用R語言建立學(xué)生的學(xué)習(xí)表現(xiàn)和性格特征數(shù)據(jù)模型
一��、項(xiàng)目介紹:
方法包括以下步驟
S1:將個(gè)體表現(xiàn)數(shù)據(jù)輸入到數(shù)據(jù)庫(kù)����;
S2:建立學(xué)習(xí)者的學(xué)習(xí)表現(xiàn)數(shù)據(jù)庫(kù)和性格特征數(shù)據(jù)庫(kù);
S3:建立學(xué)習(xí)者的學(xué)習(xí)表現(xiàn)數(shù)據(jù)模型和性格特征數(shù)據(jù)模型����;
S4:使用數(shù)據(jù)算法計(jì)算學(xué)習(xí)表現(xiàn)數(shù)據(jù);
S5:輸出個(gè)體性格特征��。
步驟(S1)中的個(gè)體表現(xiàn)數(shù)據(jù)為諸如以下類型且不局限于以下類型的個(gè)體表現(xiàn):
曠課�����、請(qǐng)假、遲到�����、早退�����;
課堂紀(jì)律���、上課說話、上課玩手機(jī)�、上課吃東西、上課看與學(xué)科內(nèi)容無關(guān)的書���、上課期間隨意進(jìn)出��、上課手機(jī)響鈴�、上課做其他科作業(yè)����、上課睡覺���、上課坐姿不端正;
課堂上搶答舉手�����、表達(dá)清楚性����、觀點(diǎn)清晰性、內(nèi)容正確性�;
小組討論時(shí)主題明確性、討論氣氛活躍性���、是否組織者�����、是否積極發(fā)言�;
實(shí)驗(yàn)前儀器樣品狀況確認(rèn)與否����、破損儀器數(shù)量、破損儀器時(shí)間�、儀器破損上報(bào)情況��、儀器賠償�����、儀器整理情況��、實(shí)驗(yàn)完成用時(shí)長(zhǎng)短、實(shí)驗(yàn)過程操作規(guī)范程度���、實(shí)驗(yàn)過程中的紀(jì)律遵守情況�����、實(shí)驗(yàn)后衛(wèi)生打掃情況����、原始實(shí)驗(yàn)數(shù)據(jù)準(zhǔn)確度�����、原始實(shí)驗(yàn)數(shù)據(jù)有無抄襲現(xiàn)象�����、實(shí)驗(yàn)報(bào)告的質(zhì)量;
預(yù)習(xí)�、作業(yè)的完成的時(shí)間點(diǎn),預(yù)習(xí)��、作業(yè)的完成的時(shí)間段�;
預(yù)習(xí)、作業(yè)的質(zhì)量����,預(yù)習(xí)、作業(yè)的次數(shù)��;
作業(yè)誠(chéng)信��、考試誠(chéng)信���;
測(cè)驗(yàn)����、考試成績(jī)���、考試用時(shí)���;
當(dāng)通過設(shè)備交互答題�����,使用鼠標(biāo)�、鍵盤���、體感設(shè)備��、觸摸屏���、模擬設(shè)備時(shí)����;
完成的時(shí)間點(diǎn)的早晚、完成的時(shí)間段的長(zhǎng)短��、操作的頻率的多少��、重復(fù)的頻率的多少�、設(shè)備位移的長(zhǎng)度長(zhǎng)短、設(shè)備位移的速度大小���、設(shè)備位移的精度大小����、操作的質(zhì)量高低;
當(dāng)通過設(shè)備交互答題��,使用語音輸入設(shè)備時(shí)�;
響度、音調(diào)�����、音品或音色�����、語速���。
步驟(S2)中的學(xué)習(xí)表現(xiàn)數(shù)據(jù)庫(kù)和性格特征數(shù)據(jù)庫(kù)具有學(xué)生通過性格測(cè)驗(yàn)所獲得的性格特征數(shù)據(jù)以及通過學(xué)習(xí)系統(tǒng)所獲得學(xué)習(xí)數(shù)據(jù)��,這些數(shù)據(jù)都是所獲得的原始數(shù)據(jù)���。其中,性格測(cè)驗(yàn)包含卡特爾16PF人格測(cè)驗(yàn)���、大五人格測(cè)驗(yàn)����,卡特爾16PF人格測(cè)驗(yàn)包含16個(gè)維度的性格特征,而大五人格測(cè)驗(yàn)包含五個(gè)維度的性格特征���。
步驟(S3)中建立學(xué)習(xí)者的學(xué)習(xí)表現(xiàn)數(shù)據(jù)模型和性格特征數(shù)據(jù)模型�����,主要是通過學(xué)習(xí)表現(xiàn)與性格特征的原始數(shù)據(jù)���,通過計(jì)算其中的相關(guān)系數(shù),輸出學(xué)習(xí)者的新的性格特征的穩(wěn)定模型���。
步驟(S4)中使用的數(shù)據(jù)數(shù)學(xué)算法為包含聚類分析算法(S41)、關(guān)聯(lián)規(guī)則法(S42)����、回歸分析法(S43)、BP神經(jīng)網(wǎng)絡(luò)模型(S44)����、決策樹(S45)、支持向量機(jī)(S46)的數(shù)據(jù)挖掘算法。
采用聚類分析算法(S41)將學(xué)習(xí)者的表現(xiàn)數(shù)據(jù)類型進(jìn)行相似性比較�,將比較相似的個(gè)體性格特征歸為同一組數(shù)據(jù)庫(kù),采用以下步驟:
(1)選取性格特征作為初始的聚類中心��;
(2)輸入學(xué)習(xí)者的學(xué)習(xí)表現(xiàn)數(shù)據(jù)和性格特征的測(cè)試結(jié)果��;
(3)計(jì)算學(xué)習(xí)表現(xiàn)數(shù)據(jù)類型與各個(gè)性格特征聚類中心之間的距離�,使誤差平方和局部最小,并將距離用統(tǒng)一量化的手段給出���,把學(xué)習(xí)表現(xiàn)數(shù)據(jù)類型與性格特征之間距離小于閾值的分配給相應(yīng)的性格特征聚類中心�����,得到的學(xué)習(xí)表現(xiàn)數(shù)據(jù)與性格特征之間的分配關(guān)系與距離�����;
