SPSS分析技術(shù):線性回歸分析
相關(guān)分析可以揭示事物之間共同變化的一致性程度����,但它僅僅只是反映出了一種相關(guān)關(guān)系���,并沒有揭示出變量之間準確的可以運算的控制關(guān)系,也就是函數(shù)關(guān)系�,不能解決針對未來的分析與預測問題。
回歸分析就是分析變量之間隱藏的內(nèi)在規(guī)律�,并建立變量之間函數(shù)變化關(guān)系的一種分析方法,回歸分析的目標就是建立由一個因變量和若干自變量構(gòu)成的回歸方程式���,使變量之間的相互控制關(guān)系通過這個方程式描述出來�。
回歸方程式不僅能夠解釋現(xiàn)在個案內(nèi)部隱藏的規(guī)律���,明確每個自變量對因變量的作用程度�。而且���,基于有效的回歸方程�����,還能形成更有意義的數(shù)學方面的預測關(guān)系�����。因此���,回歸分析是一種分析因素變量對因變量作用強度的歸因分析���,它還是預測分析的重要基礎。
回歸分析類型
回歸分析根據(jù)自變量個數(shù)��,自變量冪次以及變量類型可以分為很多類型�����,常用的類型有:
線性回歸���;
曲線回歸����;
二元Logistic回歸技術(shù)�;
線性回歸原理
回歸分析就是建立變量的數(shù)學模型,建立起衡量數(shù)據(jù)聯(lián)系強度的指標���,并通過指標檢驗其符合的程度�。線性回歸分析中,如果僅有一個自變量����,可以建立一元線性模型。如果存在多個自變量����,則需要建立多元線性回歸模型。線性回歸的過程就是把各個自變量和因變量的個案值帶入到回歸方程式當中�����,通過逐步迭代與擬合��,最終找出回歸方程式中的各個系數(shù)�����,構(gòu)造出一個能夠盡可能體現(xiàn)自變量與因變量關(guān)系的函數(shù)式�����。在一元線性回歸中���,回歸方程的確立就是逐步確定唯一自變量的系數(shù)和常數(shù)��,并使方程能夠符合絕大多數(shù)個案的取值特點�����。在多元線性回歸中���,除了要確定各個自變量的系數(shù)和常數(shù)外,還要分析方程內(nèi)的每個自變量是否是真正必須的����,把回歸方程中的非必需自變量剔除。
名詞解釋
線性回歸方程:一次函數(shù)式��,用于描述因變量與自變量之間的內(nèi)在關(guān)系����。根據(jù)自變量的個數(shù),可以分為一元線性回歸方程和多元線性回歸方程�����。
觀測值:參與回歸分析的因變量的實際取值��。對參與線性回歸分析的多個個案來講,它們在因變量上的取值����,就是觀測值。觀測值是一個數(shù)據(jù)序列���,也就是線性回歸分析過程中的因變量����。
回歸值:把每個個案的自變量取值帶入回歸方程后���,通過計算所獲得的數(shù)值�。在回歸分析中�����,針對每個個案�����,都能獲得一個回歸值��。因此����,回歸值也是一個數(shù)據(jù)序列,回歸值的數(shù)量與個案數(shù)相同��。在線性回歸分析中�����,回歸值也常常被稱為預測值���,或者期望值�。
殘差:殘差是觀測值與回歸值的差�。殘差反映的是依據(jù)回歸方程所獲得的計算值與實際測量值的差距。在線性回歸中���,殘差應該滿足正態(tài)分布�,而且全體個案的殘差之和為0�����。
回歸效果評價
在回歸分析的評價中��,通常使用全部殘差的平方之和表示殘差的量度����,而以全體回歸值的平方之和表示回歸的量度����。通常有以下幾個評價指標:
判定系數(shù)
為了能夠比較客觀的評價回歸方程的質(zhì)量���,引入判定系數(shù)R方的概念:

判定系數(shù)R方的值在0~1之間�����,其值越接近1��,表示殘差的比例越低���,即回歸方程的擬合程度越高,回歸值越能貼近觀測值�����,更能體現(xiàn)觀測數(shù)據(jù)的內(nèi)在規(guī)律�。在一般的應用中����,R方大于0.6就表示回歸方程有較好的質(zhì)量�����。
F值
F值是回歸分析中反映回歸效果的重要指標�,它以回歸均方和與殘差均方和的比值表示�,即F=回歸均方和/殘差均方和,在一般的線性回歸中���,F(xiàn)值應該在3.86以上�����。
T值
T值是回歸分析中反映每個自變量的作用力的重要指標�。在回歸分析時���,每個自變量都有自己的T值����,T值以相應自變量的偏回歸系數(shù)與其標準誤差的比值來表示��。在一般的線性回歸分析中��,T的絕對值應該大于1.96�。如果某個自變量的T值小于1.96�,表示這個自變量對方程的影響力很小�����,應該盡可能把它從方程中剔除���。
檢驗概率(Sig值)
