這一年來����,數(shù)據(jù)科學(xué)家都用哪些算法
在“數(shù)據(jù)為王”的今天,越來越多的人對數(shù)據(jù)科學(xué)產(chǎn)生了興趣�����。數(shù)據(jù)科學(xué)家離不開算法的使用,那么�,數(shù)據(jù)科學(xué)家最常用的算法,都是哪些呢����?
最近,著名的資料探勘信息網(wǎng)站KDnuggets策劃了十大算法調(diào)查����,這次調(diào)查對數(shù)據(jù)科學(xué)家常用的算法進(jìn)行排名,并發(fā)現(xiàn)最“產(chǎn)業(yè)”和最“學(xué)術(shù)”的算法�,還對這些算法在過去5年間(2011~2016)的變化,做了一番詳細(xì)的介紹���。
這次調(diào)查結(jié)果,是基于844名受訪者投票整理出來����。
KDnuggets總結(jié)出十大算法及其投票份額如下:

圖1:數(shù)據(jù)科學(xué)家使用的十大算法和方法。
請參閱文末的所有算法和方法的完整列表�。
從調(diào)查中得知,受訪者平均使用8.1個(gè)算法�,與2011年的一項(xiàng)類似調(diào)查相比大幅提高。
與用于數(shù)據(jù)分析/數(shù)據(jù)挖掘的2011年投票算法相比,我們注意到流行的算法仍然是回歸算法���、聚類算法���、決策樹和可視化。相對來說最大的增長是以(pct2016/pct2011-1)測定的以下算法:
Boosting����,從2011年的23.5%至2016年的32.8%,同比增長40%
文本挖掘���,從2011年的從27.7%至2016年的35.9%�����,同比增長30%
可視化��,從2011年的從38.3%至2016年的48.7%���,同比增長27%
時(shí)間序列分析,從2011年的從29.6%至2016年的37.0%�����,同比增長25%
異常/偏差檢測,從2011年的從16.4%至2016年的19.5%����,同比增長19%
集合方法,從2011年的從28.3%至2016年的33.6%��,同比增長19%
支持向量機(jī)���,從2011年的從28.6%至2016年的33.6%����,同比增長18%
回歸算法���,從2011年的從57.9%至2016年的67.1%���,同比增長16%
在2016年最受歡迎的新算法是:
K-近鄰算法(K-nearest neighbors,KNN)����,46%份額
主成分分析(Principal Commponent Analysis���,PCA)��,43%
隨機(jī)森林算法(Random Forests��,RF)����,38%
最優(yōu)化算法(Optimization),24%
神經(jīng)網(wǎng)絡(luò)-深度學(xué)習(xí)(Neural networks-Deep Learning)����,19%
奇異值矩陣分解(Singular Value Decomposition,SVD)���, 16%
跌幅最大的算法分別為:
關(guān)聯(lián)規(guī)則(Association rules)����,從2011年的28.6%至2016年的15.3%�����,同比下降47%
增量建模(Uplift modeling)���,從2011年的4.8%至2016年的3.1%�����,同比下降36%
因子分析(Factor Analysis)���,從2011年的18.6%至2016年的14.2%�,同比下降24%
生存分析(Survival Analysis)�,從2011年的9.3%至2016年的7.9%,同比下降15%
下表顯示了不同算法類型的用途:監(jiān)督學(xué)習(xí)��、無監(jiān)督學(xué)習(xí)�、元分析和其他算法類型。我們排除了NA(4.5%)和其他(3%)的算法����。
表1:按行業(yè)類型的算法使用
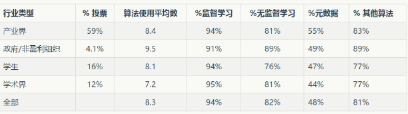
我們注意到,幾乎所有人都在使用監(jiān)督學(xué)習(xí)算法���。政府和產(chǎn)業(yè)的數(shù)據(jù)科學(xué)家們比學(xué)生或?qū)W術(shù)界使用了更多的不同類型的算法��,產(chǎn)業(yè)數(shù)據(jù)科學(xué)家更傾向使用元算法�����。
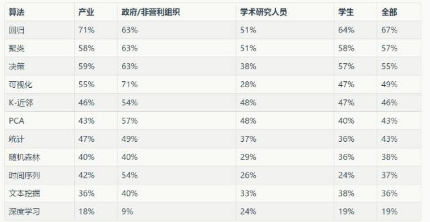
接下來���,我們分析深度學(xué)習(xí)的十大算法按行業(yè)類型的使用。
表2:深度學(xué)習(xí)的十大算法按就業(yè)類型的使用
Table 2: Top 10 Algorithms + Deep Learning usage by Employment Type
為了使差異更為醒目��,我們計(jì)算特定行業(yè)類型相關(guān)的平均算法使用量設(shè)計(jì)算法為Bias(Alg,Type)=Usage(Alg,Type)/Usage(Alg,All)-1����。