(4)用新的數(shù)據(jù)重復(fù)(1)���、(2)、(3)的操作����,待相關(guān)系數(shù)穩(wěn)定后��,得到穩(wěn)定的數(shù)學(xué)模型���;
(5)然后將新的學(xué)習(xí)者的學(xué)習(xí)表現(xiàn)數(shù)據(jù)輸入到性格特征評(píng)估系統(tǒng),可得出新學(xué)習(xí)者的性格特征�。
采用關(guān)聯(lián)規(guī)則法(S42)將不同的性格特征關(guān)聯(lián)起來,當(dāng)個(gè)體表現(xiàn)出一種性格特征時(shí)�����,則可推斷其他性格特征�,其方法為:
補(bǔ)充用這種方法的核心步驟
采用回歸分析法(S43)建立數(shù)學(xué)模型,用最小二乘法估計(jì)確定同類型的學(xué)習(xí)表現(xiàn)數(shù)據(jù)與某些性格特征之間的定量關(guān)系式���,采用逐步回歸�����、向前回歸和向后回歸方法計(jì)算某個(gè)學(xué)習(xí)表現(xiàn)數(shù)據(jù)與某個(gè)性格特征的相關(guān)性參數(shù)來判斷某個(gè)學(xué)習(xí)表現(xiàn)數(shù)據(jù)與某個(gè)性格特征之間的影響是否顯著�����。
采用BP神經(jīng)網(wǎng)絡(luò)法(S44)對(duì)所有的學(xué)習(xí)表現(xiàn)數(shù)據(jù)與性格特征綜合分析,采用最速下降法�����,沿距離梯度下降的方向求解極小值,經(jīng)過不斷的迭代與修正得出所有的學(xué)習(xí)表現(xiàn)數(shù)據(jù)與性格特征之間存在的最短距離���,最端距離代表與學(xué)習(xí)表現(xiàn)數(shù)據(jù)相關(guān)的性格特征��。
采用決策樹(S45)法對(duì)學(xué)習(xí)表現(xiàn)數(shù)據(jù)分類����,將不同類型學(xué)習(xí)表現(xiàn)數(shù)據(jù)更清楚地表示出來���。
采用步驟(S4)中的支持向量機(jī)(S46)算法計(jì)算出某一性格特征與其相關(guān)的學(xué)習(xí)表現(xiàn)數(shù)據(jù)所產(chǎn)生的“最短距離方式”�����,經(jīng)過不斷的迭代運(yùn)算�����,得出性格特征相關(guān)性較強(qiáng)的學(xué)習(xí)表現(xiàn)數(shù)據(jù)��。
有益的效果是:
使用本方法�,性格特征評(píng)估系統(tǒng)可以使用新學(xué)習(xí)者的學(xué)習(xí)表現(xiàn)數(shù)據(jù)來評(píng)價(jià)其性格特征�����,從而對(duì)學(xué)生日后的發(fā)展進(jìn)行科學(xué)指導(dǎo),有利于教師把握學(xué)生的性格�。
方法包括以下步驟:S1:將個(gè)體表現(xiàn)數(shù)據(jù)輸入到數(shù)據(jù)庫(kù);S2:建立學(xué)習(xí)者的學(xué)習(xí)表現(xiàn)數(shù)據(jù)庫(kù)和性格特征數(shù)據(jù)庫(kù)��;S3:建立學(xué)習(xí)者的學(xué)習(xí)表現(xiàn)數(shù)據(jù)模型和性格特征數(shù)據(jù)模型��;S4:使用數(shù)據(jù)算法計(jì)算學(xué)習(xí)表現(xiàn)數(shù)據(jù)����;S5:輸出個(gè)體性格特征。
針對(duì)步驟S1��,步驟(S1)中的個(gè)體表現(xiàn)數(shù)據(jù)為諸如以下類型且不局限于以下類型的個(gè)體表現(xiàn):
曠課����、請(qǐng)假、遲到���、早退���;
課堂紀(jì)律、上課說話���、上課玩手機(jī)���、上課吃東西、上課看與學(xué)科內(nèi)容無關(guān)的書�����、上課期間隨意進(jìn)出�����、上課手機(jī)響鈴���、上課做其他科作業(yè)����、上課睡覺��、上課坐姿不端正���;
課堂上搶答舉手�����、表達(dá)清楚性����、觀點(diǎn)清晰性、內(nèi)容正確性�;
小組討論時(shí)主題明確性、討論氣氛活躍性���、是否組織者��、是否積極發(fā)言�����;
實(shí)驗(yàn)前儀器樣品狀況確認(rèn)與否����、破損儀器數(shù)量����、破損儀器時(shí)間、儀器破損上報(bào)情況�、儀器賠償、儀器整理情況、實(shí)驗(yàn)完成用時(shí)長(zhǎng)短��、實(shí)驗(yàn)過程操作規(guī)范程度��、實(shí)驗(yàn)過程中的紀(jì)律遵守情況�����、實(shí)驗(yàn)后衛(wèi)生打掃情況���、原始實(shí)驗(yàn)數(shù)據(jù)準(zhǔn)確度、原始實(shí)驗(yàn)數(shù)據(jù)有無抄襲現(xiàn)象���、實(shí)驗(yàn)報(bào)告的質(zhì)量��;
預(yù)習(xí)��、作業(yè)的完成的時(shí)間點(diǎn)�����,預(yù)習(xí)�����、作業(yè)的完成的時(shí)間段�����;
預(yù)習(xí)���、作業(yè)的質(zhì)量���,預(yù)習(xí)、作業(yè)的次數(shù)�;
作業(yè)誠(chéng)信、考試誠(chéng)信�����;
測(cè)驗(yàn)����、考試成績(jī)、考試用時(shí)�����;
當(dāng)通過設(shè)備交互答題�,使用鼠標(biāo)、鍵盤、體感設(shè)備�、觸摸屏、模擬設(shè)備時(shí)�;
完成的時(shí)間點(diǎn)的早晚、完成的時(shí)間段的長(zhǎng)短��、操作的頻率的多少����、重復(fù)的頻率的多少�����、設(shè)備位移的長(zhǎng)度長(zhǎng)短���、設(shè)備位移的速度大小�、設(shè)備位移的精度大小���、操作的質(zhì)量高低�����;
當(dāng)通過設(shè)備交互答題��,使用語音輸入設(shè)備時(shí)�;
