簡(jiǎn)單的認(rèn)識(shí)一下組合分類器以及R語言對(duì)應(yīng)使用函數(shù)
首先���,我們大家都有學(xué)習(xí)過一系列的分類方法,例如決策樹�,貝葉斯分類器等,有時(shí)候分類的效果不太如人意���,哪怕是參數(shù)是最優(yōu)化也一樣,所以這時(shí)候就需要一些提高分類準(zhǔn)確性的方法�����,我們常用的就是組合分類器��,它就是一個(gè)復(fù)合模型�����,也就是由多個(gè)分類器組合而成;個(gè)體的分類器對(duì)結(jié)果進(jìn)行投票��,然后對(duì)組合分類器返回的投票進(jìn)行匯總�����,然后基于返回的結(jié)果進(jìn)行預(yù)測(cè)和分類����。組合分類器的結(jié)果往往比它的成員分類器更準(zhǔn)確;一般常用的組合分類方法有bigbing,boosting,還有我比較喜歡的隨機(jī)森林���; 什么是組合分類�����?
組合分類就是把K個(gè)學(xué)習(xí)得到的模型M1�����,M2���,...,MK組合在一起�����,使用給定數(shù)據(jù)集D創(chuàng)建K個(gè)訓(xùn)練集D1�����,D2�����,...,DK�����,其中D1用于創(chuàng)建M1模型���,以此類推;給定一個(gè)待分類的新數(shù)據(jù)元組�����,每個(gè)基分類器通過返回類預(yù)測(cè)投票����,它收集由基于基分類器返回的類標(biāo)預(yù)測(cè),并輸出占多數(shù)的類���,基分類器也會(huì)出錯(cuò)���,當(dāng)基分類器出錯(cuò)時(shí)不代表組合分類器出錯(cuò),組合分類器基于基本分類器的投票返回類預(yù)測(cè)���,因此基分類器要出錯(cuò)超過一半時(shí)組合分類器才會(huì)出錯(cuò)���,并且基分類器之間是不相關(guān)的,這也就是說明組合分類器更加準(zhǔn)確�。
bagging
這個(gè)方法也叫裝袋法,這個(gè)也是組合分類器的一種�����,它的理念在與通過自舉的方法建立很多不同的模型����,然后對(duì)結(jié)果取平均,其本質(zhì)是使得一些較弱的模型形成一個(gè)群體對(duì)結(jié)果來投票���,從而得到更精確的預(yù)測(cè)��;例如��,如果你是一名病人希望根據(jù)你的癥狀做出診斷�,你可能選擇多個(gè)醫(yī)生,而不是一個(gè)�����,如果某個(gè)診斷結(jié)果比其他診斷結(jié)果出現(xiàn)的次數(shù)多�,你可能認(rèn)為這個(gè)結(jié)果是最為可能出現(xiàn)的診斷結(jié)果,也即是說最終的診斷結(jié)果是根據(jù)多數(shù)表決做出的��;其中每個(gè)醫(yī)生的權(quán)重都一樣�,更多的醫(yī)生表決比少數(shù)醫(yī)生的多數(shù)表決更為的可靠;
在給定D個(gè)元組的集合��,采用有放回抽樣���,每個(gè)訓(xùn)練集都是一個(gè)自助樣本���,每個(gè)訓(xùn)練集通過學(xué)習(xí)得到一個(gè)分類模型,對(duì)未知的元組進(jìn)行分類�,每個(gè)分類器M返回它的分類結(jié)果,算做一票��,最后得票最高的作為結(jié)果類�����;對(duì)連續(xù)變量則通過取平均值���;
那么在R語言里面怎么使用這個(gè)方法呢�?