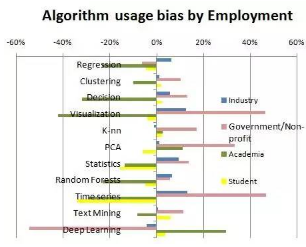
圖2:按行業(yè)的算法使用偏差
我們注意到產(chǎn)業(yè)界數(shù)據(jù)科學(xué)家更傾向使用回歸算法、可視化����、統(tǒng)計(jì)算法、隨機(jī)森林算法和時(shí)間序列�。政府/非盈利組織更傾向使用可視化、主成分分析和時(shí)間序列���。學(xué)術(shù)研究人員更傾向使用主成分分析和深度學(xué)習(xí)����。學(xué)生通常使用算法較少�����,但他們用的更多的是文本挖掘和深度學(xué)習(xí)����。
接下來�����,我們看看代表整體KDnuggets訪客的地區(qū)參與情況���。
參與投票者的地區(qū)分布如下:
北美,40%
歐洲���,32%
亞洲8%
拉美����,5.0%
非洲/中東��,3.4%
澳洲/新西蘭��,2.2%
與2011年的調(diào)查一樣�����,我們將產(chǎn)業(yè)/政府合并為同一個(gè)組�����,將學(xué)術(shù)研究人員/學(xué)生合并為第二組,并計(jì)算算法對產(chǎn)業(yè)/ 政府的“親切度”:
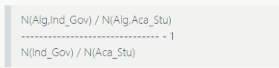
親切度為0的算法在產(chǎn)業(yè)/政府和學(xué)術(shù)研究人員/學(xué)生的使用情況相同�����。IG親切度約稿表示該算法越“產(chǎn)業(yè)”�����,越低則表示越“學(xué)術(shù)”�����。
其中最“產(chǎn)業(yè)”的算法”是:
增量建模(Uplift modeling)����,2.01
異常檢測(Anomaly Detection)�,1.61
生存分析(Survival Analysis),1.39
因子分析(Factor Analysis)���,0.83
時(shí)間序列(Time series/Sequences)����,0.69
關(guān)聯(lián)規(guī)則(Association Rules)��,0.5
雖然增量建模又一次成為最“產(chǎn)業(yè)”的算法,但出乎意料的是它的使用率如此低:區(qū)區(qū)3.1%�����,在這次調(diào)查中����,是使用率最低的算法。
最“學(xué)術(shù)”的算法是:
神經(jīng)網(wǎng)絡(luò)(Neural networks - regular)����,-0.35
樸素貝葉斯(Naive Bayes),-0.35
支持向量機(jī)(SVM)���,-0.24
深度學(xué)習(xí)(Deep Learning)���,-0.19
最大期望算法(EM),-0.17
下圖顯示了所有算法以及它們在產(chǎn)業(yè)界/學(xué)術(shù)界的親切度:
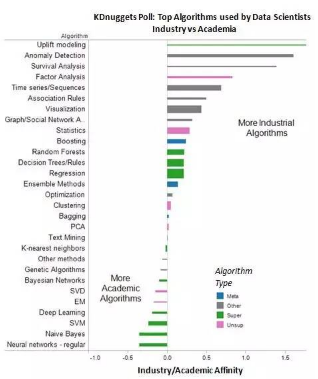
圖3:Kdnugets調(diào)查:數(shù)據(jù)科學(xué)家使用的流行算法:產(chǎn)業(yè)界vs學(xué)術(shù)界
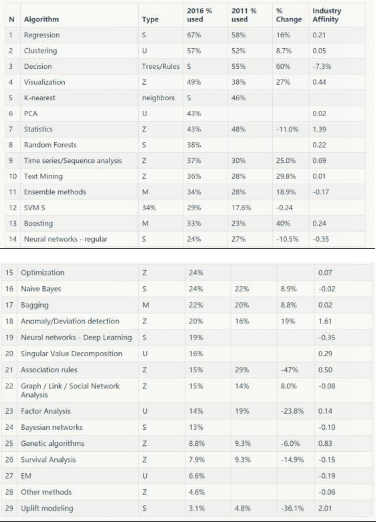
下表包含了算法的詳細(xì)信息���,在2016年和2011年使用它們的受訪者百分比調(diào)查�����,變化(%2016 /%2011 - 1)和行業(yè)親切度如上所述��。
表3:KDnuggets2016調(diào)查:數(shù)據(jù)科學(xué)家使用的算法
下表包含各個(gè)算法的詳細(xì)信息:
N: 根據(jù)使用度排名
Algorithm: 算法名稱
Type:類型����。S - 監(jiān)督,U - 無監(jiān)督���,M - 元��,Z - 其他,
2016 % used:2016年調(diào)查中使用該算法的受訪者比例
2011 % used:2011年調(diào)查中使用該算法的受訪者比例%Change:變動(dòng) (%2016 / %2011 - 1)
Industry Affinity:產(chǎn)業(yè)親切度(上文已提到)
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試�,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情;
? 想學(xué)習(xí)CDA考試教材��,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫�,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情;
? 想了解CDA考試含金量�,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330