響度、音調(diào)�����、音品或音色�����、語速����。
針對(duì)步驟S2,學(xué)習(xí)表現(xiàn)數(shù)據(jù)庫(kù)和性格特征數(shù)據(jù)庫(kù)的獲得可以通過以下方式實(shí)現(xiàn):在學(xué)習(xí)開始時(shí)����,先對(duì)學(xué)習(xí)者進(jìn)行常規(guī)的性格測(cè)驗(yàn),獲得學(xué)習(xí)者的性格特征���,并將其儲(chǔ)存進(jìn)入數(shù)據(jù)庫(kù)��,然后讓學(xué)習(xí)者使用學(xué)習(xí)系統(tǒng)�,產(chǎn)生學(xué)習(xí)表現(xiàn)數(shù)據(jù)�,也將其儲(chǔ)存進(jìn)入數(shù)據(jù)庫(kù)����,建立學(xué)習(xí)者的學(xué)習(xí)表現(xiàn)數(shù)據(jù)和性格特征數(shù)據(jù)庫(kù)��。其中����,性格測(cè)驗(yàn)包含卡特爾16PF人格測(cè)驗(yàn)、大五人格測(cè)驗(yàn)��,卡特爾16PF人格測(cè)驗(yàn)包含16個(gè)維度的性格特征����,分別是因素A-樂群性���、因素B-聰慧性�����、因素C-穩(wěn)定性��、因素E-恃強(qiáng)性����、因素F-興奮性、因素G-有恒性���、因素H-敢為性����、因素I-敏感性����、因素L-懷疑性、因素M-幻想性����、因素N-世故性、因素O-憂慮性����、因素Q1--實(shí)驗(yàn)性、因素Q2--獨(dú)立性����、因素Q3--自律性、因素Q4--緊張性�;而大五人格測(cè)驗(yàn)包含五個(gè)維度的性格特征,分別是外傾性����、神經(jīng)質(zhì)或情緒穩(wěn)定性�、開放性��、隨和性�����、盡責(zé)性�����。
針對(duì)步驟S3�����,建立學(xué)習(xí)者的學(xué)習(xí)表現(xiàn)數(shù)據(jù)模型和性格特征數(shù)據(jù)模型可以通過以下方式實(shí)現(xiàn):將學(xué)習(xí)者的學(xué)習(xí)表現(xiàn)數(shù)據(jù)與性格測(cè)評(píng)結(jié)果作為性格特征評(píng)估系統(tǒng)的訓(xùn)練集�����,性格特征評(píng)估系統(tǒng)使用訓(xùn)練集進(jìn)行學(xué)習(xí)��,調(diào)整各種類型的學(xué)習(xí)表現(xiàn)數(shù)據(jù)與不同類型的性格特征的相關(guān)系數(shù)�����,產(chǎn)生新的各種類型的學(xué)習(xí)表現(xiàn)數(shù)據(jù)與不同類型的性格特征的相關(guān)關(guān)系與相關(guān)系數(shù)�����,形成學(xué)習(xí)表現(xiàn)數(shù)據(jù)與性格特征相互關(guān)系的穩(wěn)定模型��,并將其儲(chǔ)存進(jìn)入數(shù)據(jù)庫(kù)���。當(dāng)相關(guān)系數(shù)穩(wěn)定后�����,性格特征評(píng)估系統(tǒng)根據(jù)新學(xué)習(xí)者的學(xué)習(xí)表現(xiàn)數(shù)據(jù)輸出新學(xué)習(xí)者的性格特征�����。
針對(duì)步驟S4���,的數(shù)據(jù)數(shù)學(xué)算法為包含聚類分析算法S41、關(guān)聯(lián)規(guī)則法S42��、回歸分析法S43���、BP神經(jīng)網(wǎng)絡(luò)模型S44����、支持向量機(jī)S46的數(shù)據(jù)挖掘算法,實(shí)施步驟可以通過以下方式實(shí)現(xiàn):
針對(duì)步驟S41���,在進(jìn)行聚類分析算法運(yùn)算時(shí)����,聚類分析算法將學(xué)習(xí)者的表現(xiàn)數(shù)據(jù)類型進(jìn)行相似性比較��,將比較相似的個(gè)體性格特征歸為同一組數(shù)據(jù)庫(kù)�,采用以下步驟:
(1)選取性格特征作為初始的聚類中心;
(2)輸入學(xué)習(xí)者的學(xué)習(xí)表現(xiàn)數(shù)據(jù)和性格特征的測(cè)試結(jié)果�;
(3)計(jì)算學(xué)習(xí)表現(xiàn)數(shù)據(jù)類型與各個(gè)性格特征聚類中心之間的距離,使誤差平方和局部最小���,并將距離用統(tǒng)一量化的手段給出�,把學(xué)習(xí)表現(xiàn)數(shù)據(jù)類型與性格特征之間距離小于閾值的分配給相應(yīng)的性格特征聚類中心��,得到的學(xué)習(xí)表現(xiàn)數(shù)據(jù)與性格特征之間的分配關(guān)系與距離���;
(4)用新的數(shù)據(jù)重復(fù)(1)、(2)�、(3)的操作�,待相關(guān)系數(shù)穩(wěn)定后���,得到穩(wěn)定的數(shù)學(xué)模型��;
(5)然后將新的學(xué)習(xí)者的學(xué)習(xí)表現(xiàn)數(shù)據(jù)輸入到性格特征評(píng)估系統(tǒng)��,可得出新學(xué)習(xí)者的性格特征�。
比如:首先計(jì)算學(xué)習(xí)表現(xiàn)數(shù)據(jù)中遲到的次數(shù)�����,早退的次數(shù)�,破損儀器數(shù)量多少等與各類性格特征之間的距離,其中對(duì)于“敢為性”這種性格來說只有遲到的次數(shù)�����,早退的次數(shù)����,損儀器數(shù)量多少,作業(yè)誠(chéng)信度����,上課玩手機(jī)���,上課睡覺,儀器賠償及時(shí)與否之間的距離小于閾值����,所以認(rèn)定“敢為性”只與這些學(xué)習(xí)表現(xiàn)數(shù)據(jù)存在相關(guān)性關(guān)聯(lián),并且根據(jù)算出的距離按照比例得到對(duì)于“敢為性”遲到次數(shù)占25%��,早退的次數(shù)占20%���,作業(yè)誠(chéng)信度占5%�,上課玩手機(jī)占8%��,損壞儀器數(shù)量多少占13%��,儀器賠償及時(shí)與否占15%�����,上課睡覺12%��,其余學(xué)習(xí)表現(xiàn)數(shù)據(jù)均小于2%的閾值��,所以不作為考慮因素。
