
ON d.primaryid=o.primaryid
WHERE d.age BETWEEN 20 AND 100 AND sex IN ('F','M')
LIMIT 20000;"),aes(x=outcome,fill=sex))+ geom_bar(alpha = 0.6)
輸出如下(譯者注:哥們兒挺住�,你就快看完了!?�。�。?
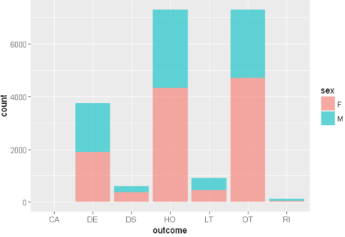
UNION ALL
demo1= demo_all[1:20000,]
demo2=demo_all[20001:40000,]
R6 <- rbind(demo1, demo2)
SQL6 <- sqldf("SELECT * FROM demo1 UNION ALL SELECT * FROM demo2;")
compare(R6,SQL6, allowAll = TRUE)
TRUE
INTERSECT
R7 <- semi_join(demo1, demo2)
SQL7 <- sqldf("SELECT * FROM demo1 INTERSECT SELECT * FROM demo2;")
compare(R7,SQL7, allowAll = TRUE)
TRUE
EXCEPT
R8 <- anti_join(demo1, demo2)
SQL8 <- sqldf("SELECT * FROM demo1 EXCEPT SELECT * FROM demo2;")
compare(R8,SQL8, allowAll = TRUE)
TRUE
翻譯感悟:這篇文章的作者不厭其煩地演示了利用如何sqldf包在R中實現大部分常用的SQL命令����,并將其結果和直接調用相應的R函數的結果做了對照�,證明了二者的等價性。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試���,點擊>>>
“CDA報名”
了解CDA考試詳情;
? 想學習CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫,點擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量��,點擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330