回歸方程的檢驗概率值共有兩種類型:整體Sig值和針對每個自變量的Sig值�。整體的Sig值反映了整個方程的影響力�,而針對自變量的Sig值則反映了該自變量在回歸方程中沒有作用的可能性。只有Sig值小于0.05��,才表示有影響力��。
案例分析(一元線性回歸)
現(xiàn)在有一份《大學生學習狀況》的數(shù)據(jù)�,請分析作業(yè)情況與數(shù)學成績之間的關(guān)系,構(gòu)造回歸方程��,并評價回歸分析的效果��。
SPSS分析步驟
1����、選擇菜單【分析】-【回歸】-【線性】命令���,啟動線性回歸命令�����。
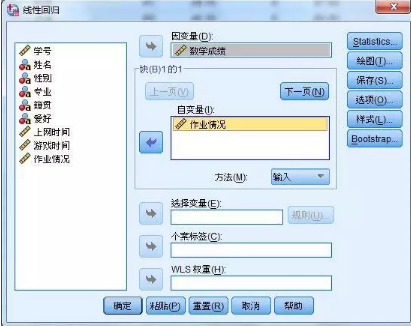
2����、將數(shù)學成績選為因變量,將作業(yè)情況選為自變量����,點擊【確定】。
結(jié)果解釋
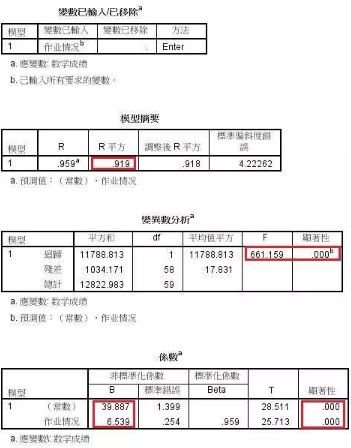
判定系數(shù)R方值為0.919��,表示此回歸方程具有很好的質(zhì)量�。
在方差分析表格中,顯著性為0.000���,小于0.05����,表示回歸方程具有很強的影響力�����,能夠很好的表達數(shù)學成績與作業(yè)情況的控制關(guān)系。
最后一個表格中的B列����,常數(shù)為39.887,作業(yè)情況的系數(shù)為6.539�����,所以回歸方程為y=6.539x+39.887��。
案例分析(多元線性回歸)
分析數(shù)學成績與專業(yè)��、愛好���、作業(yè)情況�����、上網(wǎng)時間和游戲時間之間的關(guān)系����。
分析步驟
1�、字符型數(shù)據(jù)數(shù)值化編碼,將愛好和專業(yè)進行數(shù)值化編碼。
2����、選擇踩踏【分析】-【回歸】-【線性】命令��。
3����、將數(shù)學成績選入因變量,將數(shù)值化后的愛好���、專業(yè)以及上網(wǎng)時間���、游戲時間、作業(yè)情況選為自變量����。
4、在自變量下的選項框中選擇【逐步】����,如下圖:
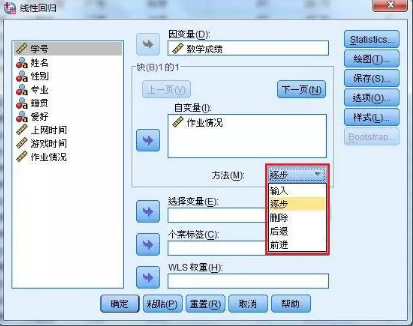
紅框內(nèi)選項含義:
輸入:對于用戶提供的所有自變量,回歸方程全部接納���。
逐步:先檢查不在方程中的自變量��,把F值最大(檢驗概率最?��。┣覞M足進入條件的自變臉選入方程中���,接著,對已經(jīng)進入方程的自變量���,查找滿足移出條件的自變量(F值最小且F檢驗概率滿足移出條件)將其移出��。
前進:對于用戶提供的所有自變量�����,系統(tǒng)計算出所有自變量與因變量的相關(guān)系數(shù)�,每次從尚未進入方程的自變量組中選擇與因變量具有最強正或負相關(guān)系數(shù)的自變量進入方程����,然后檢驗此自變量的影響力,直到?jīng)]有進入方程的自變量都不滿足進入方程的標準為止�����。
后退:對于用戶提供的所有自變量,先讓它們?nèi)繌娦羞M入方程���,再逐個檢查���,剔除不合格變量,直到方程中的所有變量都不滿足移出條件為止��。
刪除:也叫一次性剔除方式�,其思路是通過一次檢驗�,而后剔除全部不合格變量。這種方法不能單獨使用���,通常建立在前面已經(jīng)構(gòu)造出初步的回歸方程的基礎上�,與前面其他篩選方法結(jié)合使用���。
結(jié)果解釋
1����、第一個表格是輸入/移去變量表格�����;
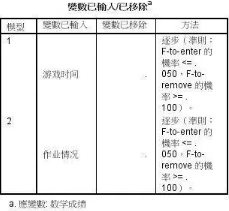
即最后游戲時間和作業(yè)情況被納入到回歸方程當中。
2�����、模型表格和方差分析表格�。這兩個表格表明產(chǎn)生兩個回歸模型,這是游戲時間和作業(yè)情況依次進入回歸過程之后的結(jié)果���,且第二個回歸模型的R方值大于第一個��,所以第二個回歸方程比較好�����。
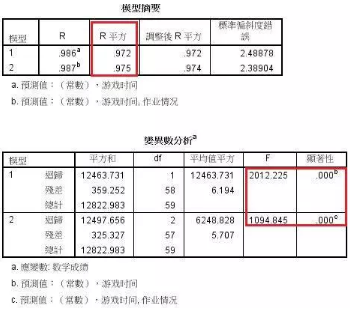
3���、系數(shù)表格;
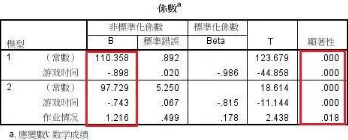
采用第二個回歸模型是y=-0.743*x1+1.216*x2+97.729��,x1代表游戲時間���,x2代表作業(yè)情況���。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認證考試���,點擊>>>
“CDA報名”
了解CDA考試詳情;
? 想學習CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量��,點擊>>> “CDA含金量” 了解CDA考試詳情�����;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330