同理���,對(duì)于遲到的次數(shù)這一學(xué)習(xí)表現(xiàn)數(shù)據(jù),計(jì)算其與各類性格特征之間的距離��,其中對(duì)于遲到次數(shù)這一學(xué)習(xí)表現(xiàn)數(shù)據(jù)來說��,只有敢為性���,恃強(qiáng)性�,穩(wěn)定性�,有恒性,實(shí)驗(yàn)性�����,自律性之間的距離小于閾值����,所以認(rèn)為遲到次數(shù)只與這些性格特征有關(guān),并且根據(jù)算出的距離按照比例得到對(duì)于遲到次數(shù)這一學(xué)習(xí)表現(xiàn)數(shù)據(jù)得到敢為性占35%����,恃強(qiáng)性占25%,穩(wěn)定性占15%,有恒性8%��,實(shí)驗(yàn)性占5%��,自律性6%����,其余性格特征均小于2%的閾值,所以不作為考慮因素����。
以此為例可以找到任意一個(gè)學(xué)習(xí)表現(xiàn)數(shù)據(jù)與其余性格特征之間的相關(guān)性關(guān)系,也可以找到任意一個(gè)性格特征與其余學(xué)習(xí)表現(xiàn)數(shù)據(jù)之間的相關(guān)性關(guān)系�。
針對(duì)步驟S42,可以通過以下方式實(shí)現(xiàn):關(guān)聯(lián)規(guī)則法將不同的性格特征關(guān)聯(lián)起來���,當(dāng)個(gè)體表現(xiàn)出一種性格特征時(shí)���,則可推斷其他性格特征,關(guān)聯(lián)規(guī)則法數(shù)據(jù)之間的簡(jiǎn)單的聯(lián)系規(guī)則��,是指數(shù)據(jù)之間的相互依賴關(guān)系�����,比如性格特征敢為性與遲到的次數(shù),早退的次數(shù)���,損儀器數(shù)量多少�����,作業(yè)誠(chéng)信度,上課玩手機(jī)���,上課睡覺�,儀器賠償及時(shí)與否這些學(xué)習(xí)表現(xiàn)數(shù)據(jù)有著很強(qiáng)的關(guān)聯(lián)特征����,也就是當(dāng)這些學(xué)習(xí)表現(xiàn)數(shù)據(jù)有著很高的特點(diǎn)是,則被測(cè)者是有著敢為性的性格特征的��。對(duì)于遲到的次數(shù)這一學(xué)習(xí)表現(xiàn)數(shù)據(jù)�����,與其相關(guān)聯(lián)的性格特征為敢為性�����,恃強(qiáng)性,穩(wěn)定性��,有恒性����,實(shí)驗(yàn)性,自律性�����。當(dāng)被測(cè)者遲到次數(shù)較多時(shí)����,我們認(rèn)為他的性格特征與敢為性,恃強(qiáng)性��,穩(wěn)定性��,有恒性�,實(shí)驗(yàn)性,自律性有關(guān)�。
補(bǔ)充用這種方法的核心步驟
針對(duì)步驟S43,可以通過以下方式實(shí)現(xiàn)����,首先數(shù)學(xué)模型�,用最小二乘法估計(jì)確定同類型的學(xué)習(xí)表現(xiàn)數(shù)據(jù)與某些性格特征之間的定量關(guān)系式���,采用逐步回歸�����、向前回歸和向后回歸方法計(jì)算某個(gè)學(xué)習(xí)表現(xiàn)數(shù)據(jù)與某個(gè)性格特征的相關(guān)性參數(shù)來判斷某個(gè)學(xué)習(xí)表現(xiàn)數(shù)據(jù)與某個(gè)性格特征之間的影響是否顯著�����。具體地來說,利用一組同類型學(xué)習(xí)表現(xiàn)數(shù)據(jù)��,確定其與某些性格特征之間的定量關(guān)系式�����,即建立數(shù)學(xué)模型用最小二乘法估計(jì)其中的相關(guān)性參數(shù)�;在許多學(xué)習(xí)表現(xiàn)數(shù)據(jù)共同影響著一個(gè)性格特征的關(guān)系中,用逐步回歸��、向前回歸和向后回歸方法判斷哪個(gè)(或哪些)學(xué)習(xí)表現(xiàn)數(shù)據(jù)的影響是顯著的����,哪些學(xué)習(xí)表現(xiàn)數(shù)據(jù)的影響是不顯著的����,將影響顯著的學(xué)習(xí)表現(xiàn)數(shù)據(jù)帶入模型中��,而剔除影響不顯著的變量��;用新的數(shù)據(jù)對(duì)這些關(guān)系式的可信程度進(jìn)行檢驗(yàn)�,檢驗(yàn)結(jié)果在誤差允許范圍內(nèi)即可利用所求的關(guān)系式對(duì)新的學(xué)習(xí)表現(xiàn)數(shù)據(jù)得到的性格特征進(jìn)行預(yù)測(cè)或控制。