這時(shí)候我先要裝好包ipred包中的bagging函數(shù)建立回歸的bagging模型���;
例如
bagging(price~x1+x2,data=test_date,nbagg=20)#這里只是舉例代碼并不能執(zhí)行�;
nbagg時(shí)選擇多少個(gè)rpart數(shù)
boosting
這個(gè)方法也叫提升����,它和上面的方法有些類似,假如你是一位病人��,你選擇咨詢多位醫(yī)生�,然而得到的結(jié)果不是一致的,這時(shí)候你就需要根據(jù)先前醫(yī)生診斷的準(zhǔn)確率���。對(duì)每一位醫(yī)生賦予一個(gè)權(quán)重�����,然后根據(jù)加權(quán)診斷的組合作為最終的結(jié)果�;這就是提升的基本思想;
早提升方法中���,首先權(quán)重賦予每個(gè)訓(xùn)練元組���,迭代的學(xué)習(xí)K個(gè)分類器;學(xué)習(xí)得到分類器M1之后��,更新權(quán)重����,使得其后的分類器M2更關(guān)注誤分類的訓(xùn)練元組,如元組不準(zhǔn)確的分類���,則它的權(quán)重增加���,如果元組正確分類,則它的權(quán)重減少��;這是希望我們能夠更加關(guān)注上一輪誤分類的元組���;其中每個(gè)分類器投票的權(quán)重是其準(zhǔn)確率的函數(shù)���;
bagging和boosting相比
由于boosting更加的關(guān)注誤分的元組,所以存在結(jié)果符合模型的過度擬合的危險(xiǎn)��,bagging則不太受這個(gè)影響����,不過二者都能夠顯著的提高準(zhǔn)確度;boosting往往能夠得到較高的準(zhǔn)確率����;
R語言里使用的是包mboost中的blackboost函數(shù)從回歸樹種建立boosting模型,glmboost從廣義線性模型中建立模型��;
blackboost(price~x1+x2,data=test_date)#這里只是舉例代碼并不能執(zhí)行�;
隨機(jī)森林
隨機(jī)森林也是一種組合分類器,因?yàn)槊恳粋€(gè)分類器都是一棵樹���,所以組合在一起就很像一個(gè)森林�����;每一個(gè)數(shù)都依賴獨(dú)立抽樣����;
隨機(jī)森林可以使用bagging和隨機(jī)屬性來選擇組合來構(gòu)建,
A��、指定M值�����,即隨機(jī)產(chǎn)生M個(gè)屬性用于節(jié)點(diǎn)上的二叉樹�,二叉樹屬性選擇任然滿足不純度最小原則,不純度公式為
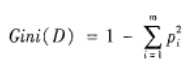
B���、應(yīng)用BOOTSTRAP自助法在員數(shù)據(jù)集中有放回地隨機(jī)抽取K個(gè)樣本集����,組成K顆決策樹����,而對(duì)于未被抽取的樣本用于決策樹的預(yù)測(cè);
C��、根據(jù)K個(gè)決策樹組成的隨機(jī)森林對(duì)待分類樣本進(jìn)行分類或者預(yù)測(cè)�����,分類的原則是投票法,預(yù)測(cè)的原則是簡(jiǎn)單平均����。
想象組合分類器中每個(gè)分類器都是一顆決策樹,因此分類器的集合就是一個(gè)“森林”�����,使用CART算法的方法來增長(zhǎng)樹�,樹增長(zhǎng)到最大的規(guī)模����,并且不剪枝,用這種方式形成的隨機(jī)森林稱為Forest-RI,數(shù)據(jù)分析師培訓(xùn)
另一種形式稱為Forest-RC,他不是隨機(jī)地選擇一個(gè)屬性子集�����,而是選擇一個(gè)屬性子集���,而是由已有的屬性的線性組合創(chuàng)建一些新屬性�����,就是由原來的S個(gè)屬性組合����,在給定的節(jié)點(diǎn),隨機(jī)選擇S個(gè)屬性����,并且以次歐諾個(gè)[-1,1]中隨機(jī)選取的數(shù)為系數(shù)相加���,產(chǎn)生S個(gè)線性組合�����,并在其中找到最佳的劃分�,僅僅只有少量屬性可用時(shí)�,為了降低個(gè)體分類器之間的相關(guān)性,這種形式的隨機(jī)森林才有用�����。
隨機(jī)森林的準(zhǔn)確率可以boosting媲美�����,隨機(jī)森林的泛化誤差收斂�,所以不存在過度擬合不是什么問題���;
R語言最后給我們常用randomForest包中的randomForest函數(shù)去建模;
randomForest (price~x1+x2,data=test_date)#這里只是舉例代碼并不能執(zhí)行�����;
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試��,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情���;
? 想學(xué)習(xí)CDA考試教材,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫����,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情;
? 想了解CDA考試含金量�,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330