比如:對(duì)于無故曠課����,多次請(qǐng)假,遲到���,早退����,上課說話���,上課玩手機(jī)��,上課吃東西��,上課看與學(xué)科內(nèi)容無關(guān)的書��,上課睡覺����,上課坐姿不端正,預(yù)習(xí)答題狀況是否良好��,答題用時(shí)長(zhǎng)短�,預(yù)習(xí)答題時(shí)間的早晚,實(shí)驗(yàn)前儀器樣品狀況確認(rèn)與否���,破損儀器數(shù)量多少��,破損儀器時(shí)間����,儀器破損上報(bào)情況��,儀器賠償及時(shí)與否�,儀器歸放情況����,實(shí)驗(yàn)完成用時(shí)長(zhǎng)短,實(shí)驗(yàn)過程操作規(guī)范程度�����,實(shí)驗(yàn)過程中的紀(jì)律遵守情況,試驗(yàn)后衛(wèi)生打掃情況���,原始實(shí)驗(yàn)數(shù)據(jù)準(zhǔn)確度�,原始實(shí)驗(yàn)數(shù)據(jù)有無抄襲現(xiàn)象�����,實(shí)驗(yàn)報(bào)告的質(zhì)量高低���,作業(yè)成績(jī)�,作業(yè)用時(shí)���,上交時(shí)間����,上交次數(shù)���,作業(yè)誠(chéng)信����,考試成績(jī),考試用時(shí)�,考試誠(chéng)信等學(xué)習(xí)表現(xiàn)數(shù)據(jù),這些共同影響著敢為性這一性格特征�����,將這些數(shù)據(jù)用逐步回歸����、向前回歸和向后回歸方法計(jì)算這些學(xué)習(xí)表現(xiàn)數(shù)據(jù)與敢為性這一性格特征的相關(guān)性參數(shù),從而判斷這些學(xué)習(xí)表現(xiàn)數(shù)據(jù)與敢為性這一性格特征之間的影響是否顯著��,經(jīng)計(jì)算相關(guān)性參數(shù)�����,發(fā)現(xiàn)只有遲到的次數(shù)�����,早退的次數(shù)����,損儀器數(shù)量多少,作業(yè)誠(chéng)信度�,上課玩手機(jī),上課睡覺�����,儀器賠償及時(shí)與否存在明顯的相關(guān)關(guān)系�����,其余學(xué)習(xí)表現(xiàn)數(shù)據(jù)并未有顯著相關(guān)關(guān)系�,所以僅考慮遲到的次數(shù),早退的次數(shù)����,損儀器數(shù)量多少,作業(yè)誠(chéng)信度�����,上課玩手機(jī)��,上課睡覺�,儀器賠償及時(shí)與否與敢為性這一性格特征之間的相關(guān)性。同理���,我們可以做出任意一個(gè)性格特征所對(duì)應(yīng)的與其顯著的學(xué)習(xí)表現(xiàn)數(shù)據(jù)���。
針對(duì)步驟S44�����,BP神經(jīng)網(wǎng)絡(luò)法對(duì)所有的學(xué)習(xí)表現(xiàn)數(shù)據(jù)與性格特征綜合分析��,采用最速下降法����,沿距離梯度下降的方向求解極小值,經(jīng)過不斷的迭代與修正得出所有的學(xué)習(xí)表現(xiàn)數(shù)據(jù)與性格特征之間存在的最短距離�,最端距離代表與學(xué)習(xí)表現(xiàn)數(shù)據(jù)相關(guān)的性格特征�����。具體地來說�����,將所有的學(xué)習(xí)表現(xiàn)數(shù)據(jù)與性格特征綜合分析,由之前算法可以得到所有的數(shù)據(jù)與特征之間存在的距離���,并且相關(guān)性越近,距離越短����,所以在綜合分析時(shí)���,我們采用最速下降法���,沿距離梯度下降的方向求解極小值�,經(jīng)過不斷的迭代與修正得到對(duì)于某一性格特征與其相關(guān)的學(xué)習(xí)表現(xiàn)數(shù)據(jù)所產(chǎn)生的“最短距離方式”�����,也可以求出對(duì)與某一學(xué)習(xí)表現(xiàn)數(shù)據(jù)與其對(duì)應(yīng)的性格特征產(chǎn)生的“最短距離方式”����,比如對(duì)于敢為性��,所產(chǎn)生的最短距離代表的學(xué)習(xí)表現(xiàn)數(shù)據(jù)為遲到的次數(shù)�����,早退的次數(shù),損儀器數(shù)量多少����,作業(yè)誠(chéng)信度�,上課玩手機(jī),上課睡覺���,儀器賠償及時(shí)與否。對(duì)于遲到的次數(shù)這一學(xué)習(xí)表現(xiàn)數(shù)據(jù),所產(chǎn)生的最短距離代表的性格特征為敢為性,恃強(qiáng)性�,穩(wěn)定性�����,有恒性,實(shí)驗(yàn)性�����,自律性。
針對(duì)步驟S45�����,可以通過以下方式實(shí)現(xiàn)�����,比如�,我們已經(jīng)得到各個(gè)學(xué)習(xí)表現(xiàn)數(shù)據(jù)與性格特征之間的概率,判斷取哪些學(xué)習(xí)表現(xiàn)數(shù)據(jù)與其中某一個(gè)性格特征合適�。我們想得到獨(dú)立性相關(guān)的學(xué)習(xí)表現(xiàn)數(shù)據(jù)����,則獨(dú)立性為決策點(diǎn)�,這些學(xué)習(xí)表現(xiàn)數(shù)據(jù)為狀態(tài)節(jié)點(diǎn),并標(biāo)明每一數(shù)據(jù)特征與其之間的概率�,用遞歸式對(duì)數(shù)進(jìn)行修剪,得到最優(yōu)的路徑�����。我們得到與獨(dú)立性相關(guān)的學(xué)習(xí)表現(xiàn)數(shù)據(jù)為早退�����,上課看與學(xué)科內(nèi)容無關(guān)的書�����,上課睡覺,上課坐姿不端正,預(yù)習(xí)答題時(shí)間的早晚,儀器歸放情況��,實(shí)驗(yàn)過程操作規(guī)范程度這些學(xué)習(xí)表現(xiàn)數(shù)據(jù)有著最優(yōu)的關(guān)系,其將學(xué)習(xí)表現(xiàn)數(shù)據(jù)分類����,將不同類型學(xué)習(xí)表現(xiàn)數(shù)據(jù)更清楚地表示出來�����。
比如這樣的:
針對(duì)步驟S46����,可以通過以下方式實(shí)現(xiàn)��,其能夠建立起與相關(guān)的學(xué)習(xí)算法有關(guān)的監(jiān)督學(xué)習(xí)模型���,可以根據(jù)有限的樣本信息在模型的復(fù)雜性(即對(duì)特定訓(xùn)練樣本的學(xué)習(xí)精度)和學(xué)習(xí)能力(即無錯(cuò)誤地識(shí)別任意樣本的能力)之間尋求最佳折中����,以求獲得最好的推廣能力���。比如:我們有很多學(xué)習(xí)表現(xiàn)數(shù)據(jù)����,以及提煉出的性格特征����,確定他們之間的映射關(guān)系��,與神經(jīng)網(wǎng)絡(luò)類似�,計(jì)算某一性格特征與其相關(guān)的學(xué)習(xí)表現(xiàn)數(shù)據(jù)所產(chǎn)生的“最短距離方式”�����,經(jīng)過不斷的迭代運(yùn)算����,最終得到比如對(duì)于獨(dú)立性這一性格特征來說,與其相關(guān)性較強(qiáng)的學(xué)習(xí)表現(xiàn)數(shù)據(jù)為早退�����,上課看與學(xué)科內(nèi)容無關(guān)的書�,上課睡覺,上課坐姿不端正�����,預(yù)習(xí)答題時(shí)間的早晚�����,儀器歸放情況��,實(shí)驗(yàn)過程操作規(guī)范程度�。
二、非負(fù)矩陣分解
把一個(gè)學(xué)期10名同學(xué)的請(qǐng)假��、曠課����、遲到、上課說話和上課睡覺的數(shù)據(jù)匯總為一個(gè)訓(xùn)練集��,統(tǒng)計(jì)數(shù)據(jù)如表1所示:
表1訓(xùn)練集
問題描述:就是建立100個(gè)不同類型的定量參數(shù)和10個(gè)另外類型的定量參數(shù)的相關(guān)關(guān)系和強(qiáng)度�����。那100個(gè)參數(shù)之間和那10個(gè)參數(shù)是多對(duì)多關(guān)系��。但是不知道具體的相關(guān)關(guān)系和強(qiáng)度�����。有數(shù)據(jù)集用來學(xué)習(xí)和驗(yàn)證��,相關(guān)關(guān)系和強(qiáng)度穩(wěn)定后進(jìn)行應(yīng)用��。
前五列數(shù)據(jù)屬于100個(gè)不同類型的定量參數(shù)����,后四列數(shù)據(jù)屬于10個(gè)另外類型的定量參數(shù)�����,找前五列數(shù)據(jù)和后四列數(shù)據(jù)的相關(guān)關(guān)系和強(qiáng)度�����。
要求:進(jìn)行一個(gè)聚類分析。只需要寫清過程,不需要具體計(jì)算。
問題分析:根據(jù)問題描述���,可以使用非負(fù)矩陣分解算法來解決這個(gè)問題。
具體分析過程:
1.非負(fù)矩陣分解算法發(fā)展歷史
它是一種新的矩陣分解算法�����,最早是1994年由Paatero和Tapper等人提出的,當(dāng)時(shí)這個(gè)算法叫正矩陣分解,直到1999年, Lee和Seung在Nature上發(fā)表了他們對(duì)矩陣分解的研究���,才逐漸引起廣大研究學(xué)者的興趣,發(fā)展到現(xiàn)在,矩陣分解方法已經(jīng)應(yīng)用到很多領(lǐng)域。
2.矩陣分解理論
假定給定一個(gè)原數(shù)據(jù),用非負(fù)的數(shù)據(jù)矩陣(差異矩陣)進(jìn)行表示,將其分解為兩個(gè)非負(fù)矩陣(基矩陣)和(系數(shù)矩陣)的乘積,并且乘積要盡可能的逼近原來的矩陣,即(k << m, n)���。非負(fù)矩陣分解模型可以表示為以下的優(yōu)化問題:
需要使用一下迭代公式來求得W和H
3.非負(fù)矩陣分解算法應(yīng)用到以上問題中
(1)首先是原始矩陣的構(gòu)造:在這個(gè)問題中�����,我們構(gòu)建矩陣數(shù)據(jù)矩陣(屬性-對(duì)象矩陣)�����,10行5列的數(shù)據(jù)矩陣。如下所示:
其中����,一行代表一名學(xué)生(對(duì)象)���,一列代表一個(gè)屬性(是否請(qǐng)假、無故曠課、遲到、上課說話��、上課睡覺)���。
(2)對(duì)這個(gè)矩陣進(jìn)行矩陣分解,其中k值選擇為4�,W和H用隨機(jī)初始化,其中每個(gè)值都在0-1之間��。W和H按照上面的迭代公式進(jìn)行求解�����,迭代次數(shù)設(shè)置為1000���。
(3)矩陣分解之后��,用矩陣W和H進(jìn)行聚類分析���。
迭代1000次之后�,得到基矩陣和系數(shù)矩陣
基矩陣:
由系數(shù)矩陣可得到前五列和后四列關(guān)系���,權(quán)重可以看作是強(qiáng)度。
三����、來源于創(chuàng)青春比賽
1、apriori關(guān)聯(lián):
>library(arules)
>xingge=read.csv("guanlian.csv",header=T)
#值得注意的是�,"guanlian.csv"從一個(gè)數(shù)值矩陣轉(zhuǎn) #換為0-1矩陣,再?gòu)?-1矩陣轉(zhuǎn)為邏輯型矩陣���,即 #0:FALSE����,1:TRUE�。
[1]"QJ" "KK" "CD" "SH" "SJ""Q1"
>data(list=xingge)
Therewere 30 warnings (use warnings() to see them)
>mode(xingge)
[1]"list"
>rules=apriori(xingge,parameter=list(support=0.3,confidence=0.4))
Apriori
Parameterspecification:
confidence minval smax aremaval originalSupport maxtime support minlen
0.40.11 none FALSETRUE50.31
maxlen targetext
10rules FALSE
Algorithmiccontrol:
filter tree heap memopt load sort verbose
0.1 TRUE TRUEFALSE TRUE2TRUE
Absoluteminimum support count: 3
set itemappearances ...[0 item(s)] done [0.00s].
settransactions ...[9 item(s), 10 transaction(s)] done [0.00s].
sortingand recoding items ... [9 item(s)] done [0.00s].
creatingtransaction tree ... done [0.00s].
checkingsubsets of size 1 2 3 4 5 6 done [0.00s].
writing... [320 rule(s)] done [0.00s].
creatingS4 object... done [0.00s].
>summary(rules)
set of320 rules
rulelength distribution (lhs + rhs):sizes
123456
748108 106456
Min. 1st Qu.MedianMean 3rd Qu.Max.
1.0003.0003.0003.4754.0006.000
summaryof quality measures:
supportconfidencelift
Min.:0.3000Min.:0.4000Min.:0.8163
1st Qu.:0.30001st Qu.:0.69171st Qu.:1.0000
Median :0.4000Median :1.0000Median :1.0000
Mean:0.4363Mean:0.8366Mean:1.0489
3rd Qu.:0.50003rd Qu.:1.00003rd Qu.:1.0179
Max.:1.0000Max.:1.0000Max.:1.4286
mininginfo:
data ntransactions support confidence
xingge100.30.4
>frequentsets=eclat(xingge,parameter=list(support=0.3,maxlen=10))
Eclat
parameterspecification:
tidLists support minlen maxlentargetext
FALSE0.3110 frequent itemsets FALSE
algorithmiccontrol:
sparse sort verbose
7-2TRUE
Absoluteminimum support count: 3
createitemset ...
settransactions ...[9 item(s), 10 transaction(s)] done [0.00s].
sortingand recoding items ... [9 item(s)] done [0.00s].
creatingbit matrix ... [9 row(s), 10 column(s)] done [0.00s].
writing... [111 set(s)] done [0.00s].
CreatingS4 object... done [0.00s].
>inspect(frequentsets[1:10])
itemssupport
[1]{QJ=TURE,KK=TURE,CD=TURE,SH=TURE,Q1=TURE} 0.3
[2]{QJ=TURE,KK=TURE,SH=TURE,Q1=TURE}0.3
[3]{KK=TURE,CD=TURE,SH=TURE,Q1=TURE}0.3
[4]{QJ=TURE,KK=TURE,CD=TURE,Q1=TURE}0.3
[5]{QJ=TURE,KK=TURE,Q1=TURE}0.3
[6]{KK=TURE,CD=TURE,Q1=TURE}0.3
[7]{KK=TURE,SH=TURE,Q1=TURE}0.3
[8]{QJ=TURE,CD=TURE,SH=TURE,Q1=TURE}0.3
[9]{QJ=TURE,SH=TURE,Q1=TURE}0.3
[10] {CD=TURE,SH=TURE,Q1=TURE}0.3
2����、Bayes
>data<-matrix(c("A1","B2","B3","B4","B5","no",
+"B1","A2","B3","B4","B5","no",
+"B1","B2","B3","B4","A5","no",
+"B1","B2","B3","A4","B5","no"),byrow=TRUE,
+nrow=4,ncol=6)
> data
[,1] [,2] [,3] [,4] [,5][,6]
[1,] "A1" "B2" "B3" "B4""B5" "no"
[2,] "B1" "A2" "B3" "B4""B5" "no"
[3,] "B1" "B2" "B3" "B4""A5" "no"
[4,] "B1" "B2" "B3" "A4""B5" "no"
> library("e1071")
> library("foreign")
>prior.yes=sum(data[,6]=="yes")/length(data[,6])
> prior.yes
[1] 0
>prior.no=sum(data[,6]=="no")/length(data[,6])
> prior.no
[1] 1
(第一種函數(shù))
> naive.bayes.prediction<-function(condition.vec){
+G.yes<-sum((data[,1]==condition.vec[1])&(data[,5]=="yes"))/sum(data[,5]=="yes")*
+sum((data[,1]==condition.vec[2])&(data[,5]=="yes"))/sum(data[,5]=="yes")*
+sum((data[,1]==condition.vec[3])&(data[,5]=="yes"))/sum(data[,5]=="yes")*
+sum((data[,1]==condition.vec[4])&(data[,5]=="yes"))/sum(data[,5]=="yes")*
+sum((data[,1]==condition.vec[5])&(data[,5]=="yes"))/sum(data[,5]=="yes")*
+prior.yes
+G.no<-sum((data[,1]==condition.vec[1])&(data[,5]=="no"))/sum(data[,5]=="no")*
+sum((data[,1]==condition.vec[2])&(data[,5]=="no"))/sum(data[,5]=="no")*
+sum((data[,1]==condition.vec[3])&(data[,5]=="no"))/sum(data[,5]=="no")*
+sum((data[,1]==condition.vec[4])&(data[,5]=="no"))/sum(data[,5]=="no")*
+sum((data[,1]==condition.vec[5])&(data[,5]=="no"))/sum(data[,5]=="no")*
+prior.no
+return(list(post.pr.yes=G.yes,post.pr.no=G.no,prediction=ifelse(G.yes>=G.yes,"yes","no")))
+}
>naive.bayes.prediction(c("A1","B2","B3","B4","B5"))
$post.pr.yes
[1] NaN
$post.pr.no
[1] NaN
$prediction
[1] NA
>naive.bayes.prediction(c("A1","A2","A3","A4","A5"))
$post.pr.yes
[1] NaN
$post.pr.no
[1] NaN
$prediction
[1] NA
(第二種函數(shù))
>naive.bayes.prediction<-function(condition.vec){
+ + +G.yes<-sum((data[,1]=="A1")&(data[,5]=="yes"))/sum(data[,5]=="yes")*
+ + +sum((data[,1]=="A2")&(data[,5]=="yes"))/sum(data[,5]=="yes")*
+ + +sum((data[,1]=="A3")&(data[,5]=="yes"))/sum(data[,5]=="yes")*
+ + +sum((data[,1]=="A4")&(data[,5]=="yes"))/sum(data[,5]=="yes")*
+ + +sum((data[,1]=="A5")&(data[,5]=="yes"))/sum(data[,5]=="yes")*
+ + +prior.yes
+ + +G.no<-sum((data[,1]=="B1")&(data[,5]=="no"))/sum(data[,5]=="no")*
+ + +sum((data[,1]=="B2")&(data[,5]=="no"))/sum(data[,5]=="no")*
+ + +sum((data[,1]=="B3")&(data[,5]=="no"))/sum(data[,5]=="no")*
+ + +sum((data[,1]=="B4")&(data[,5]=="no"))/sum(data[,5]=="no")*
+ + +sum((data[,1]=="B5")&(data[,5]=="no"))/sum(data[,5]=="no")*
+ + +prior.no
+ + +return(list(post.pr.yes=G.yes,post.pr.no=G.no,prediction=ifelse(G.yes>=G.yes,"yes","no")))
+}
>naive.bayes.prediction(c("A1","A2","A3","A4","A5"))
Error in ++G.yes <- sum((data[, 1] == "A1") &(data[, 5] == "yes"))/sum(data[,:
找不到對(duì)象'G.yes'
>naive.bayes.prediction(c("A1","B2","B3","B4","B5"))
Error in ++G.yes <- sum((data[, 1] == "A1") &(data[, 5] == "yes"))/sum(data[,:
找不到對(duì)象'G.yes'
3、K-means:
> data(iris)
> head(iris,n=6)
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
15.13.51.40.2setosa
24.93.01.40.2setosa
34.73.21.30.2setosa
44.63.11.50.2setosa
55.03.61.40.2setosa
65.43.91.70.4setosa
> install.packages("fpc")
> library(fpc)#估計(jì)輪廓系數(shù)
>norm<-function(x){(x-mean(x))/(sqry(var(x)))}
>norm<-function(x){(x-mean(x))/(sqrt(var(x)))}
> raw.data<-iris[,1:4]
>norm.data<-data.frame(sl=norm(raw.data[,1]),sw=(raw.data[,2]),pl=(raw.data[,3]),pw=(raw.data[,4]))
>k<-2:10
> round<-40
> rst<-sapply(k,function(i)#輪廓系數(shù)
+ {
+ print(paste("k=",i))
+ mean(sapply(1:round,function(r){
+ print(paste("Round",r))
+ result<-kmeans(norm.data,i)
+stats<-cluster.stats(dist(norm.data),result$cluster)
+ stats$avg.silwidth
+ }))
+ })
[1] "k= 2"
[1] "Round 1"
[1] "Round 2"
[1] "Round 3"
[1] "Round 4"
[1] "Round 5"
[1] "Round 6"
[1] "Round 7"
[1] "Round 8"
[1] "Round 9"
[1] "Round 10"
[1] "Round 11"
[1] "Round 12"
[1] "Round 13"
[1] "Round 14"
[1] "Round 15"
[1] "Round 16"
[1] "Round 17"
[1] "Round 18"
[1] "Round 19"
[1] "Round 20"
[1] "Round 21"
[1] "Round 22"
[1] "Round 23"
[1] "Round 24"
[1] "Round 25"
[1] "Round 26"
[1] "Round 27"
[1] "Round 28"
[1] "Round 29"
[1] "Round 30"
[1] "Round 31"
…….
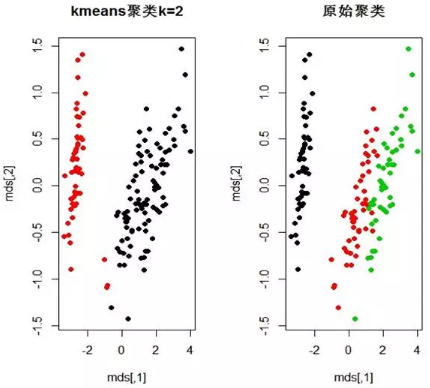
> plot(k,rst,type='l',main='輪廓系數(shù)與k的關(guān)系'����,ylab='輪廓系數(shù)')
> plot(k,rst)
> old.par<-par(mfrow=c(1,2))
> k=2
> clu<-kmeans(norm.data,k)
>mds=cmdscale(dist(norm.data,method="euclidean"))
> plot(mds,col=clu$cluster,main='kmeans聚類k=2',pch=19)
> plot(mds,col=iris$Species,main='原始聚類',pch=19)
> par(old.par)
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試��,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情;
? 想學(xué)習(xí)CDA考試教材����,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫(kù)�����,點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情���;
? 想了解CDA考試含金量,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330